Шаблоны
14.2.1.3. Стратегия обработки запроса
В "RDF" , "RDF", рассказывалось, что множество фактов может быть представлено одним из трех способов: как простое неструктурированное множество, как сложная, похожая на граф структура, либо как простое множество, имеющее подмножества, отмеченные RDF контейнерами, такими, как <Seq>. Mozilla использует комбинацию RDF графа (второй способ) и контейнеров (третий способ) для выполнения запросов.
С точки зрения прикладного программиста, Mozilla использует "бурящий" (drill-down) алгоритм для обработки запросов. Этот алгоритм эквивалентен стратегии перебора дерева "сначала вниз". Он требует, чтобы запрос начинался с чего-то известного, это называется корень дерева. На практике начальная точка запроса в Mozilla должна быть либо подлежащим факта, либо дополнением. Она всегда имеет форму URI (URL или URN).
Когда начальная точка выбрана, процессор запроса Mozilla двигается из нее по графу RDF фактов. Каждый факт эквивалентен переходу по одной стрелке (предикату или свойству) графа. Таким образом, в запросе на массиве трех фактов процессор выполнит лишь три шага из начальной точки вглубь графа.
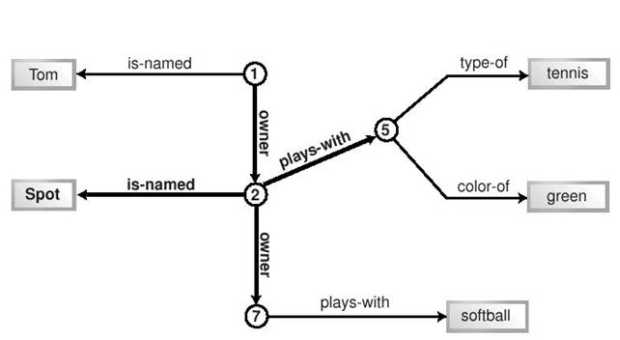
Систему запросов можно проиллюстрировать RDF графом. Вернемся к примеру с мальчиком и собакой. На этот раз пес Спот обнаруживает, что он может играть сам по себе. Оказывается, он владеет тряпочкой, причем абсолютно единолично. На Рисунке 14.3 показан граф, отображающий эти дополнительные факты, причем текущий запрос выделен жирными стрелками.
На рисунке 14.3 все факты принадлежат списку фактов. Иллюстрируемый запрос состоит из двух фактов (two-fact query) и начинается с идентификатора Тома, то есть единицы (1). Запрос звучит примерно так: "С какими предметами могут играть собаки Тома"? Жирными стрелками выделены крайние в графе факты, факты-термины, которые запрос обнаруживает - запрос из двух фактов должен проходить ровно две стрелки. Светлые линии запросом не достигаются. Этот запрос сначала получает три решения. Каждое соответствует уникальному пути, начинающемуся с идентификатора (1): путь 1-2-Спот, путь 1-2-7 и путь 1-2-5. Уточняя запрос, мы можем потребовать, чтобы у первого факта сказуемым было "владеть" (собака принадлежит Тому) а у второго - "играть с". В этом случае путь 1-2-Спот больше не решение. И будут обнаружены в точности два оставшихся: "Собака Тома Спот играет с тряпочкой" и "Собака Тома Спот играет с теннисным мячом".
Мы можем поэкспериментировать немного с этим примером.

На Рисунке 14.4 показан другой запрос на том же графе.
Снова мы имеем запрос из двух фактов, но на этот раз он начинается с идентификатора Спота (2). Снова три решения. Заметим, что путь 2-1- Том не является решением. Потому что стрелка указывает в противоположную сторону. Вовсе не 2 - подлежащее факта, и 1 - дополнение, а наоборот. Запрос не может двигаться в обратном порядке. Но даже для возможных решений наш второй запрос все же вряд ли имеет смысл. Слишком разные обнаруживаются предикаты на этих путях. Если все же нужно найти в этом запросе смысл, лучше предположить, что либо реальные данные плохо описываются фактами, либо запрос был недостаточно хорошо продуман.
Минус этой системы в том, что не все факты из исходного списка просматриваются. Теоретически, система может пропустить некоторые решения. Но ее достоинство - скорость. На практике, если RDF факты аккуратно упорядочены, быстрого поиска из известного начала достаточно, чтобы найти все решения.
Этот "сверлящий" алгоритм - приближение. В реальности система шаблонов работает сложнее. Однако это достаточно хорошее приближение и рекомендуемая интерпретация способа работы системы шаблонов XUL.
Способ организации RDF документа, подходящего системе шаблонов - использование тегов <Seq>, <Bag> или <Alt>. Известная стартовая точка - либо URI, либо факт, содержащийся в контейнере. Затем запрос "бурит" контейнер, добывая нужные факты. Это - стратегия индексирования.
Листинги 14.5 и 14.6 показывают фрагмент RDF и соответствующий запрос.
<Description about="http://www.example.org/"> <NS:Owns> <Bag about="urn:test:seq"> <li resource="urn:test:seq:fido"/> <li resource="urn:test:seq:spot"/> <li resource="urn:test:seq:cerebus"/> </Bag> </NS:Owns> </Description> <Description about="urn:test:seq:fido" NS:Tails="0"/> <Description about="urn:test:seq:spot" NS:Heads="1"/> <Description about="urn:test:seq:cerberus" NS:Heads="3"/>Листинг 14.5. Пример фрагмента RDF для комплексного запроса.
NS в листинге 14.5 означает некоторое пространство имен, предположительно, объявленное в коде где-то ранее. Пространство имен должно иметь URI наподобие www.test.com/#Test. Листинг 14.6 использует пространство имен NS для идентификации экземпляров фактов, эквивалентных применяемым в листинге 14.5. Использование NS в листинге 14.6 не имеет никакого конкретного смысла, поскольку факты в этом листинге не являются ни XML, ни кодом вообще.
<- http://www.example.org/, NS:Owns, ?bag -> <- ?bag, ?index, ?item -> <- ?item, NS:Heads, ?heads ->Листинг 14.6. Пример RDF запроса для бурения RDF контейнера.
В запросе первый обосновываемый факт спускается (drills down) до факта RDF с подлежащим bag ( bag - неупорядоченное мультимножество, допускающее повторение элементов), т.е. до строки <Bag about="urn:test:seq"> ). Второй обосновываемый факт спускается далее до элементов множества bag (множество из трех элементов <li resource= ...). Третий факт спускается до фактов о количестве голов у каждого элемента (в результате ноль или один ответ на каждую строку запроса, в зависимости от наличия головы у элемента множества (Фидо - ноль хвостов, Спот - одна голова, Цербер - три головы). В конечном результате обнаруживаются два решения. Множество обосновываемых переменных выглядит так:
<- ?bag, ?index, ?item, ?heads ->
а два найденных решения так:
<- urn:test:seq, rdf:_2, urn:test:seq:spot, 1 -> <- urn:test:seq, rdf:_3, urn:test:seq:cerberus, 3 ->
Вспомним, что RDF автоматически назначает имена предикатов, начинающиеся с rdf:_1,каждому потомку в контейнере. Первый потомок не обнаруживается запросом, поскольку третий из фактов запроса не приложим к факту с NS:Tails вместо NS:Heads.
Поддержка такого типа запросов - первоочередной приоритет системы запросов Mozilla. Это самый надежный и плодотворный способ работы с системой шаблонов.
В предыдущем примере переменная ?index использовалась для описания предиката факта. Система запросов Mozilla не может использовать переменную в запросе для предиката, но она имеет тег <member>, который достигает почти той же цели (с некоторыми ограничениями).
Итак, набор фактов запроса обнаруживает подходящие записи в аккуратно упорядоченной коллекции и строит RDF граф, начиная с некоторой известной точки.
14.2.1.4. Сохраняемые запросы
Запросы XUL шаблона живут столько же, сколько и содержащий их документ. Они не запускаются однажды, а затем отбрасываются. Они используются, пока не закроется их отображающее окно.
Список RDF фактов (возможно, загружаемый из файла) может затем модифицироваться, поскольку хранится в памяти. Факты могут добавляться в список, изменяться или удаляться из списка. Можно запрашивать систему шаблонов об этих изменениях.
Когда данные изменяются, каждый запрос шаблона также меняет свое мнение о том, какие существуют решения этого запроса. Если новые решения возможны, они будут добавлены ко множеству решений. Если некоторые решения стали невозможны, они будут удалены. Возможны и изменения в ранее найденных решениях.
Ближайшее следствие этого - то, что множество решений может со временем изменяться. Шаблонный запрос - не всегда "событие согласованного чтения" (если использовать жаргон RDBMS). Это живые, активно изменяющиеся "списки событий" (если говорить на телеметрическом жаргоне).
Живой отклик запроса требует от прикладного программиста некоторой активности. Ведь запрос должен непрестанно сверяться со списком фактов, чтобы решения были актуальны. Чтобы это делалось эффективно, и только тогда, когда нужно, должны быть написаны определенные скрипты.
XUL документы используют шаблонные запросы повсеместно.
14.2.1.5. Рекурсивные запросы
Бурящую стратегию шаблонных запросов Mozilla можно применять рекурсивно. Каждую конечную точку бурения можно использовать как следующую начальную точку для того же самого запроса. Это позволяет запросу продвигаться глубже по RDF-графу данных и, возможно, найти новые решения. Только когда новых решений не обнаруживается, мы достигаем конца рекурсии.
Рекурсивное использование запросов очень плодотворно на древообразных структурах данных. Такие структуры могут иметь произвольную глубину, что соответствует произвольному числу связей в RDF графе. Без рекурсии это невозможно, потому что глубина просмотра запроса равна числу фактов запроса.
В XUL документе шаблонные запросы внутри тега <tree> выполняют и добавочную работу.
14.2.1.6. Списки запросов
Система запросов Mozilla позволяет объединить несколько запросов в список.
Когда начинается обработка запросов, все запросы списка обрабатываются одновременно. Любое решение, удовлетворяющее сразу нескольким запросам, будет поставлено в соответствие лишь одному. А именно - ближайшему к началу списка.
Метод, которым это достигается, прост: на каждом шагу вниз по RDF- графу процессор запроса сверяется со списком запросов, уже частично обоснованных к данному моменту, и пытается обосновать их вновь обнаруженным фактом. Остальные запросы игнорируются. Когда процессор достигает дна графа, остаются лишь запросы, обоснованные найденными фактами.
Такая система позволяет оценить ряд фактов одним набором критериев (одним запросом), а если решение найти не удалось, вновь оценить другим набором критериев (другим запросом). Это очень похоже на булевские условные выражения if ... else if.
Списки запросов в Mozilla позволяют порождать несколько различных подмножеств одного множества фактов. Каждый запрос порождает одно такое множество решений.
На этом мы закончим рассмотрение запросов шаблона. После выполнения запроса нужно обработать найденные решения.
14.2.2. Порождение XUL-контента
В обычном случае все, что XUL шаблон делает с полученными данными - это выводит их на экран.
Шаблон делает это, совмещая полученные данные с обычным XUL- контентом. Он действует так же, как программа для печати информации в наглядной форме, или заготовка для написания отчета, "рыба". Выводимые данные интегрируются в XUL-документ и выводятся на экран, как любой иной XUL-контент.
Если шаблон содержится в теге XUL, таком как <menupopup>, <listbox>, <toolbar>, <tree> или даже <box>, то контент тега XUL (элементы меню, кнопки панели инструментов, строки списка или дерева) могут порождаться шаблоном. Это означает, что сами интерактивные интерфейсы могут описываться RDF файлом, а не кодироваться вручную.
Проиллюстрируем процесс такого порождения простым примером. В листинге 14.7 - RDF файл, содержащий два факта в контейнере. Каждый факт имеет единственную пару свойство/значение. Такие пары обычно - самая интересная часть RDF документа, и они обычно выводятся на экран как XUL-контент.
<?xml version="1.0"?>
<RDF xmlns:Test="http://www.test.com/Test#"
xmlns="http://www.w3.org/1999/02/22-rdf-syntax-ns#">
<Description about="urn:test:top">
<Test:TopSeq>
<Seq about="urn:test:seqroot">
<li resource="urn:test:message1"/>
<li resource="urn:test:message2"/>
</Seq>
</Test:TopSeq>
</Description>
<Description about="urn:test:message1" Test:Foo="foo"/>
<Description about="urn:test:message2" Test:Bar="bar"/>
</RDF>
Листинг
14.7.
Простой RDF документ, иллюстрирующий выводимый на экран XUL-контент.
Два свойства могут быть извлечены из этого файла и выведены на экран с помощью шаблона. Рисунок 14.5 показывает два набора сгенерированного XUL-контента из данного RDF файла. Это требует двух шаблонов в одном XUL-документе.
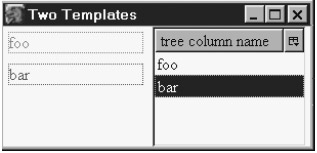
На снимке оба шаблона располагаются бок о бок. Мы видим конечный результат процесса порождения XUL контента. Шаблон слева генерирует теги <description> с рамками, заданными стилем. Теги находятся в теге <vbox>. Шаблон справа генерирует теги <treeitem>, каждый из них содержит <treerow> и <treecell>. Все они находятся в тегах <tree> и <treechildren>. Очевидно, что содержание, извлеченное из RDF файла, одинаково в обоих случаях, но структура, внешний вид и способ использования различны. Например, строки дерева могут быть выбраны пользователем, а строки текста слева - нет.
В итоге можно сказать, что шаблоны объединяют данные, полученные в результате обработки запроса, с иным контентом, определяющим, как эти данные должны быть представлены.
14.2.2.1. Шаблоны и поддеревья контента
Теги XUL, относящиеся к системе шаблонов, не отражены в конечном, видимом документе. Отображены теги, генерируемые системой. Оба типа тегов присутствуют в XUL документе одновременно, но теги шаблонов имеют такие стили, что не отображаются.
Теги шаблона формируют одно DOM поддерево XUL документа. После того, как шаблон генерирует свой контент, эти теги могут использоваться только для ссылок. Система шаблонов может перечитать такой тег, если прикладной программист добавит соответствующий скрипт.
Сгенерированные теги формируют поддерево DOM для каждого решения, найденного шаблонным запросом. Три решения дадут три поддерева. Эти поддеревья скажутся при любом обращении к ним пользователя или события, вызванного скриптом.
Каждое из сгенерированных поддеревьев имеет тег верхнего уровня. Этот тег получит уникальный id атрибут, равный URI подлежащего факта, найденного запросом. Этот id используется как уникальный ключ для идентификации каждого поддерева.
Пример "hello, world", приводившийся в начале лекции, показывает эти поддеревья на снимке.
14.2.2.2. Динамический контент
Шаблоны могут изменяться во время работы. Генерируемый ими контент тоже может меняться. Оба эффекта требуют применения JavaScript, и оба могут требовать очередного выполнения шаблонного запроса. Шаблоны могут и задерживать результат ("ленивое" порождение контента).
Для пересчета шаблона необходима одна строка на JavaScript. Не нужно перегружать никаких документов. Часть XUL документа, содержащая шаблон, и результат его работы изменяются "на лету". Окружающий контент не будет затронут, за исключением, возможно, оформления. Вот типичная строчка, выполняющая эту работу:
document.getElementByTagName('tree').builder.rebuild();Теги шаблона также можно изменять, используя операции DOM 1, такие как removeChild() и appendChild(). Однако если так сделать, выведенное на экран содержание будет изменено при пересчете шаблона.
Если шаблон не изменит результатов запроса, выведенное на экран содержание все равно изменится, когда изменятся RDF данные, которые использует шаблон. Если шаблон будет пересчитан, появится новый контент, соответствующий новым решениям, а контент, соответствующий старым решениям, исчезнет. Система шаблонов сама вносит эти изменения, используя операции DOM 1.
XUL документы не только задействуют шаблоны повсеместно, но и могут использовать их вновь и вновь в любое время.
14.2.2.3. Отложенное ("ленивое") порождение контента
Порождение контента может быть отложено. Это возможно только для рекурсивных запросов. Когда используются рекурсивные запросы, ищутся лишь решения верхнего уровня. На их основании строится контент. Позже, если приходит сигнал от пользователя или платформы о том, что требуется еще порция контента, ищутся очередные решения. Затем новые решения добавляются к тем, что были выведены на экран ранее.
"Ленивое" вычисление работает, только если теги шаблона, имеющие атрибут uri - следующие:
<menu> <menulist> <menubutton> <toolbarbutton> <button> <treeitem>
Дочерние теги этих тегов, такие как тег <menu> в <menulist> строятся "лениво".
Шаблоны, использующие <tree> или <menu>, могут откладывать часть работы на более позднее время.
14.2.2.4. Разделяемый контент
Два или большее количество шаблонов могут использовать одни и те же RDF данные. Если RDF данные изменяются, эти изменения отображаются во всех шаблонах одновременно. Чтобы изменения отобразились, шаблоны должны быть пересчитаны. Каждый шаблон работает как некий обозреватель RDF данных.
Это очень мощное и полезное свойство шаблонов. Оно позволяет по- разному взглянуть на одно и то же множество данных одновременно, и при этом своевременно отображать изменения. Это используется, в частности, в тех приложениях, где применяется метафора рабочего стола. Например, в дизайнерских инструментах или Integrated Development Environments (IDE). Эти приложения должны визуализировать данные для пользователя несколькими способами одновременно. Это свойство также используется в классической Mozilla в системе закладок, адресной книге и кое-где еще.
Чтобы увидеть эффект одновременного изменения контента в нескольких шаблонах, выполним следующий тест:
- Запустим классический Браузер, чтобы появилось окно Навигатора.
- Убедимся, что Personal Toolbar и Navigation Toolbar видимы (View | Show/Hide).
- Создадим закладку на Персональной панели инструментов, перетаскивая любой URL на эту панель мышкой (перетаскивайте иконку слева от строки адреса).
- Откроем окно Менеджера Закладок (Bookmarks | Manage Bookmarks).
- Убедимся, что новая закладка видна одновременно в Менеджере закладок и на Персональной Панели.
- Удалим новую закладку в Менеджере Закладок, выбрав "удалить" в контекстном меню.
- Новая закладка исчезнет с панели инструментов и из менеджера закладок одновременно.
Менеджер Закладок содержит шаблон, основанный на теге <tree>. Персональная Панель инструментов - на теге <toolbar>. Элемент меню "Уничтожить" запустит скрипт, который уничтожит факт, содержащий информацию о новой закладке. Этот же скрипт предписывает обоим шаблонам пересчитать содержание. Части контента, ассоциируемые с этим уничтоженным фактом, ( <treeitem> в одном случае, и <toolbarbutton> в другом) исчезнут из списка найденных результатов.
14.2.3. Доступ с помощью JavaScript
Система шаблонов добавляет объекты к AOM XUL-документа. Она использует также несколько XPCOM компонентов и интерфейсов, в частности, RDF. Ими можно управлять из JavaScript. JavaScript может выполнять следующие задачи:
- Задействовать свойство database AOM-объекта, управляя фактами и исходными RDF данными, используемыми шаблоном.
- Использовать свойство builder AOM-объекта, управляя процессом построения шаблона.
- Создавать снимок шаблона по запросу.
- Заполнять шаблон фактами, если у него нет начальных.
- Добавлять теги-наблюдатели в систему шаблонов.
- Управлять сортировкой <tree> - и <listbox> -образных шаблонов.
- Использовать стандарты DOM 1 для модификации тегов шаблона (иногда это возможно) или тегов, сгенерированных шаблоном (что вряд ли разумно).
Эти задачи будут описаны в разделе "Скриптинг". Они часто требуют работы с компонентами XPCOM, поддерживающими RDF. Эти компоненты обсуждаются в "Объекты XPCOM" , "Объекты XPCOM".
14.2.4. Источники данных
Последний технический аспект шаблонов - источники данных.
Данные RDF, используемые шаблоном, могут извлекаться из обычного RDF документа или порождаться самой платформой. В любом случае, между шаблоном и реальным источником RDF фактов находится объект, называемый "источником данных".
Шаблоны Mozilla могут извлекать факты из более чем одного источника одновременно. Это значит, что, например, факты из более чем одного RDF файла могут вносить свою лепту в контент, генерируемый шаблоном. Это связь типа многие-со-многими между источниками данных и шаблоном.
Источники данных подробно рассматриваются в "Объекты XPCOM" , "Объекты XPCOM". Здесь же мы только отметим, что выбор источника данных для шаблона критичен. Если неправильно выбрать источник, вряд ли будет много толку. Необходимо знать свои источники данных.
Вот краткий обзор основных моментов. Каждый шаблон имеет комплексный источник данных. Чтобы воздействовать на источник данных шаблона из скрипта, зачастую необходимо найти и использовать один из конкретных источников данных, вносящих свой вклад в результирующий комплексный источник. Этот конкретный источник - список RDF фактов. В принципе, возможен полный набор операций, напоминающих операции с базами данных. Практически же полезны лишь источники данных из RDF файлов и система закладок. Система закладок имеет тот недостаток, что ее код нечитаем. Из других внутренних источников данных одни читаются легко, другие нет. Чтобы начать с пустого множества фактов и заполнять его вручную, удобно начинать с источника данных rdf:null. Так часто поступают, когда конструируют пользовательский снимок дерева данных.
Раздел этой лекции, посвященный скриптам, описывает некоторые распространенные манипуляции с источниками данных. Рекомендуется изучить также "Объекты XPCOM" , "Объекты XPCOM".