RDF
11.3.3 Три способа организации фактов
К настоящему моменту мы выработали подходящую структуру для описания факта. Какими же способами можно хранить ее в компьютере? Существует несколько вариантов.
Первый способ – хранить факты как набор независимых элементов. В реляционной СУБД этому соответствуют отдельные записи в таблице с тремя полями; в объектной технологии – коллекция элементов (например, set или bag ). Запись в листинге 11.5 соответствует такому подходу.
Этот простой подход очень гибок. В любой момент можно добавить новые факты или удалить существующие. Не нужно поддерживать никакой внутренней структуры. Такое решение можно сравнить с обычным ведром – при необходимости вы просто "наливаете" в него факты или "выливаете" их.
Одно из главных преимуществ "ведра с фактами" – легкость объединения фактов из разных источников. Вы просто "наливаете" их в ведро, получая в результате одну большую коллекцию фактов. Когда вы обращаетесь к ней, все факты имеют одинаковый статус независимо от происхождения. Это просто объединение двух множеств.
Второй подход к хранению фактов основан на признании того, что между отдельными фактами существуют связи, образующие некую структуру. Она может храниться как традиционная структура данных, в которой связи между кортежами будут представлены указателями или ссылками. Поскольку связи могут носить произвольный характер, эту структуру следует рассматривать как граф, а, скажем, не как список или дерево. Именно граф является наиболее общим способом представления взаимосвязанных данных. Графы имеют ребра (линии) и вершины (узлы, пересечения ребер). И ребра, и вершины могут быть именованными. Граф можно и изобразить на рисунке. На рисунке 11.1 показаны связи между фактами, приведенными в листинге 11.5.
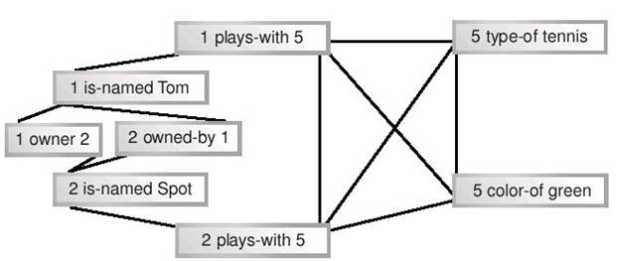
Пожалуй, это слишком сложная схема для простой системы, состоящей из мальчика, собаки и мяча. Более того, на ней недостает некоторых линий – нам следовало бы добавить еще три связи между фактами, содержащими "1" и три связи между фактами, содержащими "2", доведя их общее число до 18. Чтобы сделать схему менее громоздкой, добавим к ней вершины, вынеся идентификаторы из кортежей. Измененная схема, на которой осталось всего 12 ребер, показана на рисунке 11.2.
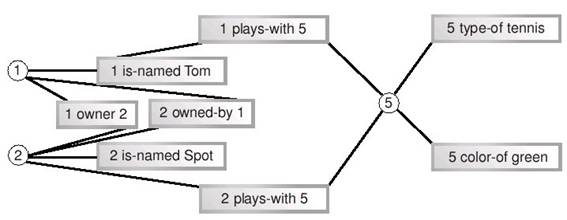
Наш подход – выделение элементов из кортежей – позволил несколько упростить схему, поэтому продолжим двигаться в том же направлении. Мы можем не только выделить идентификаторы, но и разбить все триплеты на отдельные термы. Более того, можно заметить, что некоторые кортежи являются взаимно обратными, выражающими две стороны одного и того же отношения (в нашем примере – "хозяин" и "принадлежит"). Мы можем избежать такого дублирования информации, сделав ребра нашего графа направленными. Двигаясь по стрелке, мы получаем один предикат, двигаясь против стрелки – обратный ему. Результат всех этих усовершенствований показан на рисунке 11.3.
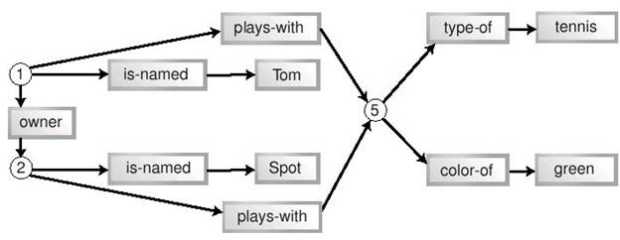
Наконец, мы можем заметить, что каждый предикат имеет ровно одну входящую и одну исходящую стрелки. Поэтому мы можем превратить предикаты в именованные стрелки (ребра), освободив граф от избыточных узлов (вершин). Результат этой процедуры показан на рисунке 11.4, на котором также изменено расположение некоторых элементов.
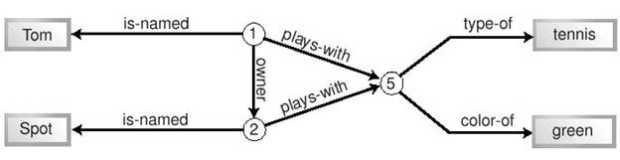
На этом рисунке ясно видны отношения, выражаемые предикатами, и их характер. Существуют второстепенные предикаты, которые служат лишь для описания идентификаторов (имя, цвет, тип), и более важные предикаты (хозяин, играет-с), содержащие информацию об отношениях между интересующими нас идентификаторами. Таким образом, решения использовать идентификаторы для каждого моделируемого объекта реального мира (см. листинги 11.1 и 11.2) и выделить идентификаторы на схеме (см. рисунок 11.2) оказались продуктивными. Как мы видим, идентификаторы играют важнейшую роль в построении компактной и выразительной схемы.
Граф на рисунке 11.4 соответствует официальной нотации RDF для графов. Круги и эллипсы изображают идентификаторы, а прямоугольники – литералы. В усовершенствовании нуждается система имен идентификаторов и предикатов. В качестве идентификаторов могут использоваться URL – вскоре мы обсудим этот вопрос.
Данные RDF, представленные в форме графа, позволяют программам обработки фактов двигаться от одного факта к другому, выбирая ребра для перехода в зависимости от конкретной задачи.
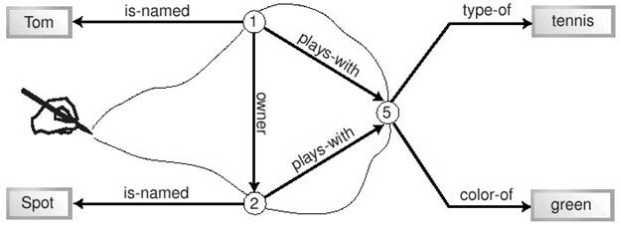
Наконец, существует третий способ организации фактов, часто используемый в RDF-документах Mozilla. Представьте себе, что факты беспорядочно рассыпаны по кухонному столу. Возьмите воображаемую иголку с ниткой и пропустите нитку через термы, имеющие отношение к определенной теме. Теперь, если понадобится информация по этой теме, достаточно потянуть за нужную нитку, и можно выбрать все термы и связанные с ними факты, относящиеся к теме. На рисунке 11.5 показана воображаемая линия, которая соединяет все идентификаторы на нашем графе.
RDF не располагает синтаксисом для построения таких линий. Однако нужный результат может быть достигнут при помощи специальных тегов RDF, называемых контейнерами. Поскольку RDF может представлять только факты, контейнеры содержат факты. Любой терм любого факта может быть включен в один или несколько контейнеров. Чаще всего для этого используется субъект. Другие термы факта хранятся обычным образом. Рисунок 11.6 повторяет рисунок 11.5, однако вместо линии на нем показан контейнер, причем факт принадлежности к нему изображен на схеме наряду с прочими фактами.
Контейнер представлен на схеме термом с соответствующей подписью. Единственное, что отличает факт принадлежности к контейнеру от прочих фактов – способ именования предикатов. Любой предикат, выражающий принадлежность терма к контейнеру, автоматически получает в качестве имени порядковый номер. В отличие от условных номеров, заменяющих на схеме идентификаторы субъектов и объектов, нумерованные предикаты действительно используются в синтаксисе контейнера RDF.
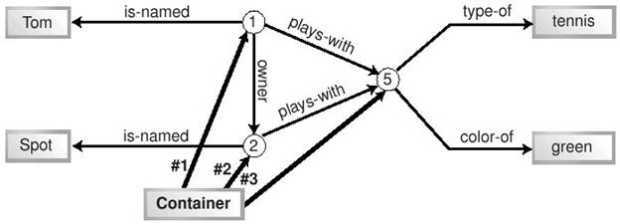
Контейнеры представляют собой простой механизм структурирования данных. Они также поддерживают запросы к коллекциям фактов. Разработчик приложения может использовать контейнер в качестве частичного индекса, итератора или реляционного представления. Любой документ RDF может иметь неограниченное количество контейнеров.
Итак, факты могут храниться в виде простого набора триплетов или сложного графа, организованного вокруг идентификаторов. Между этими полюсами находится частичная структура, задаваемая контейнером, которую можно сравнить с маршрутом, нарисованным на карте. Набор фактов называется хранилищем фактов. Сложные хранилища фактов называются базами знаний, подобно тому, как хранилище данных называется базой данных. Простые документы RDF являются хранилищами фактов; документы, включающие схему RDF, являются базами знаний.