Опубликован: 28.09.2007 | Доступ: свободный | Студентов: 6201 / 1049 | Оценка: 4.20 / 4.10 | Длительность: 47:32:00
ISBN: 978-5-94774-707-2
Лекция 2:
Транспортные протоколы Интернет
Главной целью алгоритма RED является исключение ситуации, когда несколько ТСРпотоков перегружаются почти одновременно и затем синхронно начинают процедуру восстановления.
Интересное предложение относительно выборочного (приоритетного) отбрасывания пакетов содержится в работе [2.36] в отношении мультимедиа-потоков.
Алгоритм RED позволяет организовать очереди таким образом, что их размер отслеживает осцилляции величины RTT.
RED пытается увеличить число коротких перегрузок и избежать долгих.
Задача RED заключается в том, чтобы сообщить отправителю о возможности перегрузки, и отправитель должен адаптироваться к этой ситуации.
Существует модификация алгоритма обработки очередей WRED (Weighted Random Early Detection), широко используемая в маршрутизаторах. Этот алгоритм применяется и при реализации DiffServ и гарантированной переадресации (AF), когда решение об обработке пакета принимается в каждом транзитном узле независимо (PHB). При этом может учитываться код DSCP IP-заголовка.
Алгоритм WRED удобен для адаптивного трафика, который формируется протоколом ТСР, так как здесь потеря пакетов приводит к снижению темпа их передачи отправителем. Алгоритм WRED присваивает пакетам не IP типа нулевой приоритет, повышая вероятность потери таких пакетов. Имеется возможность конфигурации DWRED и DWFQ для одного и того же интерфейса.
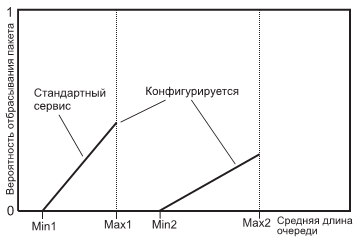
WRED полезен для любого выходного интерфейса, где ожидается перегрузка. Когда приходит пакет, вычисляется среднее значение длины очереди. Если вычисленное значение меньше минимального порога очереди, приходящий пакет ставится в очередь. Если вычисленное значение лежит между минимальным порогом очереди для данного типа трафика и максимальным порогом для интерфейса, пакет ставится в очередь или отбрасывается, в зависимости от вероятности отброса, установленной для данного типа трафика. И, наконец, если размер очереди больше максимального порога, пакет отбрасывается (см. рис. 2.12).
WRED статистически отбрасывает больше пакетов для сессий с большими потоками. По этой причине ТСР-отправители больших потоков будут вынуждены в большей степени понизить поток, чем отправители малого трафика.
Ни АТМ-интерфейсы маршрутизаторов, ни АТМ-коммутаторы не предоставляют гарантий QoS для UBR виртуальных каналов. Маршрутизатор CISCO может специфицировать только пиковую скорость передачи (PCR) для UBR-канала.
Маршрутизатор автоматически определяет параметры, которые нужно использовать в вычислениях WRED. Среднее значение длины очереди определяется на основе предыдущего значения и текущего размера очереди, согласно формуле:
Средняя длина очереди = (old_evarage 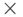 (1-2-n)) + (current_queue_size 2-n),
(1-2-n)) + (current_queue_size 2-n),
где n - экспоненциальный весовой фактор, конфигурируемый пользователем. В некоторых статьях о WRED значение 2n обозначается qw.
Большое значение n сглаживает пики и провалы длины очереди. Средняя длина очереди не будет меняться быстро. Процесс WRED не сразу начнет отбрасывать пакеты при перегрузке, зато продолжит отбрасывание, даже когда перегрузки уже нет (очередь уже сократилась ниже минимального порога). Когда n становится слишком большим, WRED не будет реагировать на перегрузку. Пакеты будут посылаться или отбрасываться так, как если бы WRED не работал.
Для малых значений n среднее значение длины очереди практически совпадает c текущей ее величиной, что вызывает значительные флуктуации среднего значения. В этом случае реакция WRED на превышение длины очереди становится практически мгновенной. Если значение n слишком мало, WRED чрезвычайно чувствителен к флуктуациям трафика, что может снижать пропускную способность.
Вероятность отбрасывания пакета зависит от минимального порога, максимального порога и маркерного деноминатора вероятности. Когда средняя длина очереди выше T1 (Min1, Min2 на рис. 2.12), RED начинает отбрасывать пакеты. Частота отбрасываний увеличивается линейно по мере роста длины очереди до тех пор, пока усредненный размер очереди не достигнет T2 (Max1 и Max2).
Маркерный деноминатор вероятности pc равен доле теряемых пакетов, когда средняя длина очереди равна T2. Например, если pc равен 1/512, один из 512 пакетов отбрасывается, когда средняя длина очереди достигает T2 (см. рис. 2.13 ниже). Когда длина очереди превышает T2, отбрасываются все пакеты. Минимальный порог T1 следует выбрать достаточно высоким, чтобы максимизировать использование канала.
Разница между T2 и T1 должна быть достаточно велика, чтобы избежать глобальной синхронизации ТСР агентов (синхронное изменение CWND).

В качестве альтернативы можно рассмотреть ситуацию, когда маршрутизатор осуществляет пометку пакетов с помощью битафлага СЕ (Congestion Experienced). Отправитель должен реагировать на этот флаг так, как если бы произошла потеря пакета. Этот механизм, называемый ECN (Explicit Congestion Notification), использует двухбитную схему оповещения, занимая биты 6 и 7 в поле ToS заголовка IPv4 (или два неиспользуемые бита в поле IP Differentiated Services). Бит 6 устанавливается отправителем с целью индикации того, что эта система совместима с ECN (бит ECN ). Бит 7 является СЕ-битом и устанавливается маршрутизатором, когда размер очереди превышает заданное при конфигурации значение. ECN-алгоритм реализует в маршрутизаторе RED. Когда какой-то пакет выбран, он помечается битом СЕ, если в нем установлен бит ECN, - в противном случае пакет отбрасывается.
Заметим, что механизмы управления очередями во многих случаях не будут работать, так как перегрузка происходит в сетевом устройстве (например, L2), которым вы управлять не можете.
Исходный диалог установления соединения ТСР при реализации данного алгоритма предполагает добавление возможности ECN-эха и CWR (Congestion Window Reduced) для уведомления партнера о возможности работы с СЕ-битом. Отправитель устанавливает бит ECN во всех посылаемых пакетах. Если отправитель получит ТСР-сегмент с флагом ECN-эхо, он должен подстроить ширину CWND в соответствии с алгоритмом быстрого восстановления при потере одиночного пакета. Следующий посланный пакет должен иметь CWRфлаг, оповещающий получателя о его реакции на перегрузку. Отправитель реагирует подобным образом, по крайней мере, один раз за время RTT. Далее ТСР-пакеты с установленным флагом ECN не вызывают никакой реакции в пределах интервала RTT. Получатель устанавливает ECN-флаг во всех пакетах, когда он получает пакет с установленным битом СЕ. Это продолжается до тех пор, пока он не получит пакет с флагом CWR, указывающим на реакцию отправителя на перегрузку. ECN-флаг устанавливается только в пакетах, которые содержат поле данных. Пакеты ТСР ACK, которые не имеют поля данных, должны содержать флаг ECN=0.
Соединение не должно ждать получения трех ACK, чтобы детектировать перегрузку. Вместо этого получатель уведомляется о зарождающейся ситуации перегрузки путем установления соответствующего бита, который в свою очередь вызывает соответствующий отклик. Широкое использование ECN в ближайшее время не ожидается, во всяком случае, в контексте IPv4. По этой причине не принято никакого стандарта для позиционирования соответствующих бит в IP-заголовке.
ECN предоставляет некоторое улучшение эксплуатационных характеристик канала по сравнению со схемой RED, в частности, для коротких ТСР-транзакций. Главной особенностью алгоритма ECN является необходимость изменения программ работы, как маршрутизатора, так и стека TCP/IP. Выгоды этого алгоритма могут стать заметными лишь при достаточно широком внедрении. Можно ожидать более быстрого по отношению ECN распространения алгоритма RED, так как он требует лишь локальной модификации программного обеспечения маршрутизатора.
Следует также помнить, что работа слишком тихоходной станции с малым объемом оперативной памяти в быстродействующей сети ухудшает характеристики обмена не только для нее, но и для соседей.
Оптимизировать виртуальный канал можно, если отправитель и получатель имеют исчерпывающую информацию о состоянии партнера и самого канала. К сожалению такой информации обычно нет. Получатель, например, не знает, находится ли отправитель в режиме медленного старта, исключения перегрузки или проходит стадию восстановления после перегрузки.
Другим подходом управления перегрузкой является использование откликов ACK для контроля поведения отправителя. Предпосылкой для такого решения является то, что путь трафика симметричен и устройство, где происходит перегрузка, может идентифицировать пакеты ACK, двигающиеся в противоположном направлении. Для такого подхода имеется две альтернативы.
ACK Pacing (прореживание). Каждый кластер пакетов будет генерировать соответствующий кластер откликов ACK. Расстояние между этими откликами определяет частоту следования пакетов в кластере. Для систем с большими временами RTT размер кластера может оказаться фактором, ограничивающим скорость передачи. Если вы можете замедлить скорость передачи, размер очереди в буфере может быть сокращен. Одним из подходов к снижению скорости передачи является увеличение периода следования ACK на выходе транзитного маршрутизатора. Такой подход может оказаться эффективным для каналов с большими задержками. Этот механизм предполагает, что информационные сегменты и отклики идут по тому же маршруту (но, естественно, в разных направлениях).
Манипуляция окном. Каждый пакет ACK несет в себе размер окна получателя. Такое окно определяет максимальный размер кластера, который может прислать отправитель. Манипулируя размером окна, можно регулировать скорость передачи.
Оба указанных механизма позволяют делать достаточно широкие предположения о GWсети. Главное предположение заключается в том, что в точке GW потоки симметричны. Оба механизма подразумевают, что GW может кэшировать статусные данные для каждого из потоков, так что RTT потока, текущее значение скорости передачи и размер окна получателя доступны контролеру услуг. Прореживание ACK предполагает также, что один ACK-отклик активен в любое время вдоль сетевого маршрута. Задержка ACK может привести к истечению времени таймаута у отправителя.
Если потеря из-за перегрузки происходит на ранней фазе медленного старта, в сети недостаточно пакетов, чтобы сгенерировать три дублированных ACKотклика для запуска быстрой повторной пересылки и быстрого восстановления. Вместо этого отправитель должен подождать таймаута RTO (минимальное время равно одной секунде). Для коротких сессий длиной (67) RTT ~ нескольких миллисекунд издержки, связанные с потерей одного пакета, слишком велики. Приблизительно 56% повторных передач осуществляется после таймаута RTO.
Возможным усовершенствованием данного алгоритма может быть механизм, называемый ограниченной передачей (Limited Transmit).
При реализации этого механизма налагаются два условия. Присланное получателем значение окна разрешает передачу данного сегмента, а часть данных остается за пределами окна перегрузки плюс порог двойного ACK, который используется для запуска быстрой повторной передачи. Второе условие предполагает, что отправитель может послать только два сегмента вне пределов CWND и делает это только в качестве отклика на удаление сегмента из сети.
Базовый принцип этой стратегии заключается в продолжении сигнального обмена между отправителем и получателем, несмотря на потерю пакета, увеличивающего вероятность того, что отправитель восстановится после потери, используя дублированные ACK и быстрый алгоритм восстановления и уменьшая шанс односекундного (или даже более) восстановления после RTO.
Ограниченная передача уменьшает также возможность того, что процедуры восстановления приведут к новым потерям пакетов.
Иногда возникают ситуации, когда приложение воспринимает управляющие функции ТСР слишком лимитирующими. Это может происходить, например, при управлении общедоступными коммутирующими телефонными сетями через Интернет. В таком варианте не требуется обеспечение строгой последовательности пакетов (отсутствие перепутывания порядка). Кроме того, ограниченное число TCP-сокетов усложняет поддержку приложений, использующих несколько сетевых интерфейсов, да и сам протокол ТСР уязвим для ряда атак, например, для SYN-шторма. Решение такого типа проблем возможно с привлечением протокола SCTP (Stream Control Transmission Protocol).
Основное отличие между SCTP и TCP проявляется на фазе инициализации, когда партнеры SCTP обмениваются списком оконечных адресов (IP-адресов и номеров портов), которые ассоциируются с текущей сессией. Стартовая процедура SCTP также отличается от традиционного диалога. Здесь получатель не выделяет никаких ресурсов для соединения, что делает процедуру более устойчивой против атак типа SYN-шторма. Инициатор соединения может, в конце концов, откликнуться, послав COOKIEECHO, куда вкладывается порция данных. Таким образом, информационный обмен начинается уже на фазе формирования виртуального соединения. С этого момента сессия считается открытой.
Закрытие сессии SCTP также отличается от ТСР. В SCTP закрытие сессии с одной стороны означает опустошение очередей и прекращение посылки данных с другой стороны. Здесь через одну и ту же ассоциацию транспортного уровня может осуществляться несколько обменов. Порядок сообщений в рамках одного обмена неукоснительно соблюдается. Каждый поток имеет однозначную идентификацию. Протокол SCTP поддерживает также доставку вне очереди, когда пакет помечается для немедленной доставки, и тогда он получает приоритет и будет доставлен раньше, чем это предписывалось его порядковым номером. Протокол SCTP требует предварительного выяснения значения MTU. таймер повторных передач, запускаемый при посылке каждого сегмента, предусмотрен в SCTP, как и в TCP. Получатель SCTP использует режим подтверждений SACK, реализуемый для каждого второго полученного сегмента. Если сообщение оказалось в зазоре между SACK, после трех таких откликов отправитель повторно посылает это сообщение и сокращает вдвое CWND.
Применение обменов точка-мультиточка предполагает, что каждый оконечный адрес, ассоциированный с одной и той же ЭВМ, не обязательно использует один и тот же путь. Поэтому для каждой конечной точки периодически должна производится проверка осуществимости связи (процедура keepalive ).
Идея совмещения состояния ТСР перегрузки для нескольких каналов применима и для смеси потоков с гарантией и без гарантии доставки, осуществляющих одновременно обмен между общими конечными пунктами. Именно такая схема мультиплексирования реализуется в модели менеджера перегрузки. Менеджер перегрузки представляет собой модуль оконечной системы, который позволяет набору одновременных потоков от ЭВМ к некоторой точке назначения совместно использовать общую систему управления перегрузкой.
Основной причиной для применения менеджера перегрузки послужило то, что наиболее критическим пунктом управления сетью является управление взаимодействием между ТСР потоками с контролем перегрузки и информационными UDP потоками. В крайних случаях такого взаимодействия каждый из классов трафика может отказывать в сервисе другому, оказывая достаточное давление на сетевые механизмы управления очередями и тем самым лишая этих ресурсов другой класс трафика. Ситуация достаточно типична, например для WEBсервера, который может организовать несколько виртуальных соединений для одного клиента и для разных классов трафика.
Реализация общей функции управления перегрузкой может базироваться на механизме отзыва (callback), когда приложение посылает запрос менеджеру перегрузки (МП). МП откликается посылкой отзыва, и приложение после этого может послать информационный сегмент протокольному драйверу.
Другой поддерживаемый механизм МП называется синхронной передачей. Здесь МП предоставляет приложению данные о состоянии канала (пропускная способность, RTT и т.д.) и оно может осуществить запрос, лишь когда состояние сети изменится существенным образом (пороги по базовым параметрам задаются при конфигурации). Удаленная ЭВМ информирует МП о числе полученных и потерянных байтов, о результатах измерения RTT, проведенных на уровне приложения. Приложение предоставляет информацию о причинах потерь (истечение таймаута, состояние транзитных сетей или отбрасывание на основе ECN-флагов).
В последнее время появилось достаточно много версий протокола "лучше чем ТСР", большинство из них предлагаются в комплекте с WEBсервером. Чаще всего это модифицированные версии ТСР - например, за счет таймера более высокого разрешения, позволяющего реагировать более быстро на изменения в сети. Некоторые версии предлагают большее стартовое значение CWND или более быструю версию медленного старта, где размер окна не удваивается, а утраивается на каждом из шагов (за RTT ). Сходные модификации могут быть использованы на фазе избежания перегрузки (линейный участок увеличения CWND ). Все эти модификации вынуждают отправителя вести себя более агрессивно, увеличивая давления на сетевые буферы. Возможно создание программ обмена, где, например, при копировании через сеть файла формируется не одно, а несколько виртуальных соединений. Такого рода решения дают выигрыш главным образом за счет ухудшения условий реализаций других одновременных сессий. Это противоречит общей философии Интернет (Интернет - это клуб джентльменов). Но на самом деле агрессивное поведение ТСР приложения в конечном итоге делает его неэффективным (менее эффективным, чем стандартный ТСР). Как правило, такие решения приводят к большим потерям пакетов, так как их усилия максимально загрузить ресурсы сети заканчиваются понижением чувствительности к сигналам перегрузки. Если же таких приложений в Интернет станет много, это приведет к серьезной деградации пропускной способности каналов из-за перегрузки. Приемлемыми усовершенствованиями ТСР можно признать только такие, которые не ухудшают условий работы для окружающих. Это наилучшая стратегия, так как позволяет использовать ресурсы сети более эффективно для всех участников.
Работа протокола TCP AIMD в режиме исключения перегрузок можно характеризовать формулой [2.1]:
![BW=
\frac{MSS}
{(RTT \times \sqrt{(1.33 \times p)}) + (RTO \times p \times [1+32 \times p^2] \times \min (1,3 \times \sqrt{0.75 \times p)})}](/sites/default/files/tex_cache/8aa1b59ad10c447482b2706d8dd5e46a.png)
где BW - полоса пропускания;
MSS - максимальный размер сегмента в байтах, используемый сессией;
RTO - таймаут повторной пересылки;
p - частота потери пакетов (0.01 означает 1% потерь)
Эта формула является наилучшей аппроксимацией. Некоторое упрощение формулы можно получить, считая RTO=5*RTT.
Еще более упрощенная формула может быть взята из работы [2.31].

Данные формулы выведены при следующих предположениях:
- Окно получателя не ограничивает рабочих характеристик соединения.
- Обе формулы позволяют полосе достигать бесконечности при нулевых потерях.
- Значение RTT является средним и включает в себя задержку, сопряженную с пребыванием пакета в очереди.
- Формулы работают только для одного ТСР-соединения. Если через канал осуществляется несколько ТСРсоединений, каждое из них следует указанным формулам.
- Формулы предполагают долговременные ТСР-соединения. Для особо коротких соединений ( <10 пакетов ), когда нет потерь, работает алгоритм медленного старта. Для сессий промежуточной длительности, где в среднем теряется несколько сегментов, параметры окажутся несколько лучше, чем предсказывают формулы.
- Различие между простой и сложной формулами заключается в том, что сложная формула учитывает влияние таймаутов повторных передач. Для низкого уровня потерь ( <1% ), таймауты обычно не происходят и формулы дают практически идентичные результаты. При высоких потерях (
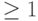 сложная формула дает большую точность оценки.
сложная формула дает большую точность оценки.