Опубликован: 28.09.2007 | Доступ: свободный | Студентов: 6206 / 1051 | Оценка: 4.20 / 4.10 | Длительность: 47:32:00
ISBN: 978-5-94774-707-2
Лекция 2:
Транспортные протоколы Интернет
Выводы
- TCP уязвимость в отношении случайных потерь делает трудным мультиплексирование информационного потока с трафиком реального времени при заметных временных вариациях скорости передачи (например, мультимедиа), в особенности, если оба вида трафика работают с общим буфером, что типично для большинства современных сетей. В сетях ATM, однако, TCP соединения могут поддерживаться с помощью классов трафика UBR или ABR, которые обычно буферизуются отдельно от высоко приоритетного VBR (Variable Bit Rate) или CBR (Constant Bit Rate) трафика. Если последние классы трафика имеют более высокий приоритет, TCP соединения обнаружат для себя емкость канала, варьируемую со временем, оставшуюся после обслуживания потоков VBR и CBR. Эти вариации могут приводить к "случайным потерям", которые сильно ухудшают рабочие характеристики. Однако если буфер имеет достаточный объем, чтобы сгладить эти вариации и удержать вероятность потери для соединения "точка--точка" ниже обратного квадрата произведения полосы на задержку, то рабочие характеристики TCP не будут серьезно ухудшены. Включение селективного подтверждения в TCP облегчит эту проблему, так как размер окна не нужно резко сокращать для изолированных случайных потерь.
- В дополнение к уязвимости от случайных потерь, тот факт, что потери являются основным средством обратной связи, используемым TCP, приводит к непомерным задержкам. Это происходит потому, что в сетях с высоким коэффициентом использования размер окна для TCP соединения будет увеличиваться и, после того как возможности узкого участка канала окажутся полностью исчерпанными, а буфер переполненным, произойдет потеря. Задержка и рабочие характеристики при потерях могут быть существенно улучшены, если мы вместо этого используем схему, которая лишь пытается поддерживать ширину окна, чтобы достичь высокого использования канала. Такая схема, как DECbit [2.26], реализует это, используя явную обратную связь со стороны коммутаторов; подобные схемы имеет смысл рассмотреть, особенно потому, что Explicit Congestion Notification (явное оповещение о перегрузке) встроена в качестве опции для сетей ATM. Заметим, однако, что схема DECbit, в частности, подвержена, как и TCP, проблемам при работе с соединениями при больших задержках распространения. Другой возможностью является более изощренная оценка RTT, сходная с тем, что сделано в работе [2.22]. Это, конечно, привлекательно, так как исключает необходимость явной обратной связи. Однако если задержка RTT может меняться существенно без изменения загрузки в канале (например, из-за того, что задержка обработки в узлах зависит от загрузки операционной системы или потому, что задержки связаны с особенностями работы мобильных приложений), тогда адаптация, базирующаяся на обработке задержек, может оказаться менее устойчивой, чем адаптация на основе потерь или явной обратной связи. Кроме того, если различные соединения не изолированы друг от друга с точки зрения использования ими полосы и сетевых буферов, тогда соединение, которое более агрессивно в отношении получения полосы и поднимающее скорость передачи до тех пор, пока не произойдет потеря, забьет соединения, которые анализируют RTT, чтобы избежать перегрузки. Таким образом, изменения на транспортном уровне должны либо адаптироваться универсально, либо тесно сотрудничать с сетевым уровнем, отслеживающим "алчные" соединения.
- Использование групповых подтверждений в TCP мотивирует в TCPtahoe сокращение ширины окна до единицы после потери, чтобы избежать всплеска потока пакетов из-за повторной их передачи. Это, в свою очередь, приводит к экспоненциальному увеличению размера окна при медленном старте, необходимому для сетей с большим произведением полосы на задержку. С другой стороны, это экспоненциальное увеличение вызывает серьезные флуктуации трафика, которые, если размер буфера меньше, чем 1/3 от произведения полосы на задержку, вызывает переполнение буфера и второй медленный старт, понижая пропускную способность. TCP-reno пытается избежать этого явления путем сокращения окна вдвое при обнаружении потери. В то время как это при идеальных условиях обеспечивает улучшенную пропускную способность, TCP-reno в его нынешнем виде слишком уязвим для фазовых эффектов и множественной потери пакетов, чтобы стать заменителем для TCP-tahoe. Основной проблемой с TCP-reno является то, что могут быть множественные ограничения на окно, связанные с одним эпизодом перегрузки, и что множественные потери могут приводить к таймауту (который на практике вызывает значительное снижение пропускной способности, если используются таймеры с низким разрешением). Версия TCP-Vegas [2.4,9] пытается реализовать ряд усовершенствований, таких, как более изощренная обработка и оценка RTT. Но для флуктуаций RTT в Интернет существует много других причин помимо заполнения буфера. Для того, чтобы существенно улучшить существующие версии TCP, необходимо избегать резких сокращений размеров окна как в TCP-tahoe, так и в TCP-reno за исключением случая, когда имеет место продолжительная перегрузка (которая вызывает массовые потери пакетов). Одним возможным средством обработки изолированных потерь без изменения размера окна является использование некоторой формы селективного подтверждения. В ожидании разработки удовлетворительного нового варианта предлагается применять TCPtahoe (в сочетании с управлением сетевого уровня, чтобы оптимизировать рабочие характеристики), так как этот вариант несравненно устойчивей, чем TCPreno.
- Несовершенство TCP для соединений с высокими задержками распространения может вызвать проблемы при мультиплексировании потоков на короткие и дальние расстояния в WAN. Короче говоря, эти эксплуатационные проблемы могут не проявиться, так как WAN может быть существенно недогружена и там может не оказаться узких мест (т.e. размер окна, необходимый для хорошей работы, может быть слишком мал, чтобы вызвать переполнение буфера, и поэтому достигается максимальная стационарная пропускная способность). Однако, для гарантирования рабочих характеристик в высоко загруженных сетях, каждое TCP соединение должно иметь зарезервированный буфер и полосу пропускания вдоль всего сетевого маршрута. Обычно выделение ресурсов осуществляется при формировании соединения и заставляет коммутаторы и маршрутизаторы формировать независимые очереди для каждого соединения [2.11], [2.25]. Так как администрирование ресурсов по принципу "наилучшего возможного" может оказаться весьма дорогим, более приемлемой альтернативой может быть резервирование ресурсов для каждого класса трафика. В такой ситуации несовершенство будет сохраняться, если TCP поддерживается поверх ATM с классом трафика UBR. Однако если TCP поддерживается поверх класса трафика ABR, варьирующаяся со временем скорость передачи, доступная для каждого соединения, определяется на сетевом уровне и администрируется отправителем, так, чтобы различные TCP соединения были изолированы друг от друга, даже если они совместно используют буферы.
- Так как предубеждение против соединений с большими задержками RTT связано с механизмом адаптации окна, оно в принципе может быть преодолено путем модификации механизма мониторирования полосы во время фазы избежания перегрузки, например, путем увеличения размера окна так, чтобы темп увеличения пропускной способности для всех соединений был одним и тем же (такая схема была рассмотрена, но не рекомендована в [2.13]). Однако невозможно выбрать универсальный временной масштаб для настройки окна, который бы работал для сетей с разной пропускной способностью и топологией. Во-первых, зондирование дополнительной полосы с темпом 1 Mбит/с в секунду может быть слишком быстрым для сети с каналом 1 Mбит/с, но слишком медленным для гигабитной сети. Таким образом, чтобы заставить работать такую схему, некоторый обмен между сетевым и транспортным уровнем был бы крайне существенным. Во-вторых, такая схема будет все же подвержена сильному воздействию некоторых недостатков TCP, таких, как деградация рабочих характеристик при наличии случайных потерь и чрезмерных задержек, связанных с попытками использования дополнительной полосы в условиях полного использования канала. Таким образом, эта модификация не может считаться лучшим подходом к проблеме оптимальности.
Суммируя, можно сказать, что мы идентифицировали несколько недостатков TCP, мы также представили возможные средства получения хороших рабочих характеристик посредством решений сетевого уровня, таких, как изоляция соединений друг от друга и предоставление буферов достаточного объема, чтобы устранить быстрые вариации доступной канальной емкости. Но нужно помнить, что нельзя увеличивать объем буфера беспредельно, так как это может привести к таймаутам и, в конечном итоге, к большим потерям пропускной способности. Особенно интересным является вопрос, как наилучшим образом поддержать TCP поверх ATM классов услуг ABR и UBR, так как это включает адаптацию сетевого и транспортного уровней. Другой важной областью исследований является разработка альтернативного механизма управления окном, который устранит некоторые недостатки TCP, сохранив его децентрализованную структуру. Децентрализованное адаптивное управление скоростью передачи, при сохранении справедливости распределения ресурсов, - задача трудная, если вообще возможная, но некоторое улучшение TCP несомненно реально. Возможные усовершенствования могут превзойти алгоритм исключения перегрузки за счет более изощренной оценки задержек RTT и использования селективного подтверждения, чтобы улучшить рабочие характеристики при наличии случайных потерь.
Здесь уместно сказать, что радикальным решением могло бы быть исчерпывающее информирование отправителя о состоянии и динамике заполнения всех буферов вдоль виртуального соединения. Такой алгоритм можно реализовать лишь при условии, что все сетевое оборудование вдоль виртуального пути способно распознавать сегменты отклики и выдавать требующиеся данные в рамках определенного протокола (в том числе и оборудование уровня L2!). Здесь предполагается, что маршрут движения сегментов туда и обратно идентичны. В последнее время появилось оборудование L2 (Ethernet), способное фильтровать трафик по IP-адресам и даже номерам портов (а это уже уровень L4). Так что решение уже не представляется чем-то совершенно фантастическим. Такие сетевые приборы могли бы помещать в пакеты откликов ACK информацию о состоянии своих буферов. Учитывая, что объемы буферов в разных устройствах могут отличаться весьма сильно, имеет смысл выдавать не число занятых позиций, а относительную долю занятого буферного пространства. Проблема здесь в том, что длительное время даже в локальных сетях, я уже не говорю про Интернет, будут сосуществовать сетевые устройства, как поддерживающие этот новый протокол, так и старые - не поддерживающие. Но даже в таких условиях этот протокол будет давать заметный выигрыш. Ведь новые устройства будут ставиться в первую очередь именно в "узких" местах сети, где потери были наиболее значимы. Условия загрузки нового устройства останутся теми же, но о них отправитель получит исчерпывающую информацию и за счет этого сможет оптимизировать трафик. При этом отправитель должен отслеживать не просто состояние на текущий момент, но и темп заполнения и освобождения буферов. Ширина окна в таком случае может определяться на основе прогноза состояния буфера на момент, когда туда придет соответствующий ТСРсегмент. Для этого отправителю придется выделить дополнительную память для хранения уровней заполнения буферов. Задержка в цепи отслеживания состояния тракта при этом будет минимальной. Существенный выигрыш могут получить сервис провайдеры с однородной структурой оборудования.
Проблема усложнена разнообразием технологий L2, ведь трудно себе представить, что нужную информацию о состоянии буферов будет выдавать ATM или SDH. Но наметившаяся тенденция использования Ethernet не только в LAN, но и в региональных сетях, может упростить задачу.
Альтернативой этому алгоритму могла бы служить схема, где каждому виртуальному соединению в каждом вовлеченном сетевом устройстве (включая L2) выделяется свой независимый буфер известного объема.
Любое из названных решений требует замены огромного объема оборудования. Но, вопервых, раз в 25 лет оборудование все равно обновляется, вовторых, это даст выигрыш в пропускной способности не менее двух раз и существенно упростит задачу обеспечения требуемого уровня QoS.
Первым шагом на пути внедрения отслеживания уровня заполнения буфера может служить ECN-алгоритм, описанный выше.
Разрабатывая новые версии драйверов ТСР-протокола, надо с самого начала думать и о сетевой безопасности, устойчивости программ против активных атак.
Новые трудности в реализации модели протокола ТСР возникли при работе с современными быстрыми (110 Гбит/с) и длинными ( RTT>200мсек ) каналами. Для пакетов с длиной 1500 байт время формирования окна оптимального размера достигает 83333 RTT (режим предотвращения перегрузки), что при RTT=100 мсек составляет 1,5 часа! При этом требования к вероятности потери пакетов становятся невыполнимыми. В норме для таких каналов BER лежит в пределах 10-7 - 10-8. Разрешение проблемы возможно путем использования опции Jumbo пакетов или за счет открытия нескольких параллельных ТСРсоединений. В последнее время предложено несколько новых моделей реализации ТСР: High Speed TCP (HSTCP - S.Floyd), Scalable TCP (STCP - T.Kelly), FAST (http://datatag.web.cern.ch/datatag/pfldnet2003/papers/ low.pdf), XCP (http://portal.acm.org/citation.cfm?doid=633035), SABUL (Y.Gu, X.Hong). Модификации HSTCP и STCP характеризуются тем, что при нескольких потоках с разными RTT они некорректно распределяют полосу. В этих условиях заметные трудности создает синхронизация потерь для конкурирующих потоков. Специально для случая высокой скорости и больших задержек разработана модификация BI-TCP (Binary Increase TCP - http://www.csc.ncsu.edu/faculty/rhee/export/bitcp.pdf, Lisong Xu, Khaled Harfoush and Injong Rhee, Binary Increase Congestion Control for Fast, Long Distance Networks). Протокол BI-TCP имеет следующие свойства:
- Масштабируемость. Протокол может масштабировать свою долю полосы до 10 Гбит/c при BER ~ 3,5?108 .
- RTT (равенство условий). При больших значениях окна его RTT неэквивалентность (unfairness) пропорциональна RTT-отношению (как в случае AIMD).
- TCP дружественность. Протокол достигает ограниченной ТСР-эквивалентности для всех размеров окна. Для высокой вероятности потерь, где ТСР работает хорошо, ТСРдружественность сопоставима с STCP.
- Эквивалентность (fairness) и сходимость. По сравнению с HSTCP и STCP, он позволяет получить большую эквивалентность полос пропускания в широком временном диапазоне и быструю сходимость к уровням справедливых долей.
AIMD демонстрирует квадратичный рост пропускной способности при увеличении отношения RTT (линейный рост "несправедливости"). Для других протоколов степень несправедливости еще выше.
Функция отклика протокола на перегрузку определяется отношением скоростей передачи пакетов в зависимости от вероятности их потери.
BI-TCP встраивается в TCPS-ACK. В протоколе используются следующие фиксированные параметры:
Low_window - если размер окна больше чем этот порог, используется BI-TCP, в противном случае - обычный ТСР;
Smax - максимальное приращение;
Smin - минимальное приращение;
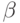 - мультипликативный коэффициент сокращений ширины окна;
- мультипликативный коэффициент сокращений ширины окна;
default_max_win - значение максимума окна по умолчанию
В протоколе используются следующие параметры:
max_win - максимальное значение ширины окна, в начале равно величине по умолчанию;
min_win - минимальная ширина окна;
prev_win - максимальное значение ширины окна до установления нового максимума;
target_win - средняя точка между максимумом и минимумом ширины окна;
Cwnd - размер окна перегрузки;
is_BITCP_ss - Булева переменная, указывающая, находится ли протокол в режиме медленного старта. В начале = false ;
ss_cwnd - переменная, отслеживающая эволюцию cwnd при медленном старте;
ss_target - значение cwnd после одного RTT при медленном старте BI-TCP.
При входе в режим быстрого восстановления:
if (low_window <= cwnd) {
prev_max = max_win;
max_win = cwnd;
cwnd = cwnd *(1?);
min_win = cwnd;
if (prev_max > max _win) //Fast. Conv.
max_win = (max_win + min_win)/2;
target_win = (max_win + min_win)/2;
} else {
cwnd = cwnd*0,5; //normal TCPКогда система не находится в режиме быстрого восстановления и приходит подтверждение для нового пакета, то:
if (low_window > cwnd) {
cwnd =cwnd + 1/cwnd; // normal TCP
return
}
if (is_BITCP_ss is false) { //bin.increase
if (target_win cwnd < Smax) // bin.search
cwnd += (target_win cwnd)/cwnd;
else
cwnd += Smax/cwnd; // additive incre.
if (max_win > cwnd) {
min_win = cwnd;
target_win = (max_win + min_win)/2;
} else {
is_BITCP_ss = true
ss_cwnd =1;
ss_target = cwnd+1;
max_win = default_max_win;
}
} else {
cwnd = cwnd + ss_cwnd/cwnd;
if(cwnd >= ss_target) {
ss_cwnd = 2*ss_cwnd; ss_target = cwnd + ss_cwnd;
}
if(ss_cwnd >= Smax)
is_BITCP_ss = false;
}