Настройка и ускорение программ в OpenMP
В процессе разработки программ этап настройки и ускорения работы программ занимает важное место. До этого этапа программа представляет собой еще сырой материал, поскольку, как правило, ее характеристики еще далеки от характеристик, запланированных перед началом разработки. Иногда ситуация оказывается еще хуже: характеристики программы перед этапом настройки вообще существенно ниже, чем те, которые ожидались. Поэтому на этапе настройки и ускорения программ, проанализировав с разных сторон созданную программу, нужно по возможности довести ее характеристики до запланированного уровня, а еще лучше - превзойти их. Важно отметить, что обычно доводка программы сопряжена с модификацией ее текста и очень часто - с изменением алгоритмов. Поэтому процесс настройки и ускорения тесно связан с предыдущими этапами разработки: компиляцией и тестированием. В самом деле, ведь в процессе настройки в текст разрабатываемой программы вносятся изменения, и поэтому программа должна быть вновь откомпилирована и протестирована.
Процесс настройки и ускорения программ, разрабатываемых с использованием OpenMP, тесно связан с анализом параллельных алгоритмов. Поэтому далее в настоящей лекции этому вопросу будет уделено значительное внимание. Также будет затронут вопрос автоматизации процесса настройки и ускорения.
Основные принципы настройки и ускорения программ в OpenMP
В этом разделе остановимся на основных стратегиях настройки и ускорения программ с использованием OpenMP.
В первую очередь следует отметить, что при настройке программ в OpenMP по возможности следует применять средства автоматизированного распараллеливания программ. В настоящее время все основные компиляторы Fortran и C/C++, предназначенные для разработки параллельных программ с использованием OpenMP, имеют возможности автоматического распараллеливания. Более подробно эти возможности будут рассмотрены в следующей лекции.
Чтобы найти и локализовать наиболее трудоемкие участки программы, можно воспользоваться возможностью профилирования (profiling) программы. В настоящее время этот процесс также в значительной степени автоматизирован. Существуют различные сервисные программы, позволяющие проводить профилирование разрабатываемых параллельных программ. Такие сервисные программы созданы различными производителями системного программного обеспечения, в том числе и компанией Intel. Как уже говорилось в предыдущей лекции, в состав набора программ Intel Threading Tools входит программа Intel Thread Profiler. Отметим также, что в составе программы Intel VTune Performance Analyzer имеются и другие средства профилирования программ. При профилировании программы важно выделить ее критический путь. Критический путь в многопоточной программе - это наиболее протяженный путь на диаграмме выполнения потоков. Для его определения необходимо провести анализ диаграммы выполнения потоков в параллельной программе. Пример такой диаграммы приведен на рис.6.1.
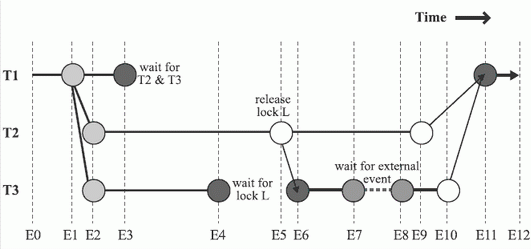
На этом рисунке через T1, T2 и T3 обозначены потоки в программе, а через E1, E2, …, Е12 - события в программе. Длина отрезков на диаграмме соответствует времени выполнения потоков. Обратите внимание, что образование параллельных потоков требует определенных временных затрат, что и отражено на диаграмме.
После профилирования программы и анализа результатов в настраиваемую программу рекомендуется добавить инструкции OpenMP для распараллеливания наиболее затратных участков. В первую очередь это касается потоков, составляющих критический путь в программе.
В случае недостаточно эффективного распараллеливания программы с использованием OpenMP следует обратить самое пристальное внимание:
- на распараллеливание конструкций do/for. Надо обязательно учитывать высокую трудоемкость инициализации параллельных потоков;
- на неэффективность распараллеливания небольших циклов;
- на несбалансированность потоков;
- на недопустимость многочисленных ссылок к переменным в общей памяти;
- на ограниченный объем кэш-памяти;
- на высокую стоимость операции синхронизации;
- на значительные задержки доступа к удаленной общей памяти (на NUMA-компьютерах).
При распараллеливании вложенных циклов следует сначала распараллеливать внешние петли. Также следует иметь в виду, что петли циклов по объему вычислений могут быть зачастую "треугольными" и порождать несбалансированные параллельные потоки. Чтобы избежать несбалансированности при работе программы, следует правильно использовать возможности директивы OpenMP schedule.
Иерархия памяти
Современные параллельные системы могут иметь весьма сложную иерархию памяти. Ниже дана примерная классификация памяти современных высокопроизводительных систем по мере возрастания времени доступа к памяти:
- регистры;
- кэш-память 1-го уровня;
- кэш-память 2-го уровня;
- кэш-память 3-го уровня;
- локальная память;
- удаленная память (с доступом через интерфейс межузлового соединения Interconnect).
Время доступа к памяти существенно возрастает при движении по иерархии сверху вниз - порой даже в несколько раз. В связи с этим становится весьма актуальной задача эффективной загрузки кэш-памяти и регистров, а также минимизация доступа к удаленной памяти.
Настройка кэш-памяти
Для эффективной загрузки кэш-памяти необходимо в первую очередь принимать специальные меры по выравниванию строк или столбцов массивов. В программах, написанных на алгоритмических языках C/C++, следует выравнивать строки массивов, а в программах, написанных на алгоритмическом языке Fortran, - столбцы.
Для эффективного применения кэш-памяти рекомендуется использовать многомерные массивы в одномерном виде.
Вложенные циклы следует модифицировать так, чтобы обеспечить последовательный быстрый доступ к элементам массива без скачков по индексам.
Рассмотрим пример фрагмента параллельной программы, представленный в примере 6.1. В этом примере элементы массива prss, используемые в петлях цикла по k, разнесены между собой со значительными скачками. Для преодоления указанной трудности и улучшения загрузки кэш-памяти можно применить перестановку циклов, как показано во фрагменте программы, приведенном в примере 6.2.
!$omp parallel do
!$omp& private (r1, r2, k, j)
do j = jlow, jup
do k = 2, kmax - 1
r1 = prss(jminu(j),k) + prss(jplus(j),k) - 2. * prss(j,k)
r2 = prss(jminu(j),k) + prss(jplus(j),k) - 2. * prss(j,k)
coef (j,k) = ABC (r1/r2)
enddo
enddo
!$omp end parallel
6.1.
Пример фрагмента программы с циклом, петли которого содержат обращения к элементам массива со значительными скачками по индексам
!$omp parallel do
!$omp& private (r1, r2, k, j)
do k = 2, kmax - 1
do j = jlow, jup
r1 = prss(jminu(j),k) + prss(jplus(j),k) - 2. * prss(j,k)
r2 = prss(jminu(j),k) + prss(jplus(j),k) - 2. * prss(j,k)
coef (j,k) = ABC (r1/r2)
enddo
enddo
!$omp end parallel
6.2.
Пример модификации фрагмента программы с перестановкой циклов, оптимизирующей загрузку кэш-памяти
Очень часто загрузку кэш-памяти можно улучшить с помощью транспонирования элементов массивов в петлях вложенных циклов. Рассмотрим такой пример. В примере 6.3 показаны исходный и модифицированный Исходный вариант:
Исходный вариант:
real rx (jdim, idim)
!$omp parallel do
do i = 2, n -1
do j = 2, n
rx(i, j) = rx(i, j -1) + …
enddo
enddo
Модифицированный вариант:
real rx (idim, jdim)
!$omp parallel do
do i = 2, n - 1
do j = 2, n
rx(j, I) = rx(j -1, i) + …
enddo
enddo
6.3.
Пример модификации программы с переопределением массива для оптимизации загрузки кэш-памяти
фрагменты параллельной программы с вложенными циклами, в которых осуществляется обращение к элементам массивов rx. Для оптимизации загрузки кэш-памяти в этом примере массив rx транспонирован.
На компьютерах серии NUMALINK (non-uniform memory access) с неоднородным по времени доступом к памяти важно учитывать следующие особенности:
- надо хорошо представлять, где запущены потоки;
- надо четко понимать, какие данные загружены в локальную память;
- необходимо знать стоимость доступа к удаленной памяти. Для систем с NUMALINK все вышеперечисленные особенности очень сильно зависят от их архитектуры.
В программах, написанных с использованием OpenMP, существуют следующие возможности управления потоками:
- можно запускать поток на определенном процессоре;
- можно размещать данные в определенном месте памяти.
Эти задачи решаются с помощью системных инструкций, которые могут быть различными на различных платформах и зависеть от используемого системного программного обеспечения.