|
При прохождении теста 1 в нем оказались вопросы, который во-первых в 1 лекции не рассматривались, во-вторых, оказалось, что вопрос был рассмаотрен в самостоятельно работе №2. Это значит, что их нужно выполнить перед прохождением теста? или это ошибка? |
Новосибирский Государственный Университет
Опубликован: 20.08.2013 | Доступ: свободный | Студентов: 873 / 41 | Длительность: 14:11:00
Темы: Программирование, Графика и дизайн
Специальности: Программист, Системный архитектор
Самостоятельная работа 3:
Машинное обучение
2.2. Машина опорных векторов
Пусть 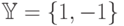 , т.е. рассматривается задача бинарной классификации. Идея алгоритма машины опорных векторов (Support Vector Machine, SVM) заключается в построении оптимальной поверхности
, т.е. рассматривается задача бинарной классификации. Идея алгоритма машины опорных векторов (Support Vector Machine, SVM) заключается в построении оптимальной поверхности  , представляющей собой гиперплоскость в спрямляющем пространстве
, представляющей собой гиперплоскость в спрямляющем пространстве  (см. лекционную часть курса), разделяющей точки
(см. лекционную часть курса), разделяющей точки 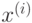 различных классов из обучающей выборки. Фактически, обучение алгоритмом опорных векторов заключается в решении оптимизационной задачи
различных классов из обучающей выборки. Фактически, обучение алгоритмом опорных векторов заключается в решении оптимизационной задачи
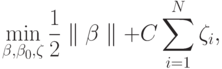
при ограничениях
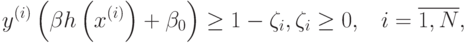
где отображение 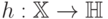 задает переход в спрямляющее пространство,
задает переход в спрямляющее пространство,  – параметр алгоритма обучения, регулирующий величину штрафа за то, что некоторые точки выходят за границу разделяющей полосы
– параметр алгоритма обучения, регулирующий величину штрафа за то, что некоторые точки выходят за границу разделяющей полосы  . При этом отображение
. При этом отображение  может быть задано неявно с помощью, так называемого, ядра
может быть задано неявно с помощью, так называемого, ядра 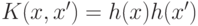 .Решающая функция запишется в виде
.Решающая функция запишется в виде 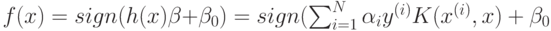 . Данная функция зависит от некоторых точек из обучающей выборки, называемых опорными векторами.
. Данная функция зависит от некоторых точек из обучающей выборки, называемых опорными векторами.
Данный метод применим для решения задач классификации, но также может быть обобщен на случай регрессии [ 1 ], однако, подробное изложение регрессионного алгоритма выходит за рамки данной лабораторной работы. Также, несмотря на то, что выше описывался алгоритм бинарной классификации с использованием машины опорных векторов, данный метод легко обобщается на случай произвольного количества классов с помощью универсальных подходов "один против всех" или "каждый против каждого", тем самым сводясь к решению нескольких задач классификации с двумя классами. Машина опорных векторов как для классификации, так и для восстановления регрессии работает лишь с количественными признаками и не допускает наличия пропущенных значений.
Функционал, связанный с обучением машины опорных векторов, ее сохранением/загрузкой и использованием обученной модели для осуществления предсказаний реализован в классе CvSVM, как и все реализации алгоритмов обучения с учителем в библиотеке, унаследованном от класса CvStatModel. Остановимся подробнее на описании данного класса.
Для обучения машины опорных векторов служит метод train.
bool CvSVM::train(const Mat& trainData,
const Mat& responses,
const Mat& varIdx=Mat(),
const Mat& sampleIdx=Mat(),
CvSVMParams params=CvSVMParams());
Параметры:
-
trainData – матрица, содержащая векторы из обучающей выборки. Матрица должна иметь тип CV_32F и размеры
 , таким образом, храня в i-й строке координаты вектора .
, таким образом, храня в i-й строке координаты вектора . -
responses – матрица-вектор, содержащая значения целевой переменной
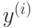 для прецедентов обучающей выборки. Данная матрица должна иметь тип CV_32S или CV_32F и размеры
для прецедентов обучающей выборки. Данная матрица должна иметь тип CV_32S или CV_32F и размеры  или
или  .
. -
varIdx – матрица-вектор, содержащая либо номера признаков (тип матрицы CV_32S), которые необходимо использовать при обучении, либо маску (тип матрицы CV_8U) размера
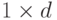 , где единицами отмечены используемые признаки, нулями – игнорируемые. По умолчанию (varIdx=Mat()) используются все признаки.
, где единицами отмечены используемые признаки, нулями – игнорируемые. По умолчанию (varIdx=Mat()) используются все признаки. - sampleIdx – матрица-вектор, имеющая такой же формат, как и varIdx, но отвечающая за прецеденты выборки, которые необходимо использовать для обучения. По умолчанию используются все имеющиеся прецеденты.
- params – параметры алгоритма обучения.
Для представления параметров SVM в OpenCV используется структура CvSVMParams.
struct CvSVMParams
{
CvSVMParams();
CvSVMParams( int svm_type,
int kernel_type,
double degree,
double gamma,
double coef0,
double Cvalue,
double nu,
double p,
CvMat* class_weights,
CvTermCriteria term_crit );
int svm_type;
int kernel_type;
double degree;
double gamma;
double coef0;
double C;
double nu;
double p;
CvMat* class_weights;
CvTermCriteria term_crit;
};
Рассмотрим поля данной структуры.
Поле svm_type отвечает за тип используемой машины опорных векторов. Возможные значения данной переменной описаны перечислением в классе CvSVM:
enum {C_SVC=100, NU_SVC=101, ONE_CLASS=102, EPS_SVR=103,
NU_SVR=104};
C_SVC и NU_SVC обозначают различные модификации SVM для классификации, в то время как EPS_SVR и NU_SVR представляют собой формализации для регрессии. Машина опорных векторов типа ONE_CLASS строит границу области, в которой расположены точки одного единственного класса. Описанная выше задача оптимизации соответствует типу C_SVC (формализации с использованием параметра 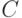 ). SVM типа NU_SVC решает схожую, но другую задачу с параметром
). SVM типа NU_SVC решает схожую, но другую задачу с параметром ![v \in [0,1]](/sites/default/files/tex_cache/7eeac3bdac96def7b99bf96a57424fdc.png) , являющимся нижней оценкой на долю опорных векторов в обучающей выборке и верхней границей доли неправильно классифицированных прецедентов обучающей выборки.
, являющимся нижней оценкой на долю опорных векторов в обучающей выборке и верхней границей доли неправильно классифицированных прецедентов обучающей выборки.
Поле kernel_type структуры CvSVMParams служит для обозначения используемого ядра. Возможные значения данной переменной также описаны в перечислении класса CvSVM:
enum { LINEAR=0, POLY=1, RBF=2, SIGMOID=3 };
В библиотеке OpenCV реализована непосредственная поддержка следующих ядер:
- линейное ядро (LINEAR):
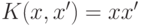 ;
; - многочлен степени
 (POLY):
(POLY): 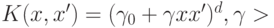 ;
; - радиальная функция (RBF):
 ;
; - сигмоидальная функция (SIGMOID):
 .
.
Далее в структуре CvSVMParams идут параметры ядер: degree соответствует степени многочлена, определяющего полиномиальное ядро, gamma – параметру 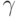 в полиномиальном, радиальном и сигмоидальном ядрах, coef0 – параметру
в полиномиальном, радиальном и сигмоидальном ядрах, coef0 – параметру 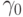 в полиномиальном и сигмоидальном ядрах. При использовании ядра, не имеющего того или иного параметра, значение, хранящееся в соответствующем поле структуры, игнорируется и может быть любым.
в полиномиальном и сигмоидальном ядрах. При использовании ядра, не имеющего того или иного параметра, значение, хранящееся в соответствующем поле структуры, игнорируется и может быть любым.
Поля C, nu и p соответствуют параметрам оптимизационных задач, решаемых алгоритмом обучения. Тип используемой машины опорных векторов указывает на то, какой из этих параметров "активен": C используется совместно с C_SVC, EPS_SVR и NU_SVR; nu – с NU_SVC, NU_SVR и ONE_CLASS; p – с EPS_SVR.
Поле class_weights предназначено для хранения матрицы-вектора, содержащей веса различных классов и может использоваться с машиной опорных векторов типа C_SVC, позволяя определить различные значения параметра для точек разных классов. Как отмечалось выше, решение задачи классификации более чем на два класса сводится к серии задач бинарной классификации. В CvSVM реализован подход "каждый против каждого". Таким образом, при решении задачи разделения точек классов 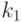 и
и 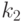 решается задача
решается задача
![\min_{\beta,\beta_{0},\zeta}\frac{1}{2}\parallel \beta\parallel + class\_weights[k_{1}] \cdot C \sum_{i:y_{i}=k_{1}} \zeta_{i} + class\_weights[k_{2}] \cdot C \sum_{i:y_{i}=k_{2}} \zeta_{i}.](/sites/default/files/tex_cache/a306af4ed1542c46d7e69bebd5e249d0.png)
Данный параметр может быть полезен при несбалансированной обучающей выборке, содержащей малое количество прецедентов одного класса и большое количество другого. Чем больше вес, тем больший штраф назначается за неправильную классификацию обучающего прецедента этого класса. По умолчанию (class_weights = NULL) все веса равны.
Последним нерассмотренным полем структуры CvSVMParams является term_crit. Данная переменная содержит параметры итерационного метода, используемого для решения оптимизационной задачи на этапе обучения. Данные параметры указываются с помощью следующей структуры:
struct CvTermCriteria
{
int type;
int max_iter;
double epsilon;
};
Рассмотрим поля данной структуры:
- type – вид критерия останова: по точности (CV_TERMCRIT_EPS) или по количеству итераций (CV_TERMCRIT_ITER). Значение type, равное CV_TERMCRIT_EPS + CV_TERMCRIT_ITER, применяется в случае, когда используются оба критерия.
- max_iter – максимальное количество итераций.
- epsilon – пороговое значение точности.
Для использования обученной ранее модели в классе CvSVM используются методы
float predict( const Mat& sample,
bool returnDFVal=false ) const;
void predict( InputArray samples,
OutputArray results ) const;
Рассмотрим их параметры.
-
sample – матрица-вектор типа CV_32F и размера , содержащая координаты одной точки в пространстве признаков.
-
returnDFVal – флаг, позволяющий получать расстояние со знаком от разделяющей поверхности до указанной точки. Если returnDFVal=true и решается задача бинарной классификации, то возвращаемым значением будет величина
 , иначе будет возвращено предсказанное значение целевого признака.
, иначе будет возвращено предсказанное значение целевого признака. -
samples – матрица типа CV_32F и размера
 , построчно содержащая координаты точек в пространстве признаков, для которых необходимо сделать предсказания.
, построчно содержащая координаты точек в пространстве признаков, для которых необходимо сделать предсказания. - results – матрица-вектор, в которую будут сохранены предсказанные значения.
Для сохранения обученной модели используется метод
void save( const char* filename,
const char* name=0 ) const;
Параметры данного метода:
- filename – путь и имя файла, в который будет сохранена модель. В OpenCV поддерживается запись в XML- и YAML-файлы.
- name – имя, под которым будет сохранена модель. Имя модели может состоять из строчных и заглавных букв латинского алфавита, цифр, символов "-" и "_". В случае сохранения в YAML-формате также допустимо использование пробелов.
Загрузка модели из файла осуществляется методом
void load( const char* filename, const char* name=0 );
Рассмотрим его параметры:
- filename – XML- или YAML-файл, из которого будет выполнена загрузка.
- name – имя модели, которую требуется загрузить.
Также в классе CvSVM реализован метод, позволяющий получить количество опорных векторов:
int get_support_vector_count() const;
и метод для получения опорного вектора с номером  :
:
const float* get_support_vector(int i) const;
Александра Максимова
Алена Борисова
|
В лекции по обработке полутоновых изображений (http://www.intuit.ru/studies/courses/10621/1105/lecture/17979?page=2) увидела следующий фильтр:
В описании говорится, что он "делает изображение более чётким, потому что, как видно из конструкции фильтра, в однородных частях изображение не изменяется, а в местах изменения яркости это изменение усиливается". Что вижу я в конструкции фильтра (скорее всего ошибочно): F(x, y) = 2 * I(x, y) - 1/9 I(x, y) = 17/9 * I(x, y), где F(x, y) - яркость отфильтрованного пикселя, а I(x, y) - яркость исходного пикселя с координатами (x, y). Что означает обычное повышение яркости изображения, при этом без учета соседних пикселей (так как их множители равны 0). Объясните, пожалуйста, как данный фильтр может повышать четкость изображения? |
