|
При прохождении теста 1 в нем оказались вопросы, который во-первых в 1 лекции не рассматривались, во-вторых, оказалось, что вопрос был рассмаотрен в самостоятельно работе №2. Это значит, что их нужно выполнить перед прохождением теста? или это ошибка? |
Спонсор: Intel
Вы можете этот курс.
Новосибирский Государственный Университет
Опубликован: 20.08.2013 | Доступ: свободный | Студентов: 861 / 36 | Длительность: 14:11:00
Темы: Программирование, Графика и дизайн
Специальности: Программист, Системный архитектор
Теги:
Самостоятельная работа 3:
Машинное обучение
Рассмотрим пример использования класса CvSVM для решения задачи классификации.
#include <stdlib.h>
#include <stdio.h>
#include <opencv2/core/core.hpp>
#include <opencv2/ml/ml.hpp>
using namespace cv;
// размерность пространства признаков
const int d = 2;
// функция истинной зависимости целевого признака
// от остальных
int f(Mat sample)
{
return (int)((sample.at<float>(0) < 0.5f &&
sample.at<float>(1) < 0.5f) ||
(sample.at<float>(0) > 0.5f &&
sample.at<float>(1) > 0.5f));
}
int main(int argc, char* argv[])
{
// объем генерируемой выборки
int n = 2000;
// объем обучающей части выборки
int n1 = 1000;
// матрица признаковых описаний объектов
Mat samples(n, d, CV_32F);
// номера классов (матрица значений целевой переменной)
Mat labels(n, 1, CV_32S);
// генерируем случайным образом точки
// в пространстве признаков
randu(samples, 0.0f, 1.0f);
// вычисляем истинные значения целевой переменной
for (int i = 0; i < n; ++i)
{
labels.at<int>(i) = f(samples.row(i));
}
// создаем маску прецедентов, которые будут
// использоваться для обучения: используем n1
// первых прецедентов
Mat trainSampleMask(1, n1, CV_32S);
for (int i = 0; i < n1; ++i)
{
trainSampleMask.at<int>(i) = i;
}
// используем SVM типа C_SVC и радиальным ядром
CvSVMParams params;
params.svm_type = CvSVM::C_SVC;
params.kernel_type = CvSVM::RBF;
params.gamma = 1.0;
params.C = 1.0;
CvSVM svm;
svm.train(samples, labels,
Mat(), trainSampleMask, params);
svm.save("model.yml", "simpleSVMModel");
// вычисляем ошибку на обучающей выборке
Mat predictions;
svm.predict(samples.rowRange(0, n1), predictions);
float trainError = 0.0f;
for (int i = 0; i < n1; ++i)
{
trainError += (labels.at<int>(i) !=
(int)(predictions.at<float>(i)));
}
trainError /= float(n1);
// вычисляем ошибку на тестовой выборке
predictions = Mat();
svm.predict(samples.rowRange(n1, n), predictions);
float testError = 0.0f;
for (int i = 0; i < n - n1; ++i)
{
testError += (labels.at<int>(n1 + i) !=
(int)(predictions.at<float>(i)));
}
testError /= float(n - n1);
printf("train error = %.4f\ntest error = %.4f\n",
trainError, testError);
return 0;
}
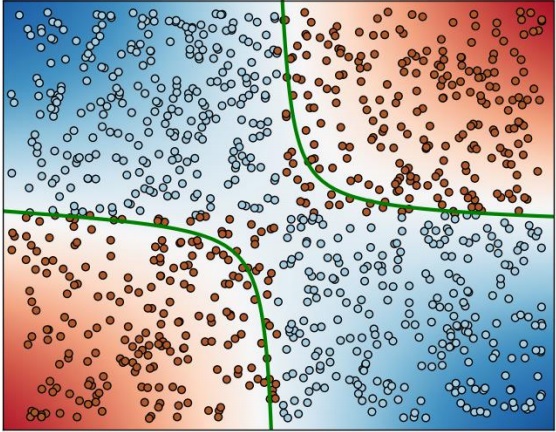
Визуальное представление данных и построенной границы между точками разных классов приведено на рис. 8.1.
Александра Максимова
Алена Борисова
|
В лекции по обработке полутоновых изображений (http://www.intuit.ru/studies/courses/10621/1105/lecture/17979?page=2) увидела следующий фильтр:
В описании говорится, что он "делает изображение более чётким, потому что, как видно из конструкции фильтра, в однородных частях изображение не изменяется, а в местах изменения яркости это изменение усиливается". Что вижу я в конструкции фильтра (скорее всего ошибочно): F(x, y) = 2 * I(x, y) - 1/9 I(x, y) = 17/9 * I(x, y), где F(x, y) - яркость отфильтрованного пикселя, а I(x, y) - яркость исходного пикселя с координатами (x, y). Что означает обычное повышение яркости изображения, при этом без учета соседних пикселей (так как их множители равны 0). Объясните, пожалуйста, как данный фильтр может повышать четкость изображения? |
