|
При прохождении теста 1 в нем оказались вопросы, который во-первых в 1 лекции не рассматривались, во-вторых, оказалось, что вопрос был рассмаотрен в самостоятельно работе №2. Это значит, что их нужно выполнить перед прохождением теста? или это ошибка? |
Новосибирский Государственный Университет
Опубликован: 20.08.2013 | Доступ: свободный | Студентов: 873 / 41 | Длительность: 14:11:00
Темы: Программирование, Графика и дизайн
Специальности: Программист, Системный архитектор
Лекция 2:
Введение в машинное обучение
1.1.5. Случайный лес
Один из общих подходов в машинном обучении заключается в использовании композиции "слабых" решающих правил. Итоговое правило строится путем взвешенного голосования ансамбля базовых правил. Для построения базовых правил и вычисления весов в последнее время часто используются две идеи:
- Баггинг (bagging – bootstrap aggregation): обучение базовых правил происходит на различных случайных подвыборках данных или/и на различных случайных частях признакового описания; при этом базовые правила строятся независимо друг от друга.
- Бустинг (boosting): каждое следующее базовое правило строится с использованием информации об ошибках предыдущих правил, а именно, веса объектов обучающей выборки подстраиваются таким образом, чтобы новое правило точнее работало на тех объектах, на которых предыдущие правила чаще ошибались.
Эксперименты показывают, что, как правило, бустинг работает на больших обучающих выборках, тогда как баггинг – на малых.
Одной из реализаций идеи баггинга является случайный лес [ 2 ].
Случайный лес, а точнее – случайные леса (random forests), является одним из наиболее универсальных и эффективных алгоритмов обучения с учителем, применимым как для задач классификации, так и для задач восстановления регрессии. Идея метода [ 2 ] заключается в использовании ансамбля из  деревьев решений (например,
деревьев решений (например, 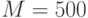 ), которые обучаются независимо друг от друга. Итоговое решающее правило заключается в голосовании всех деревьев, входящих в состав ансамбля.
), которые обучаются независимо друг от друга. Итоговое решающее правило заключается в голосовании всех деревьев, входящих в состав ансамбля.
Для построения каждого дерева решений используется следующая процедура:
- Генерация случайной подвыборки из обучающей выборки путем процедуры изъятия с возвращением (так называемая бутстрэп-выборка). Размер данной подвыборки обычно составляет 50–70% от размера всей обучающей выборки.
- Построение дерева решений по данной подвыборке, причем в каждом новом узле дерева переменная для разбиения выбирается не из всех признаков, а из случайно выбранного их подмножества небольшой мощности
 . Дерево строится до тех пор, пока не будет достигнут минимальный размер листа
. Дерево строится до тех пор, пока не будет достигнут минимальный размер листа 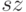 (количество объектов, попавших в него). Рекомендуемые значения: для задачи классификации
(количество объектов, попавших в него). Рекомендуемые значения: для задачи классификации 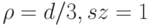 , для задачи восстановления регрессии
, для задачи восстановления регрессии 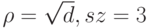 .
.
Одной из модификаций метода случайных деревьев является алгоритм крайне случайных деревьев (extremely random forests), в котором на каждом этапе для выбора признака, по которому будет проводиться разбиение, используется вновь сгенерированная случайная бутстрэп-выборка.
Среди достоинств алгоритма случайных деревьев можно выделить высокое качество предсказания, способность эффективно обрабатывать данные с большим числом классов и признаков, внутреннюю оценку обобщающей способности модели. Легко построить параллельную высоко масштабируемую версию алгоритма. Кроме того, доказано, что данный алгоритм не переобучается (с ростом ). Также метод обладает всеми преимуществами деревьев решений, в том числе отсутствием необходимости предобработки входных данных, обработкой как вещественных, так и категориальных признаков, поддержкой работы с отсутствующими значениями.
1.1.6. Градиентный бустинг деревьев решений
Градиентный бустинг деревьев решений (Gradient Boosting Trees – GBT) [ 6 , 7 ] – другой универсальный алгоритм машинного обучения, основанный на использовании ансамбля деревьев решений. В отличие от случайного леса градиентный бустинг является развитием бустинг-идеи.
Алгоритм минимизирует эмпирический риск жадным пошаговым алгоритмом, аналогичным методу градиентного спуска. Рассмотрим, например, задачу восстановления регрессии используют. Рассмотрим суммарный штраф на обучающей выборке как функцию от значений решающего правила  в точках
в точках 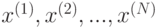 :
:
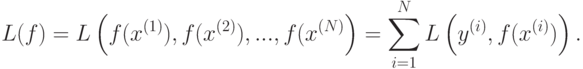
Тогда градиент функции  равен
равен
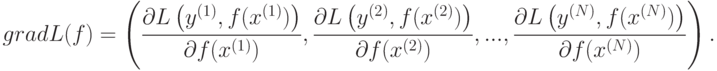
На предварительном этапе алгоритм строит оптимальную константную модель  . На
. На  -й итерации конструируется дерево решений
-й итерации конструируется дерево решений 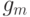 (небольшой глубины), аппроксимирующее компоненты вектора антиградиента, вычисленного для текущей модели . После этого значения в узлах построенного дерева перевычисляются, так, чтобы минимизировать суммарную величину штрафа
(небольшой глубины), аппроксимирующее компоненты вектора антиградиента, вычисленного для текущей модели . После этого значения в узлах построенного дерева перевычисляются, так, чтобы минимизировать суммарную величину штрафа 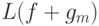 . Далее осуществляем присваивание
. Далее осуществляем присваивание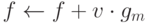 , что и завершает -ю итерацию. Здесь
, что и завершает -ю итерацию. Здесь 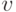 - параметр регуляризации (shrinkage), призванный бороться с возможным переобучением. Он выбирается из интервала (0,1].
- параметр регуляризации (shrinkage), призванный бороться с возможным переобучением. Он выбирается из интервала (0,1].
Для решения задачи восстановления регрессии часто используются следующие штрафные функции:
квадратичный штраф
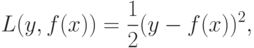
абсолютный штраф
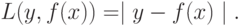
или функция Хьюбера
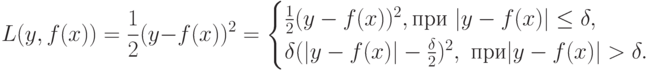
Заметим, что функция Хьюбера и квадратичный штраф дифференцируемы всюду, тогда как абсолютный штраф - везде, кроме точек, в которых 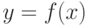 .
.
Для задачи классификации с 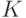 классами метод остается прежним, только вместо одной функции конструируют сразу функций
классами метод остается прежним, только вместо одной функции конструируют сразу функций 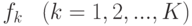 . В качестве штрафа можно использовать кросс-энтропию
. В качестве штрафа можно использовать кросс-энтропию
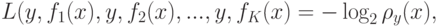
где

- есть оценка вероятности того, что 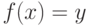 . Итоговый классификатор определяется как
. Итоговый классификатор определяется как

Более подробное описание алгоритма см. в [ 6 , 7 ].
Другим популярным методом, использующим идею бустинга, является алгоритм AdaBoost и его модификации [ 5 ].
1.2. Кластеризация
В задачах обучения без учителя (unsupervised learning) у объектов не известны выходы, и требуется найти некоторые закономерности в данных. К задачам обучения без учителя относят задачи кластеризации, понижения размерности, визуализации и др. Здесь рассматривается только кластеризация.
Задача кластеризации - это задача разбиения заданного набора объектов на кластеры, т. е. группы близких по своему признаковому описанию объектов. "Похожие" друг на друга объекты должны входить в один кластер, "не похожие" объекты должны попасть в разные кластеры.
Близость ("похожесть") объектов измеряется на основе функции расстояния 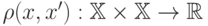 .
.
1.2.1. Метод центров тяжести
Рассмотрим один из алгоритмов, решающих задачу кластеризации - метод центров тяжестей (-means). На вход алгоритма поступает набор данных
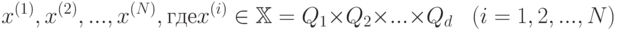
и натуральное число - количество кластеров, на которые нужно разбить данные. Алгоритм реализует пошаговую процедуру минимизации
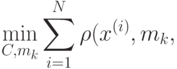
где 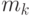 - центр тяжести объектов, относящихся
- центр тяжести объектов, относящихся  -му кластеру:
-му кластеру:
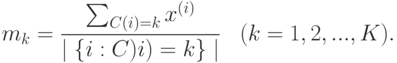
При этом не гарантируется нахождение глобального минимума. На предварительном этапе строится некоторое разбиение входных данных на групп (например, случайно). Пусть 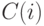 - номер группы, к которой принадлежит -й объект. В ходе работы алгоритма значения обновляются. В конце работы алгоритма значения будут соответствовать разбиению данных на кластеры. Каждая итерация представляет собой последовательность следующих шагов:
- номер группы, к которой принадлежит -й объект. В ходе работы алгоритма значения обновляются. В конце работы алгоритма значения будут соответствовать разбиению данных на кластеры. Каждая итерация представляет собой последовательность следующих шагов:
- Вычисляем центр тяжести
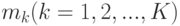 объектов в каждой группе.
объектов в каждой группе. - Для каждого объекта
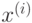 находим , для которого расстояние от до , т. е.
находим , для которого расстояние от до , т. е. 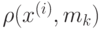 , минимально. Обновляем функцию , положив
, минимально. Обновляем функцию , положив  .
.
Итерации завершаются, когда наступает стабилизация значений , либо по достижении максимального значения числа итераций.
1.2.2. Метод медиан
Метод центров тяжестей работает с явными описаниями объектов Модификацией этого метода является метод медиан, или метод срединных точек, ( -medians, или -medoids). На вход этого алгоритма подается число кластеров и матрица расстояний 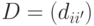 , где
, где 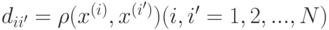 . Заметим, что сама функция
. Заметим, что сама функция 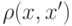 может быть не известна.
может быть не известна.
Алгоритм ничем не отличается от предыдущего, но вместо центра тяжестей, для каждой группы будем находить медиану, или срединную точку, 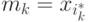 где
где
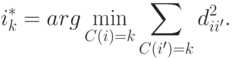
Каждая итерация представляет собой последовательность следующих шагов:
- Вычисляем медиану
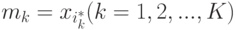 объектов в каждой группе.
объектов в каждой группе. - Для каждого объекта находим , для которого
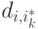 минимально. Обновляем функцию положив
минимально. Обновляем функцию положив  .
.
Как правило, результаты работы алгоритмов центров тяжестей и медиан (если они оба применимы к данным) близки.
Александра Максимова
Алена Борисова
|
В лекции по обработке полутоновых изображений (http://www.intuit.ru/studies/courses/10621/1105/lecture/17979?page=2) увидела следующий фильтр:
В описании говорится, что он "делает изображение более чётким, потому что, как видно из конструкции фильтра, в однородных частях изображение не изменяется, а в местах изменения яркости это изменение усиливается". Что вижу я в конструкции фильтра (скорее всего ошибочно): F(x, y) = 2 * I(x, y) - 1/9 I(x, y) = 17/9 * I(x, y), где F(x, y) - яркость отфильтрованного пикселя, а I(x, y) - яркость исходного пикселя с координатами (x, y). Что означает обычное повышение яркости изображения, при этом без учета соседних пикселей (так как их множители равны 0). Объясните, пожалуйста, как данный фильтр может повышать четкость изображения? |
