Северный (Арктический) федеральный университет им. М.В. Ломоносова
Опубликован: 23.10.2013 | Доступ: свободный | Студентов: 1898 / 714 | Длительность: 09:26:00
Специальности: Программист
Лекция 4:
Распознавание речи в Intel Perceptual Computing SDK
Аннотация: Лекция рассматривает основные особенности речевого взаимодействия с компьютером, модуль распознавания речи в пакете Intel Perceptual Computing SDK. Особенности программирования распознавания речи, режим голосового управления и особенности синтеза речи.
Ключевые слова: developer, forum, программа, поиск, ПО, twitter, корпорация, perceptual, Computing, SDK, входной, слово, модуль, распознавание, приложение, список, assistant, voice, Command, AND, control, synthesis, core, процессор, EULA, interactive, gesture, camera, класс, интерфейс, функция, объект, очередь, ONE, жизненный цикл, программирование, идентификатор
Введение
Презентацию к лекции можно скачать здесь.
"Люди при общении друг с другом не ограничены каким-то одним интерфейсом: мы пишем, говорим, жестикулируем… Компьютеры также должны поддерживать разные способы коммуникаций" (Дэвид Перлмуттер, старший вице-президент Intel). Это заявление прозвучало на открытии ежегодного форума для разработчиков Intel Developer Forum в сентябре 2012 года. Тогда же представители Intel показали ноутбук с тестовой версией системы распознавания речи Dragon от одного из лидеров этого рынка – компании Nuance. В ходе демонстрации программа безошибочно распознавала короткие запросы на естественном английском языке, выполняя поиск в Google, запуская проигрывание музыки определенного жанра (по нечеткому запросу вроде "включи мне какой-нибудь рок"), публикуя сообщение в сервисе микроблогов Twitter – и все это без прикосновения пользователя к клавиатуре.
В октябре 2012 года корпорация Intel выпустила тестовую версию бесплатного пакета для разработчиков программ с перцептивными интерфейсами – Intel Perceptual Computing SDK, упрощающего и ускоряющего процесс создания подобных приложений.
Особенности речевого взаимодействия с компьютером
Схему речевого взаимодействия человека и компьютера можно изобразить следующим образом – рис. 6.1.
Голосовые интерфейсы хорошо подходят для управления информацией и доступа к ней, в случае сложно организованного и открытого информационного пространства, пользователи которого не имеют серьезной подготовки в области взаимодействия с компьютерами. Зачастую взаимодействие с информационной средой возможно только по телефону, в этом случае без голосового управления не обойтись. Использование речевого управления не требует специальной подготовки пользователя и позволяет освободить руки и глаза во время взаимодействия с компьютером.
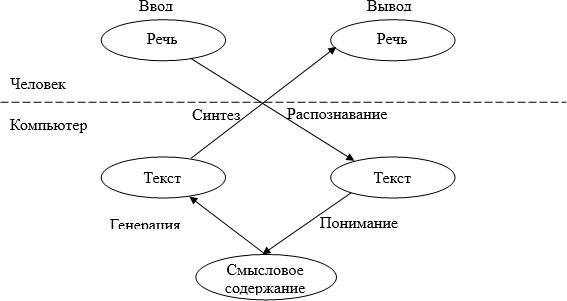
Для реализации голосовых интерфейсов используются автоматические системы распознавания речи, такие системы переводят речь, передаваемую по каналам ввода, в текст. В зависимости от целей взаимодействия распознанный текст может являться требуемым результатом, а может служить входной информацией для систем обработки и понимания текстов на естественном языке.
Можно выделить два основных направления использования голосовых интерфейсов:
- задачи, в которых главным образом требуется распознавание речи:
- простые команды и управление;
- простой ввод данных (по телефону);
- диктант;
- задачи, в которых кроме распознавания речи требуется понимание текста (интерактивный разговор):
- информационные киоски;
- диалоговая обработка запросов;
- интеллектуальные агенты.
Основные сложности, возникающие при автоматическом распознавании речи:
- эффект коартикуляции; (в естественной речи звуки не имеют четких границ, в связи с этим очень сложно определить, где кончается одна фонема и начинается другая, фонемы речи переходят друг в друга плавно и звуковое окружение сильно искажает форму фонемы)(м.б. интересно почитать: [http://lingold.ru/effekt-koartikulyaczii-v-recheobrazovanii, http://habrahabr.ru/post/105512/])
- необходимость настраивать систему автоматического распознавания речи на каждого оратора отдельно, при этом могут возникать проблемы разнообразия диалектов, а также сложности распознавания речи лиц, говорящих на иностранном языке;
- свободная речь: присутствие в речи слов-паразитов и слов, не включенных в словарь;
- необходимость создания модели естественного языка (м.б. интересно почитать: [http://www.textologia.ru/yazikoznanie/teoria-yazikoznania/metod/matematicheskoe-modelirovanie-yazika/1500/?q=641&n=1500]);
- устойчивость к шумам.
Возможности систем автоматического распознавания речи характеризуются следующими параметрами:
- режим речи: может варьироваться от раздельного произношения слов до непрерывной речи;
- стиль речи: варьируется от чтения текста до спонтанной речи;
- подстройка: зависимость от оратора – пользователь до работы с системой должен предоставить образцы своей речи для настройки, с другой стороны независимость от оратора не предполагает никаких настроек до использования системы;
- словарь: набор слов может варьироваться от небольшого объема (< 20 слов) до огромного (> 50000 слов), чем больше словарь или чем больше в нем схожих по звучанию слов, тем сложнее процесс распознавания речи;
- языковая модель: используется в случае, когда речь представлена в виде последовательности слов, самая простая языковая модель может быть определена как сеть с конечным числом состояний, более сложная, но при этом более близкая к естественному языку модель, описывается в терминах контекстно-зависимых грамматик;
- перплексивность (степень неопределенности вероятностной модели): популярная мера сложности задачи, объединяющая размер словаря и языковую модель;
- наконец, существует ряд внешних параметров, которые могут повлиять на производительность системы автоматического распознавания речи, включая характеристики шума окружающей среды, а также размещение и характеристики микрофона.
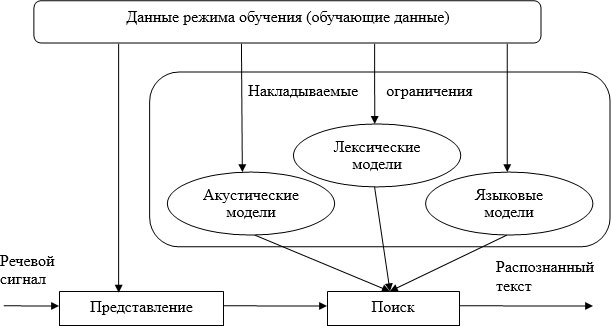
На рис. 6.2 представлены основные компоненты системы распознавания речи. Сначала оцифрованный речевой сигнал разбивается на множество фрагментов фиксированного размера, примерно по 10-20 мс каждый. Для каждого фрагмента подбирается наиболее подходящее слово, в процессе подбора учитываются ограничения, накладываемые акустической, лексической и языковой моделями. Для определения (уточнения) значений параметров моделей в процессе распознавания используются обучающие данные.