|
Попробуйте часть кода до слова main заменить на #include "stdafx.h" //1 #include <iostream> //2 using namespace std; //3 |
Нижегородский государственный университет им. Н.И.Лобачевского
Опубликован: 25.11.2008 | Доступ: свободный | Студентов: 9619 / 1309 | Оценка: 4.06 / 3.66 | Длительность: 21:16:00
Тема: Программирование
Специальности: Программист, Архитектор программного обеспечения
Теги:
Лекция 11:
Работа с файлами
Аннотация: Данная лекция посвящена работе с файлами. Приводятся основные понятия и определения, а также принципы использования файлов в программе
Ключевые слова: именованная область, программа, диск, дисплей, графопостроитель, сканер, система управления файлами, BIOS, Basic, input, output, system, базовая, постоянное запоминающее устройство, ПЗУ, внешнее запоминающее устройство, информация, файл, ПО, байт, размер кластера, таблица, FAT, allocator, table, ссылка, признак конца файла, Eof, винчестер, кластер, пространство, Windows, NTFS, раздел диска, вложенный каталог, скрытый файл, read, FAR, command window, операции, операционная система, система программирования, MS-DOS, управляемый код, direct access, random access, доступ, управляющие, поле, дополнительные расходы, fopen, форматный ввод, fread, дублирование данных, обращение к функции, указатель, массив, константы, класс, атрибут файла, FindFirst, FindNext, адрес, значение, поиск, представление, список, аргумент функции, аргумент, hidden, volume, directory
В большинстве своем файлы представляют собой именованные области внешней (дисковой) памяти, с которыми программы могут обмениваться информацией. Необходимость в таких обменах, во-первых, возникает, когда объем оперативной памяти недостаточен для хранения нужной информации. Во-вторых, программа может воспользоваться данными, полученными ранее другой программой и предусмотрительно записанными на диск. Наконец, в программах, требующих во время своей работы ввод исходных данных достаточно большого объема, целесообразно считывать эти данные из файла – данные в файле можно подготовить заблаговременно и тщательно выверить.
К числу абонентов, которые могут участвовать в обмене данными, относятся и файлы-устройства (дисплей, принтер, графопостроитель, сканер, клавиатура, каналы связи и т.п.). Данный раздел посвящен работе с дисковыми файлами, хотя технология обслуживания файлов- устройств ничем принципиально не отличается.
10.1.Файлы в операционной системе
Система управления файлами является одним из важнейших компонентов операционной системы. На нижнем (физическом) уровне поддержку работы с файлами и устройствами обеспечивает BIOS (Basic Input Output System – базовая система ввода-вывода). Если на ранних моделях IBM-совместимых ПК программы BIOS "прошивались" в постоянном запоминающем устройстве (ПЗУ), то в современных компьютерах программы BIOS можно обновлять. Как правило, программисты напрямую к функциям BIOS не обращаются, предпочитая иметь дело с функциями среднего уровня, которые предоставляются пользователям операционной системой или функциями более высокого уровня, предусмотренными соответствующей системой программирования.
Файловая подсистема рассматривает внешние запоминающие устройства (жесткие и гибкие магнитные диски) как совокупность логических дисков, обозначаемых буквами латинского алфавита – a, b, c, d, ... (или A, B, C, ...). На каждом логическом диске может быть создано корневое оглавление (каталог), где хранится информация о содержимом логического раздела. Минимальной единицей хранения является файл – набор данных, снабженных следующей информацией:
- имя файла, состоящее из букв латинского алфавита, цифр и некоторых символов (максимальная длина имени – 8 символов);
- расширение имени, отделяемое от имени точкой и содержащее до 3 символов;
- дата и время создания файла или момента его последней модификации;
- длина файла в байтах;
- атрибуты файла (A – архивируемый, R – только для чтения, S – системный, H – скрытый);
- ссылка на начало данных – адрес первого кластера, с которого на диске расположена первая порция информационного содержимого файла.
Кластер – это несколько следующих друг за другом секторов дискового пространства (по умолчанию объем каждого физического сектора – 512 байт). Размер кластера зависит от общей емкости накопителя на магнитном диске. Если объем информации в файле превышает объем одного кластера, то следующая порция данных располагается на ближайшем свободном кластере, который физически может не быть смежным с первой порцией данных. Таким образом, большой набор данных оказывается разбросанным по разным не обязательно соседним участкам диска. Для сборки этих разрозненных цепочек и определения адреса последнего кластера с данными используется специальная таблица FAT (File Allocation Table – таблица размещения файлов), где для каждого кластера записана либо ссылка на номер следующего кластера, либо указан признак конца файла (EOF – End-of-File). Чем больше емкость винчестера, тем больше секторов в кластере. Поэтому последний кластер файла обычно бывает заполнен только частично, следовательно, система FAT не самым лучшим образом использует дисковое пространство. В современных операционных системах типа Windows XP поддерживается более эффективная система хранения файловой информации NTFS. Однако и в ней соблюдается древообразное построение каталогов и подкаталогов логических разделов диска.
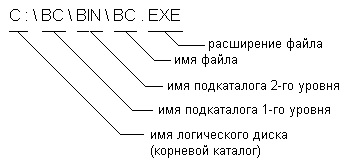
Кроме информации о файлах в корневом каталоге содержатся сведения о вложенных подкаталогах, устроенных по тому же принципу, что и корневой каталог. Вложенные каталоги имеют индивидуальные имена. Поэтому, чтобы добраться до какого-то конкретного набора данных приходится указывать так называемую полную спецификацию файла, состоящую из имени логического диска, цепочки вложенных подкаталогов и собственно имени файла:
При использовании имен файлов в программах на языках C, C++ следует помнить об одном соглашении – спецификация файла задается строкой, в которой знак "обратного слэша" заменяется удвоенным обратным слэшем:
char namef[]="c:\\bc\\bin\\bc.exe"
Файловая подсистема обеспечивает возможность создания новых подкаталогов, создания и удаления файлов, копирования и переименования файлов. Средства операционной системы обеспечивают некоторую защиту наборов данных – например, системные и скрытые файлы не всегда предоставляются взору пользователя, файлы, снабженные атрибутом Read-Only (только для чтения) уничтожаются не по первому нажатию соответствующей клавиши. Однако соответствующие оболочки операционных систем (типа Far, Disco Commander, Windows Commander и т.п.) с легкостью преодолевают такую защиту.
Оценивая ключевые аспекты процесса обмена данными, можно сказать, что работа с файлами, в основном, ограничивается тремя-четырьмя операциями:
- выделение ресурсов и приведение файла в состояние готовности к обмену (именно это скрывается за термином " открыть файл ");
- чтение ( ввод из файла ) или запись ( вывод в файл ) очередной порции данных;
- возврат выделенных ресурсов и завершение неоконченных операций (этому соответствует термин " закрыть файл ").
Несмотря на кажущуюся простоту процесса обмена данными, файловые операции достаточно сложны в освоении. Во-первых, не следует забывать о трех уровнях доступа к файловым данным (BIOS, операционная система, система программирования). Во-вторых, операционные системы MS-DOS, Windows и Linux пытаются достичь совместимости в выполнении файловых операций. Все это приводит к появлению довольно большого количества различных обслуживающих программ. Так, системная библиотека BC 3.1 насчитывает более 120 функций для работы с файлами и свыше 60 констант, задающих режимы работы файловых процедур.
При работе с файлами приходится учитывать многочисленные форматы представления данных того или иного типа на разных носителях информации. Так, например, цепочка из k символов, представляющая текстовую строку, может храниться в одном из следующих форматов:
- "S1S2S3...Sk" (переменное число символов, заключенных в одинарные или двойные кавычки);
- kS1S2...Sk ( k – однобайтовый или двухбайтовый счетчик числа символов, предшествующий тексту);
- S1S2...Sk\0 ( \0 – однобайтовый признак конца строки, расположенный вслед за последним символом текста);
- S1S2...Sk 0D 0A (двухбайтовый признак конца строки, 0D –"возврат каретки", 0A – "перевод строки").
Числовая информация может быть записана в дисковый файл либо в машинном формате (а в языках С, С++ количество разных типов числовых данных достигает десятка), либо с предварительным преобразованием из машинного представления в символьное.
Кроме числовых и текстовых данных в файлах может храниться информация и другого происхождения. Например, графические изображения, которые в процессах обмена данными выступают как двоичные коды, условно разделенные на байты. Естественно, что на содержимое этих байтов нельзя реагировать так же, как на некоторые управляющие коды типа "Возврат каретки", "Перевод строки", "Признак конца файла", влияющие на передачу текстовой информации.
Далее, существует несколько способов доступа к файловым данным, из которых на практике чаще всего используют два – последовательный и произвольный. Последний иногда называют прямым ( DIRECT ACCESS ) или случайным ( RANDOM ACCESS ).
Последовательный доступ при записи на диск характерен тем, что очередная записываемая порция пристраивается в хвост к предыдущей. Размеры смежных порций при этом могут оказаться разными по длине. При чтении такой набор данных начинает извлекаться с самой первой порции и очередность считываемых данных повторяет их последовательность во время записи.
Файлы с произвольным доступом состоят из данных, разбитых на порции фиксированной длины. При этом имеется возможность записывать или читать данные в произвольном порядке, указывая дополнительно номер нужной порции.
Наконец, необходимо учитывать и способы разделения отдельных числовых или символьных значений в дисковых наборах данных. В некоторых ситуациях роль таких разграничителей могут выполнять кавычки, запятые, пробелы и различные управляющие байты ( "табуляторный пропуск", "возврат каретки", "перевод строки", "признак конца файла" ). В других ситуациях для каждого данного может быть выделено поле фиксированной длины.
Системы программирования BC 3.1 и BCB поддерживает работу с файлами и потоками, данные в которых представлены либо в символьном, либо в двоичном формате.
10.1.1. Текстовые (строковые) файлы
Содержимое текстового файла очень напоминает то, что мы видим на экране дисплея, когда программа отображает на нем результаты вычислений. Разница только в том, что на экран дисплея только выводят, а текстовый файл можно использовать как хранилище информации, в которое не только пишут, но из которого еще и читают.
Текстовые файлы относятся к файлам последовательного доступа, т.к. единицей хранения информации в них являются строки переменной длины. Каждая строка заканчивается специальным признаком, обычно его функцию выполняет пара символов 0D0A – "возврат каретки" и "перевод строки". Самым важным преимуществом текстовых файлов является универсальность формата хранения информации – числовые данные в символьном виде доступны на любом компьютере, при необходимости их может прочитать и человек. Однако это преимущество имеет и обратную сторону медали – преобразование числовых данных из машинных форматов в символьный вид при выводе и обратное преобразование при вводе сопряжено с дополнительными расходами. Кроме того, объем числовых данных в символьном формате занимает в несколько раз больше памяти по сравнению с их машинным представлением.
Текстовый файл может быть создан путем записи на диск символьных и/или числовых данных по заданному формату с помощью оператора fprintf. В качестве признака конца строки здесь заносятся те же самые байты 0D0A, которые появляются на диске в результате вывода управляющего символа \n.
Для инициализации текстового файла необходимо завести указатель на структуру типа FILE и открыть файл по оператору fopen в одном из нужных режимов – "rt" (текстовый для чтения), "wt" (текстовый для записи), "at" (текстовый для дозаписи в уже существующий набор данных):
FILE *f1; ......... f1=fopen(имя_файла, "режим");
Формат оператора обмена с текстовыми файлами мало чем отличается от операторов форматного ввода ( scanf ) и вывода ( printf ). Вместо них при работе с файлами используются функции fscanf и fprintf, у которых единственным дополнительным аргументом является указатель на соответствующий файл:
fscanf(f1,"список_форматов", список_ввода); fprintf(f1,"список_форматов \n",список_вывода);
Если очередная строка текстового файла формируется из значения элементов символьного массива str, то вместо функции fprintf проще воспользоваться функцией fputs(f1, str). Чтение полной строки из текстового файла удобнее выполнить с помощью функции fgets(str,n,f1). Здесь параметр n означает максимальное количество считываемых символов, если раньше не встретится управляющий байт 0A.
Библиотека C предусматривает и другие возможности для работы с текстовыми файлами – функции open, create, read, write.
Пример 1. Рассмотрим программу, которая создает в текущем каталоге (т.е. в каталоге, где находится наша программа) текстовый файл с именем c_txt и записывает в него 10 строк. Каждая из записываемых строк содержит символьное поле с текстом "Line" (5 байт, включая нулевой байт – признак конца строки), пробел, поле целочисленного значения переменной j, пробел и поле вещественного значения квадратного корня из j. Очевидно, что числовые поля каждой строки могут иметь разную длину. После записи информации файл закрывается и вновь открывается, но уже для чтения. Для контроля содержимое записываемых строк и содержимое считанных строк дублируется на экране.
#include <stdio.h>
#include <stdlib.h>
#include <math.h>
#include <conio.h>
main( )
{
FILE *f; //указатель на блок управления файлом
int j,k;
double d;
char s[]="Line";
f=fopen("c_txt","wt"); //создание нового или открытие существующего
// файла для записи
for(j=1;j<11;j++)
{
fprintf(f,"%s %d %lf\n",s,j,sqrt(j)); //запись в файл
printf("%s %d %lf\n",s,j,sqrt(j)); //вывод на экран
}
fclose(f); //закрытие файла
printf("\n");
f=fopen("c_txt","rt"); //открытие файла для чтения
for(j=10; j>0; j--)
{
fscanf(f,"%s %d %lf",s,&k,&d); //чтение из файла
printf("%s %d %lf\n",s,k,d); //вывод на экран
}
getch(); return 0;
}
//== Результат работы ===
Line 1 1.000000
Line 2 1.414214
Line 3 1.732051
Line 4 2.000000
Line 5 2.236068
Line 6 2.449490
Line 7 2.645751
Line 8 2.828427
Line 9 3.000000
Line 10 3.162278
Line 1 1.000000
Line 2 1.414214
Line 3 1.732051
Line 4 2.000000
Line 5 2.236068
Line 6 2.449490
Line 7 2.645751
Line 8 2.828427
Line 9 3.000000
Line 10 3.162278
10.1.
Обратите внимание на возможную ошибку при наборе этой программы. Если между форматными указателями %s и %d не сделать пробел, то в файле текст "Line" склеится с последующим целым числом. После этого при чтении в переменную s будут попадать строки вида "Line1", "Line2", , "Line10", в переменную k будут считываться старшие цифры корня из j (до символа "точка"), а в переменной d окажутся дробные разряды соответствующего корня. Тогда результат работы программы будет выглядеть следующим образом:
Line1 1.000000 Line2 1.414214 Line3 1.732051 Line4 2.000000 Line5 2.236068 Line6 2.449490 Line7 2.645751 Line8 2.828427 Line9 3.000000 Line10 3.162278 Line11 0.000000 Line21 0.414214 Line31 0.732051 Line42 0.000000 Line52 0.236068 Line62 0.449490 Line72 0.645751 Line82 0.828427 Line93 0.000000 Line103 0.162278
При считывании данных из текстового файла надо следить за ситуацией, когда данные в файле исчерпаны. Для этой цели можно воспользоваться функцией feof:
if(feof(f1))... //если данные исчерпаны
Alexey Ku
Александр Талеев
|
#include <iostream.h> при запуске в visual express выдает ошибки Ошибка 1 error C1083: Не удается открыть файл включение: iostream.h: No such file or directory c:\users\саня\documents\visual studio 2012\projects\проект3\проект3\исходный код.cpp 1 1 Проект3 2 IntelliSense: не удается открыть источник файл "iostream.h" c:\Users\Саня\Documents\Visual Studio 2012\Projects\Проект3\Проект3\Исходный код.cpp 1 1 Проект3 3 IntelliSense: идентификатор "cout" не определен c:\Users\Саня\Documents\Visual Studio 2012\Projects\Проект3\Проект3\Исходный код.cpp 6 1 Проект3 4 IntelliSense: идентификатор "cin" не определен c:\Users\Саня\Documents\Visual Studio 2012\Projects\Проект3\Проект3\Исходный код.cpp 7 1 Проект3 при создании файла я выбрал пустой проект. Может нужно было выбрать консольное приложение?
|