|
Попробуйте часть кода до слова main заменить на #include "stdafx.h" //1 #include <iostream> //2 using namespace std; //3 |
Лекция 9:
Работа с массивами
8.4. Поиск
Задача поиска формулируется следующим образом: задан массив a, содержащий n однотипных элементов (чисел, строк, записей и т.п.). Нужно установить, содержится ли в этом массиве заданный объект q. При положительном ответе следует дополнительно сообщить порядковый номер (индекс j ), найденного объекта ( a[j]=q ).
8.4.1. Последовательный поиск
Классический алгоритм последовательно поиска в неупорядоченном массиве состоит из четырех следующих шагов:
- шаг S1: Установить начальный индекс j=1 ;
- шаг S2: Проверить условие q=a[j]. Если условие выполнено, то решение найдено и работа прекращается;
- шаг S3: Увеличить индекс j на 1;
- шаг S4: Проверить условие окончания цикла j<n+1. Если условие выполнено, повторяется шаг S2. В противном случае сообщить, что объект q в массиве a не содержится.
В книге Д.Кнута "Искусство программирования" имеется упоминание об
усовершенствовании приведенного выше алгоритма. В цикле этого
алгоритма содержится два сравнения. Чтобы исключить одно из них
(условие окончания цикла) к массиву a добавляют еще один элемент,
равный q. Тогда необходимость в проверке j<n+1 отпадает. Перед выдачей
результата надо убедиться в том, что найденный индекс не равен n+1. Но
такая проверка выполняется всего один раз. При программировании на
языке ассемблера не требуется добавлять a[n+1]. Проще организовать
поиск в обратном порядке – с последнего элемента массива. Для этого в
языке ассемблера используется команда LOOP, совмещающая изменение
счетчика цикла ( j-- ) и возврат в начало цикла при  .
.
Трудоемкость классического последовательного поиска можно оценить только в среднем. В лучшем случае первое же сравнение может дать ответ ( q=a[1] ). В худшем случае придется перебрать все n элементов. В среднем на поиск будет затрачено n/2 сравнений.
Функция ssearch, реализующая последовательный поиск, устроена довольно просто:
int ssearch(int q, int *a, int n)
{ register int j;
for(j=0; j<n;j++)
if(q==a[j]) return j;
return -1;
}Единственная особенность, направленная на повышение скорости поиска, связана с попыткой распределить счетчик цикла j в машинном регистре (если у компилятора имеется в наличии свободный регистр, то он положительно среагирует на объявление register int j ).
8.4.2. Двоичный поиск
Двоичный поиск можно применить только в том случае, если исходный массив упорядочен, например, по возрастанию величин объектов. Тривиальные случаи типа q<a[1] или q>a[n] не рассматриваются, хотя ничего не стоит подключить к поиску и такие проверки. Идея двоичного поиска заключается в уменьшении вдвое зоны поиска на каждом шаге (отсюда и второе название метода – деление пополам). Сначала искомый объект q сравнивается со средним элементом массива. В зависимости от результата сравнения на следующий шаг остается первая или вторая половина массива. Оставшаяся половина вновь делится на 2, и так продолжается до тех пор, пока зона поиска не сузится до двух элементов. В этом случае либо объект q совпадает с одним из этих элементов, либо продолжает сохраняться строгое неравенство с обеими границами.
Функция bsearch, реализующая двоичный поиск, может быть организована следующим образом:
int bsearch(int q, int *a, int n)
{ register int left=0,right=n-1,mid;
if(q<a[0] || q>a[n-1]) return -1;
for(;left<=right;)
{ mid=(left+right)/2;
if(q<a[mid]) right=mid-1;
else if(q>a[mid]) left=mid+1;
else return mid;
}
return -1;
}Максимальное количество шагов, которое требуется для двоичного поиска, оценивается ближайшим целым к log2n. Для массива в 1000 элементов прямой поиск в среднем затрачивает 500 шагов, тогда как двоичный поиск ограничивается 10 шагами.
В реальных задачах типа поиска в телефонном справочнике к массиву данных можно добавить несколько отсортированных массивов-указателей – по фамилиям, по телефонам, по адресам. Сам массив исходных данных при этом не сортируется.
8.5. Сортировка массивов.
Сортировка числовых и нечисловых данных – одна из важнейших процедур обработки информации, т.к. она существенно ускоряет последующий поиск тех или иных объектов. О том, какое внимание уделяется различным алгоритмам сортировки, свидетельствует специальный том Д.Кнута "Искусство программирования для ЭВМ: Сортировка и поиск" объемом порядка 840 стр. Надо отметить, что оценка трудоемкости различных методов сортировки представляет собой довольно сложную математическую задачу. Те оценки, которые приведены ниже, заимствованы из литературных источников.
Мы рассмотрим несколько разных алгоритмов сортировки – от самых простых и самых медленных до одного из наиболее эффективных.
8.5.1. Сортировка методом пузырька
Идея метода состоит в сравнении двух соседних элементов, в результате чего меньшее число (более легкий "пузырек") перемещается на одну позицию влево. Обычно просмотр организуют с конца, и после первого прохода самое маленькое число перемещается на первое место. Затем все повторяется от конца массива до второго элемента и т.д. Известен и другой вариант пузырьковой сортировки, в котором также сравнивают два соседних элемента, и если хотя бы одна из смежных пар была переставлена, то просмотр начинают с самого начала.
Функция bubble, реализующая первый алгоритм пузырьковой сортировки приведена ниже:
void bubble(int *x, int n)
{ register int i,j;
int tmp;
for(i=1;i<n;i++)
for(j=n-1;j>=i; j--)
if(x[j-1]>x[j])
{ tmp=x[j-1]; x[j-1]=x[j]; x[j]=tmp; }
}Более известный алгоритм пузырьковой сортировки реализован в функции bubble1. В ней использована флажковая переменная q, которая принимает ненулевое значение в случае перестановки какой-либо смежной пары:
void bubble1(int *x, int n)
{ register int i,j;
int tmp,q;
m: q=0;
for(i=1;i<n-1;i++)
if(x[i]>x[i+1])
{ tmp=x[i]; x[i]=x[i+1]; x[i+1]=tmp; q=1;}
if(q) goto m;
}Пузырьковая сортировка неплохо работает, когда в исходных данных многие элементы уже упорядочены. Если исходный массив уже отсортирован, то работа функции ограничивается первым проходом. В худшем случае (массив упорядочен по убыванию) количество сравнений составляет n*(n-1)/2, а количество перестановок достигает 3*n*(n-1)/2. Среднее количество перестановок равно 3*n*(n-1)/4.
8.5.2. Сортировка методом отбора
Идея метода: находится элемент с наименьшим значением и меняется местами с первым элементом. Среди оставшихся элементов ищется наименьший, который меняется со вторым и т.д. Функция select, реализующая такую процедуру, приведена ниже:
void select(int *x, int n)
{ register int i,j,k;
int q,tmp;
for(i=0; i<n-1;i++)
{ q=0; k=i; tmp=x[i];
for(j=i+1; j<n; j++)
{ if(x[j]<tmp)
{ k=j; tmp=x[j]; q=1; }
}
if(q) { x[k]=x[i]; x[i]=tmp; }
}
}Оценка трудоемкости метода отбора:
- количество сравнений – n*(n-1)/2 ;
- количество перестановок:
- в лучшем случае – 3*(n-1)
- в худшем случае – n2/4+3*(n-1)
- в среднем – n*(log n +0.577216)
8.5.3. Сортировка методом вставки
Идея метода: последовательное пополнение ранее упорядоченных элементов. На первом шаге сортируются два первых элемента. Затем на свое место среди них вставляется третий элемент. К трем упорядоченным добавляется четвертый, который занимает свое место в четверке и т.д. Примерно так игроки упорядочивают свои карты при сдаче их по одной. Функция insert, реализующая описанную процедуру, приведена ниже:
void insert(int *x, int n)
{ register int i,j;
int tmp;
for(i=1;i<n;i++)
{ tmp=x[i];
for(j=i-1;j>=0 && tmp<x[j]; j--)
x[j+1]=x[j];
x[j+1]=tmp;
}
}Трудоемкость метода: количество сравнений зависит от исходной упорядоченности массива. Если массив уже отсортирован, то все равно потребуется 2*(n-1) сравнение. Если массив упорядочен по убыванию, то число сравнений возрастает до n*(n+1)/2.
8.5.4. Сортировка методом Шелла
В 1959 году сотрудник фирмы IBM D.L. Shell предложил оригинальный
алгоритм сортировки. По его предложению сначала сортируются элементы,
отстоящие друг от друга на 3 позиции, затем – на две позиции и,
наконец, сортируются смежные элементы. В дальнейшем экспериментальным
путем были найдены более удачные расстояния между сортируемыми
элементами: 9 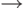 5 3 2 1. Среднее время работы усовершенствованного
алгоритма Шелла порядка n1.2. Это существенно лучше, чем характерная
для трех предыдущих методов величина порядка n2.
5 3 2 1. Среднее время работы усовершенствованного
алгоритма Шелла порядка n1.2. Это существенно лучше, чем характерная
для трех предыдущих методов величина порядка n2.
void shell(int *x, int n)
{ register int i,j,gap,k;
int xx;
char a[5]={9,5,3,2,1};
for(k=0;k<5;k++)
{ gap=a[k];
for(i=gap;i<n;i++)
{ xx=x[i];
for(j=i-gap; xx<x[j] && j>=0; j=j-gap)
x[j+gap]=x[j];
x[j+gap]=xx;
}
}
}8.5.5.Быстрая сортировка
Известный математик C.A.R. Hoare в 1962 году опубликовал алгоритм быстрой сортировки, за которым закрепилось название quicksort. Основная идея быстрой сортировки напоминает метод поиска делением пополам. Сначала выбирается средний элемент в сортируемом массиве. Все, что больше этого элемента переносится в правую часть массива, а все, что меньше – в левую. После первого шага средний элемент оказывается на своем месте. Затем аналогичная процедура повторяется для каждой половины массива. На каждом последующем шаге размер обрабатываемого фрагмента массива уменьшается вдвое. Количество операций, которое требуется для реализации этой процедуры, оценивается константой n*log2n. Это еще быстрее, чем сортировка Шелла. В отличие от предыдущих функций быстрая сортировка оформлена из двух функций – quick, которая допускает принятое в других функциях обращение, и рекурсивной процедуры qs:
void quick(int *x, int n)
{ qs(x,0,n-1); }
//----------------------------------
void qs(int *x,int left,int right)
{ register int i,j;
int xx,tmp;
i=left; j=right;
xx=x[(left+right)/2];
do { while(x[i]<xx && i<right)i++;
while(xx<x[j] && j>left) j--;
if(i<=j)
{ tmp=x[i]; x[i]=x[j];
x[j]=tmp; i++; j--;
}
}
while(i<=j);
if(left<j) qs(x,left,j);
if(i<right)qs(x,i,right);
}Головная программа, предназначенная для тестирования и хронометража функций сортировки, приведена ниже. Заложенная в ней константа MAX для целей отладки принимает значение 20. Для хронометража методов сортировки ее надо увеличить до 100000 (BCB массивы такого размера допускает).
#include <iostream.h>
#include <conio.h>
#include <dos.h>
#define MAX 20
void bubble(int *x,int n);
void select(int *x,int n);
void insert(int *x,int n);
void shell(int *x,int n);
void quick(int *x,int n);
void qs(int *x,int left,int right);
void main()
{ int num[MAX],i;
int t1,t2;
/* при отладке включить этот фрагмент
cout << "Before sort:\n";
for(i=0; i<MAX; i++)
{ num[i]=random(MAX);
cout << num[i] << " ";
}
cout << endl;
*/
t1=GetTickCount();
// bubble(num,MAX);
// select(num,MAX);
// insert(num,MAX);
// shell(num,MAX);
quick(num,MAX);
t2=GetTickCount();
cout << t2-t1;
/* при отладке включить этот фрагмент
cout << "After sort:" << endl;
for(i=0; i<MAX; i++)
cout << num[i] << " ";
cout << endl;
*/
cout << "end";
getch();
}
//Методы сортировкиВ таблице 8.1 приведены данные работы каждой функции сортировки на массиве длиной в 100000 элементов на компьютере типа Pentium 4 (частота 2 ГГц). Сортируемый массив заполнялся случайными числами (для каждой функции набор исходных данных был одинаков).
Alexey Ku
Александр Талеев
|
#include <iostream.h> при запуске в visual express выдает ошибки Ошибка 1 error C1083: Не удается открыть файл включение: iostream.h: No such file or directory c:\users\саня\documents\visual studio 2012\projects\проект3\проект3\исходный код.cpp 1 1 Проект3 2 IntelliSense: не удается открыть источник файл "iostream.h" c:\Users\Саня\Documents\Visual Studio 2012\Projects\Проект3\Проект3\Исходный код.cpp 1 1 Проект3 3 IntelliSense: идентификатор "cout" не определен c:\Users\Саня\Documents\Visual Studio 2012\Projects\Проект3\Проект3\Исходный код.cpp 6 1 Проект3 4 IntelliSense: идентификатор "cin" не определен c:\Users\Саня\Documents\Visual Studio 2012\Projects\Проект3\Проект3\Исходный код.cpp 7 1 Проект3 при создании файла я выбрал пустой проект. Может нужно было выбрать консольное приложение?
|