|
Здравствуйте! Записался на ваш курс, но не понимаю как произвести оплату. Надо ли писать заявление и, если да, то куда отправлять? как я получу диплом о профессиональной переподготовке? |
Инспектор
Вы можете этот курс.
Опубликован: 05.03.2005 | Уровень: специалист | Доступ: платный
Лекция 13:
Регрессионное тестирование: методики, не связанные с отбором тестов и методики порождения тестов
Порождение новых тестов
Порождение новых тестов при структурном регрессионном тестировании обычно обусловлено недостаточным уровнем покрытия. Новые тесты разрабатываются так, чтобы задействовать еще не покрытые участки исходного кода. Процесс прекращается, когда уровень покрытия кода достигает требуемой величины (например, 80%). Разработка новых тестов при функциональном регрессионном тестировании является менее тривиальной задачей и обычно связана с вводом новых требований либо с желанием проверить некоторые сценарии работы системы дополнительно.
Основой большинства программных продуктов для управляющих применений, находящихся в промышленном использовании, является цикл обработки событий. Сценарий работы с системой, построенной по такой архитектуре, состоит из последовательности транзакций, управление после обработки каждой транзакции вновь передается циклу обработки событий. Выполнение транзакции приводит к изменению состояния программы; в результате некоторых транзакций происходит выход из цикла и завершение работы программы. Тесты для таких программ представляют собой последовательность транзакций.
Развитие программного продукта от версии к версии влечет за собой появление новых состояний. Поскольку большинство тестов легко может быть расширено путем добавления дополнительных транзакций в список, новые тесты можно создавать путем суперпозиции уже имеющихся, с учетом информации об изменении состояния тестируемой системы в результате прогона теста. Этот подход позволяет указать, какого рода новые тесты с наибольшей вероятностью обнаружат ошибки.
Обозначим тестируемую программу P, а множество ее тестов T = {t1, t2, … , tn}. Будем считать, что состояние тестируемой программы s определяется совокупностью значений некоторого подмножества глобальных и локальных переменных. При создании новых тестов будем рассматривать состояния программы перед запуском теста ( s0 ) и после его окончания ( sj ). Информацию об этих состояниях необходимо собирать для каждого теста по результатам запуска на предыдущей версии продукта. Методика порождения новых тестов на основе анализа "подозрительных" состояний сводится к описанной ниже последовательности действий.
- Вычисление списка глобальных и локальных переменных, определяющих состояние программы s.
- Сбор информации (на основе анализа профиля программы, полученного на предыдущей версии продукта i-1, для каждого существующего теста tj ) о состояниях программы перед запуском теста и после его окончания (т.е. s0 и sj ). Множество таких состояний обозначается
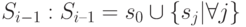
- Выполнение на текущей версии продукта i новых и выбранных регрессионных тестов из множества T’. По аналогии с Si–1 вычисляется множество Si, которое сохраняется под управлением системы контроля версий.
- Оценка "подозрительных" с точки зрения наличия ошибок множества новых по сравнению с предыдущими версиями состояний Ni в соответствии со следующей формулой: Ni = Si \ Si - 1
- Анализ состояний множества Ni, в которых дальнейшая работа продукта невозможна в соответствии со спецификацией. Предмет анализа - определить создаются ли эти состояния в результате выполнения тестов, проверяющих нештатные режимы работы продукта, или каких-либо других тестов. В последнем случае фиксируется ошибка.
- Исключение нештатных состояний из множества Ni.
- Переход к шагу 10, если новых состояний, допускающих продолжение выполнения программы, не обнаружено, т.е.
 .
. - Для каждого состояния множества Ni вычисление вектора отличия от исходного состояния s0, т.е. множества переменных, измененных по сравнению с s0.
- Модификация множества измененных строк исходного кода P на основе информации об измененных переменных и использование какой-либо методики отбора тестов для выборочного регрессионного тестирования.
- Повторное выполнение шагов 3-9 до достижения состояния либо до истечения времени, отведенного на регрессионное тестирование. Использование методов разбиения на классы эквивалентности для досрочного принятия решения о прекращении цикла тестирования, если ни один из тестов, созданных на очередном этапе, не принадлежит к новому классу эквивалентности.
Для приведенной методики организации тестирования, когда новые тесты получаются в результате суперпозиции уже имеющихся, целесообразно в качестве исходных тестов, т.е. тех "кирпичиков", из которых будут строиться тесты в дальнейшем, брать тесты, заключающие всего одну элементарную проверку. Это помогает избежать избыточности при многократном слиянии тестов, когда искомые "подозрительные" ситуации возникают в ходе работы теста, но не анализируются, так как не повторяются при его завершении.
Использование описанной методики позволяет в программном комплексе находить ошибки, не обнаруживаемые исходным набором тестов. Отметим, что применение предложенного подхода невозможно для программ, понятие состояния для которых не определено.