| Россия |
Инспектор
Вы можете этот курс.
Опубликован: 23.07.2006 | Уровень: специалист | Доступ: платный
Лекция 15:
Выбор инструкций при генерации кода
Согласование размещений
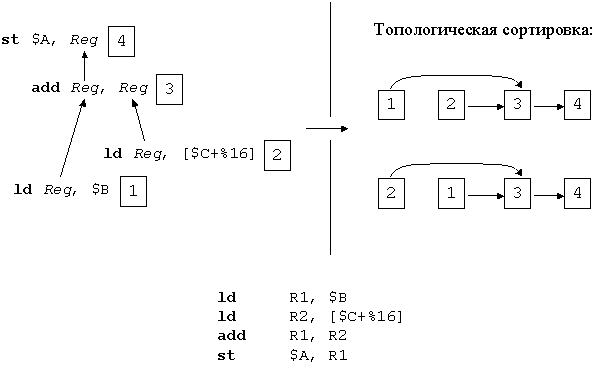
Действия на предыдущем шаге позволяют от исходного размеченного дерева перейти к дереву, в котором вершины уже соответствуют машинным инструкциям, но их операнды еще известны не полностью. Каждая машинная инструкция уже обладает мнемоникой и теми операндами, которые определены на предыдущем шаге (таковыми операндами, например, являются глобальные переменные, регистры, которые необходимо использовать из соображений соглашений о связях и вызовах и т.д.) Дуги в этом дереве обозначают передачу данных через временные значения и таким образом представляют необходимую информацию для согласования размещений.
Для получения финального кода требуется построить подходящую топологическую сортировку этого дерева (возможные сортировки показаны справа) и осуществить окончательное распределение регистров.
Финальный код после этих двух преобразований показан внизу иллюстрации. Заметим, что в случае неудачного распределения регистров выбор команд не может быть сохранен в изначальном виде (потребуется изменение размещений каких-то значений) и код, таким образом, станет субоптимальным.
Пример использования BURS
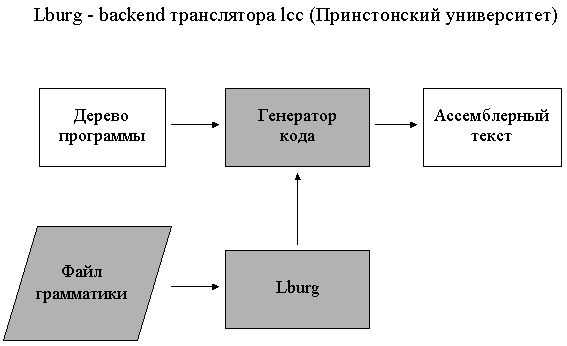
Использование технологии BURS мы продемонстрируем на примере организации backend'а транслятора lcc, разработанного в Принстонском университете.
В основе backend'а лежит средство lburg, которое порождает текст генератора кода на языке C по входному файлу, содержащему описание BURS-грамматики и некоторых вспомогательных функций, необходимых, например, для оформления ассемблерного текста и т.д.
Заметим, что реализация backend'а в трансляторе lcc содержит встроенный механизм распределения регистров. Таким образом, чтобы осуществить раскрутку транслятора на новую архитектуру, необходимо поменять один только файл.
Организация входного файла lburg
%{
...
--- пролог
...
%}
...
Описание стартового нетерминала
Описание терминалов
...
%%
...
--- Описания правил
...
%%
...
--- эпилог
...Входной файл lburg организован согласно традиционной схеме представления грамматик в средствах типа YACC (см. "Грамматики и YACC" ). Он поделен на следующие секции:
- пролог - содержит произвольный текст на языке реализации (в данном случае C)
- описание терминалов и стартового нетерминала грамматики
- описания правил, снабженных семантиками
- эпилог, также содержащий неформальный текст на языке реализации
При обработке lburg порождает по описанию грамматики функции разметки и свертки (при этом свертка использует заданные в правилах семантики), а пролог и эпилог соответственно просто копируются в начало и конец порожденного генератора кода.