
|
Подскажите, пожалуйста, планируете ли вы возобновление программ высшего образования? Если да, есть ли какие-то примерные сроки? Спасибо! |
Инспектор
Вы можете этот курс.
Опубликован: 20.12.2010 | Уровень: специалист | Доступ: платный
Лекция 17:
SQL в хранилищах данных: аналитическая обработка данных
CASE-выражения и создание гистограмм
Синтаксис предложения CASE и некоторые его применения были рассмотрены в "Проектирование и разработка процесса ETL" . С помощью предложения CASE можно легко найти среднюю зарплату всех сотрудников организации (если зарплата меньше 2000 руб., то она принимается равной 2000 руб.), как показано в запросе ниже:
SELECT AVG(CASE when e.sal > 2000 THEN e.sal ELSE 2000 end) FROM emps e;
Таблица "Сотрудники" (emps) включает в себя колонки "Табельный номер" (empid), "ФИО" (name), "Должность" (job) и "Зарплата" (sal), как показано на рис. 23.7.
Предложение CASE можно использовать при построении диаграмм для определенных пользователем бакетов (и по числу бакетов и по ширине каждого бакета). В первом примере ниже строится гистограмма итоговых сумм (totals) в нескольких колонках и выводится одной строкой. Во втором примере гистограмма показывается с колонкой метки, одной колонкой для итоговой суммы (totals) и выводится с помощью нескольких строк.
Пример 23.11. Построение гистограммы.
Пусть необходимо построить гистограмму распределения покупателей по возрастным группам для людей преклонного возраста. Возрастные группы определяются следующими условиями: 70-79, 80-89, 90-99, 100+.
Следующий запрос решает поставленную задачу (предполагается, что таблица "Покупатели" (customer) содержит колонку "Возраст" (age)):
SELECT SUM(CASE WHEN age BETWEEN 70 AND 79 THEN 1 ELSE 0 END) as "70-79", SUM(CASE WHEN age BETWEEN 80 AND 89 THEN 1 ELSE 0 END) as "80-89", SUM(CASE WHEN age BETWEEN 90 AND 99 THEN 1 ELSE 0 END) as "90-99", SUM(CASE WHEN age > 99 THEN 1 ELSE 0 END) as "100+" FROM customer;
Результат выполнения внешнего запроса приведен ниже.
Вывод 11.
Следующий запрос решает ту же задачу, но выводит гистограмму в виде "столбика".
Пример 23.12.
SELECT CASE WHEN age BETWEEN 70 AND 79 THEN '70-79' WHEN age BETWEEN 80 and 89 THEN '80-89' WHEN age BETWEEN 90 and 99 THEN '90-99' WHEN age > 99 THEN '100+' END) as age_group, COUNT(*) as age_count FROM customer GROUP BY CASE WHEN age BETWEEN 70 AND 79 THEN '70-79' WHEN age BETWEEN 80 and 89 THEN '80-89' WHEN age BETWEEN 90 and 99 THEN '90-99' WHEN age > 99 THEN '100+' END);
Результат выполнения внешнего запроса приведен ниже.
Вывод 12.
Статистические функции в других диалектах SQL
В заключение нужно отметить, что некоторые СУБД имеют в своих диалектах SQL боле широкий набор статистических функций, оконных функций, функций ранжирования и функций генерирования отчетов. Например, в СУБД Oracle 11g имеется набор функций для построения линейной регрессии.
Приведем в качестве примера краткий обзор функций построения линейной регрессии для СУБД семейства Oracle.
Функции регрессий устанавливают соответствие по обычному методу наименьших квадратов (ordinary-least-squares) — линию регрессии для набора пар чисел. Данные функции применяются к набору пар of (e1, e2) после проверки всех пар на равенство нулевому значению (либо e1, либо e2)l. e1 — значение зависимой переменной ("y-значение"), а e2 — значение независимой переменной ("x-значение"). Оба выражения должны быть числовыми. Функции регрессии вычисляются за один проход по всем данным.
Перечень функций линейной регрессии дан в табл. 23.5.
| Функция | Действие |
|---|---|
| REGR_COUNT | Функция REGR_COUNT возвращает количество ненулевых пар, которые участвуют в построении линии регрессии. Если все пары (e1, e2) нулевые (либо e1, либо e2 равны нулю), функция возвращает 0 |
| REGR_AVGX REGR_AVGY | Функции REGR_AVGY и REGR_AVGX вычисляют среднее значение (averages) независимой и зависимой переменных линии регрессии соответственно. Функция REGR_AVGY вычисляет среднее первого аргумента (e1) после проверки пар (e1, e2) на нулевое значение (см. выше). Аналогично, функция REGR_AVGX вычисляет среднее для второго аргумента (e2). Обе функции возвращают нуль, если на входе задано пустое множество |
| REGR_SLOPE | Функция REGR_SLOPE вычисляет тангенс угла наклона линии регрессии, соответствующей ненулевым парам (e1, e2) |
| REGR_INTERCEPT | Функция REGR_INTERCEPT вычисляет отсечение на оси Y. Возвращает NULL, если тангенс угла наклона или среднее значение равны NULL |
| REGR_R2 | Функция REGR_R2 вычисляет коэффициент детерминации для линии регрессии (после проверки пар (e1, e2) на нуль) |
| REGR_SXX | Функция REGR_R2 возвращает значения из интервала [0, 1], если регрессия определена, или NULL — в противном случае |
| REGR_SYY REGR_SXY | Функции REGR_SXX, REGR_SYY и REGR_SXY используются для вычисления различных диагностических статистик регрессионного анализа |
Пример 23.13. Вычисления линейной регрессии.
В примере вычисляется регрессия по методу наименьших квадратов, которая показывает премиальные сотрудников как линейную функцию их зарплаты. Величины SLOPE, ICPT, RSQR — наклон, пересечение и коэффициент детерминации регрессии, соответственно. Значения AVGSAL и AVGBONUS есть средняя зарплата и средний размер премий сотрудников, соответственно, а целочисленная величина CNT есть число сотрудников в отделе, для которого вычисления проводятся.
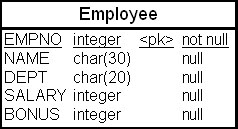
Пусть имеется таблица "Сотрудники" (Employee) с колонками "Табельный номер" (EMPNO), "ФИО" (NAME), "Отдел" (DEPT), "Зарплата" (SALARY), "Премии" (BONUS) ( рис. 23.8). Таблица содержит восемь сотрудников (табл. 23.6).
| Табельный номер | ФИО | Отдел | Заплата | Премия |
|---|---|---|---|---|
| 45 | Петров | Продажи | 4500 | 500 |
| 52 | Иванов | Продажи | 4300 | 450 |
| 41 | Ивлев | Продажи | 5600 | 800 |
| 65 | Кузнецова | Продажи | 3200 | |
| 36 | Александров | Оборудование | 6700 | 1150 |
| 58 | Самгин | Оборудование | 3000 | 350 |
| 25 | Ворошилов | Оборудование | 8200 | 1860 |
| 54 | Васильев | Оборудование | 6000 | 900 |
Следующий запрос вычисляет параметры линейной регрессии.
SELECT REGR_SLOPE(BONUS, SALARY) SLOPE,
REGR_INTERCEPT(BONUS, SALARY) ICPT,
REGR_R2(BONUS, SALARY) RSQR,
REGR_COUNT(BONUS, SALARY) COUNT,
REGR_AVGX(BONUS, SALARY) AVGSAL,
REGR_AVGY(BONUS, SALARY) AVGBONUS,
REGR_SXX(BONUS, SALARY) SXX,
REGR_SXY(BONUS, SALARY) SXY,
REGR_SYY(BONUS, SALARY) SXY
FROM employee
GROUP BY dept;Результаты выполнения запроса приведены ниже.
Вывод 13.
| SLOPE | ICPT | RSQR | CNT | AVGSAL | AVGBONUS |
|---|---|---|---|---|---|
| 2759379 | -583.729 | 9263144 | 4 | 5975 | 1065 |
| 2704082 | -714.626 | 9998813 | 3 | 4800 | 583.33333 |
Резюме
В настоящей лекции мы изучили ряд функций SQL, используемых при аналитической обработке данных в ХД и киосках данных. Это статистические функции, ранжирующие функции и оконные функции.
Статистические функции выполняют вычисление на наборе значений и возвращают одиночное значение. Они, за исключением функции COUNT, не учитывают значения NULL. Также они часто используются в выражении GROUP BY команды SELECT.
Функции ранжирования вычисляют ранг записи по отношению к другим записям в наборе данных, основываясь на значении набора метрик таблиц фактов ХД. Они возвращают ранжирующее значение для каждой строки в секции. В зависимости от используемой функции значения некоторых строк могут совпадать.
Оконные функции могут использоваться для вычисления кумулятивных, скользящих и центрированных агрегатов. Они возвращают значение для каждой строки в таблице, которое зависит от других строк соответствующего окна. Они могут быть использованы только в предложениях SELECT и ORDER BY запроса. Как правило, оконные функции обеспечивают доступ более чем к одной строке таблицы без самосоединения.
Был также рассмотрен ряд примеров применения вышеперечисленных функций для генерирования отчетных данных, а в сочетании с CASE-выражением — для построения гистограмм.
Проектировщику ХД очень полезно знать возможности аналитической обработки данных в SQL для более качественного проектирования схем данных ХД и определения гранулированности таблиц фактов.
Владислав Нагорный
Лариса Парфенова
|
1) Можно ли экстерном получить второе высшее образование "Программная инженерия" ? 2) Трудоустраиваете ли Вы выпускников? 3) Можно ли с Вашим дипломом поступить в аспирантуру?
|