|
Подскажите, пожалуйста, планируете ли вы возобновление программ высшего образования? Если да, есть ли какие-то примерные сроки? Спасибо! |
Инспектор
Вы можете этот курс.
Опубликован: 20.12.2010 | Уровень: специалист | Доступ: платный
Лекция 16:
SQL в хранилищах данных: агрегация и суммирование
Расширение оператора SELECT для обработки данных
Расширения для оператора SELECT в реляционных СУБД
Производители промышленных реляционных СУБД стремятся расширить возможности аналитической обработки данных в своих диалектах SQL. Обычно расширение таких возможностей SQL выполняется в следующих направлениях:
- расширение возможностей аналитической обработки в рамках предложения GROUP BY оператора SELECT — предложения ROLLUP и CUBE ;
- новые семейства встроенных функций SQL для аналитической обработки данных;
- добавление встроенных функций для линейных регрессионных моделей данных;
- добавление CASE-выражения для поддержки ветвления обработки в SELECT.
Предложения CUBE и ROLLUP делают выполнение запросов и построение отчетов проще в среде ХД. Предложение ROLLUP создает промежуточные суммы (subtotals) в соответствии с возрастающим уровнем агрегации, от наиболее детализированных уровней представления данных к более обобщенным суммам. Предложение CUBE является расширением, подобным предложению ROLLUP, позволяющим в одной команде вычислить все возможные комбинации промежуточных сумм. Предложение CUBE может генерировать информацию, необходимую для перекрестных отчетов (cross-tabulation reports), в одном запросе.
Аналитические функции увеличивают потенциал SQL в области статистической обработки данных результирующих множеств запросов. Функции ранжирования включают в себя вычисление кумулятивных распределений, процентных рангов (percent rank) и разбиений на заданное число групп (N-tiles). Вычисления в плавающих окнах (moving window) позволяют работать с кумулятивными агрегатами (moving and cumulative aggregations), такими как суммы и средние величины.
Другие расширения SQL включают в себя семейство функций для вычисления регрессий и CASE-выражения. Функции вычисления регрессий включают и полный набор вычислений для линейной регрессии. CASE-выражения обеспечивают реализацию логики if – then.
Расширение SQL для агрегации данных
Многомерный анализ данных
Одной из ключевых концепций систем поддержки принятия решений (DSS) и информационных систем руководителя (EIS) является многомерный анализ — анализ объекта во всех необходимых комбинациях измерений. Термин "Измерение" (dimension) применяется для обозначения любой категории, используемой для спецификации запроса. Примерами измерений в ХД чаще всего выступают "Время", "География", "Товар", "Подразделение" и "Канал распределения". События или объекты, связанные с конкретными значениями измерений, принято называть фактами. Примерами фактов могут служить "Продажи", "Прибыль", "Количество клиентов", "Объем продукции".
Типичными примерами вопросов в многомерном анализе являются такие, которые мы будем называть многомерными запросами (MDQ).
- Показать итоговые продажи всего товара по возрастанию уровня агрегации измерения "География": от области к стране, к региону по возрастанию: от области к региону, к стране за период от 1998 г. до 1999 г.
- Создать перекрестный отчет (cross-tabular) операций организации, показывающий расширение территории торговых операций в Южной Америке за 2004-2008 гг. Включить в него все возможные промежуточные суммы.
- Показать список 10 самых крупных продаж (top 10 sales) в Азии в соответствии с прибылью от продаж за 2008 год для автомобилей и ранжировать их по комиссионным.
Во всех перечисленных вопросах используется несколько измерений. Во многих MDQ требуется агрегировать данные по времени, географии или финансам и сравнивать полученные наборы данных.
Для визуализации данных, которые имеют несколько измерений, аналитики используют аналогию с кубом данных (data cube), т.е. часть многомерного пространства, в котором факты сохраняются на пересечении n-измерений. Например, куб может хранить данные о продажах, организованные в трех измерениях — "Товар", "Рынок сбыта" и "Время".
Вы можете разворачивать (делать сечения) данные (slices of data) из куба. Это соответствует перекрестному отчету, показанному в табл. 22.7. Например, региональный менеджер может изучать данные, сравнивая сечения куба по различным рынкам. Менеджер по товарам может сравнивать сечения куба по различным продуктам.
Ответы на MDQ часто требуют доступа к большому количеству данных, агрегации этих данных по уровням иерархии измерений, вычислении частичных сумм по измерениям. Таким образом, аналитические задачи требуют эффективной и удобной агрегации данных.
Возможности агрегирования данных используются не только в многомерном анализе. Обработка транзакций, например, в финансовых или производственных системах (ERP), также генерирует большое число отчетов. Эффективность таких систем возрастает, когда создание отчетов не очень ограничивает нагрузку на систему. В практике финансовых и ERP-систем большое количество отчетов генерируется в ночное время, когда число пользователей таких систем значительно снижается. Важно, что проектировщики БД и ХД должны решать задачу оптимизации запросов, которые используют агрегацию и суммирование данных на различных уровнях их детализации, и в частности такие задачи, как:
- упрощение программирования за счет сокращения кода SQL;
- ускорение обработки запросов;
- сокращение объема процесса загрузки клиентов и сетевого трафика за счет перемещения процесса агрегации данных на серверы БД;
- использование кеширования для агрегатов в случае однотипных запросов.
Для иллюстрации расширений SQL в настоящей лекции мы взяли гипотетическое ХД организации, которая продает и сдает напрокат видеокассеты. В ХД сохраняется информация о действиях организации в нескольких регионах, отлеживаются продажи и прибыль с продаж. Данные сохраняются в трех измерениях – "Время" (Time), "Отдел продаж" (Department) и "Регион" (Region). Временной период данных составляет период от 2000 года до 2009 года. В компании имеется два типа отделов продаж – "Отдел розничных продаж" (Video Sales) и "Отдел видеопроката" (Video Rentals). Регион включает три направления: "Центральный" (Central), "Восточный" (East) и "Западный" (West). Таблица фактов "Продажи" (Sales) содержит данные о продажах и прокате видеопродукции компании за 2000-2009 гг. Схема "звезда" для рассматриваемого ХД приведена на рис. 22.3, а описание полей таблиц измерений и таблицы фактов приведено в табл. 22.7.
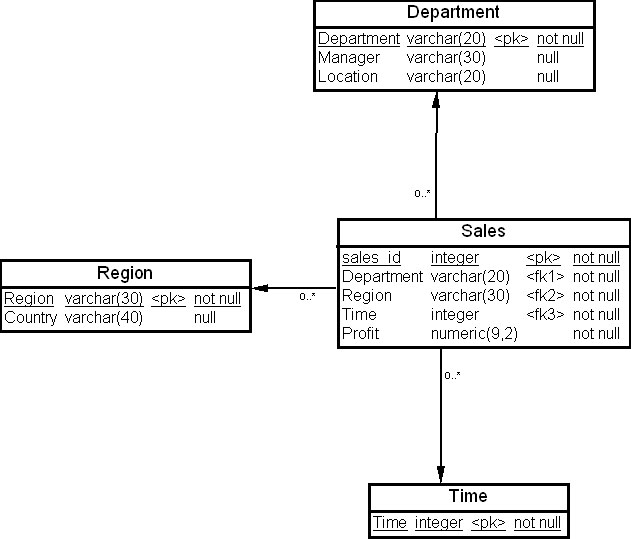
увеличить изображение
Рис. 22.3. Схема "звезда" для хранилища данных организации, торгующей видеопродукцией
| Имя поля | Описание |
|---|---|
| Таблица измерения "Время" (Time) | |
| Time | Год |
| Таблица измерения "Регион" (Region) | |
| Region | Наименование региона |
| Country | Страна |
| Таблица измерения "Отделы продаж" (Department) | |
| Department | Отдел продаж |
| Manager | Руководитель отдела |
| Location | Месторасположение |
| Таблица фактов "Продажи" (Sales) | |
| sales_id | Идентификатор продажи |
| Time | Год |
| Region | Наименование региона |
| Department | Отдел продаж |
| Profit | Прибыль |
В табл. 22.8 приведен типичный отчет, который руководство компании может запросить для анализа деятельности компании за определенный период времени.
Обратим внимание на то, что в этом небольшом отчете генерируются пять частичных сумм и итоговые суммы. Частичные суммы являются скрытыми числами, которые должны быть вычислены для отчета в запросе, использующем агрегатную функцию SUM() и предложение GROUP BY.
Рассмотрим теперь подробнее расширения оператора SELECT, которые упрощают конструирование запросов для построения отчетов, аналогичных приведенному в табл. 22.7.
Предложение ROLLUP
Предложение ROLLUP позволяет в команде SELECT вычислять многоуровневые частичные суммы для специфицированных групп измерений. Также вычисляется итоговая сумма. Предложение ROLLUP является простым расширением предложения GROUP BY, поэтому синтаксис для его применения прост. Использование предложения ROLLUP очень эффективно.
Синтаксис:
SELECT ... GROUP BY ROLLUP(grouping_column_reference_list)
Действия ROLLUP являются следующими: создаются частичные суммы для каждого из раскрываемых уровней от наиболее низкого уровня иерархии к более высокому уровню и вычисляется итоговая сумма в соответствии с указанным списком колонок в предложении ROLLUP. Предложение ROLLUP рассматривает свои аргументы как упорядоченный список колонок группировки. Сначала вычисляется стандартное агрегатное значение, указанное в предложении GROUP BY. Затем создаются частичные суммы для уровней атрибутов из списка группировки GROUP BY в порядке возрастания их значений, справа налево по списку колонок группировки. И окончательно создается итоговая сумма (grand total).
Предложение ROLLUP создает частичные суммы для n+1 уровней, где n есть число колонок группировки. Например, если в запросе указан ROLLUP на колонки группировки измерений "Время" (Time), "Регион" (Region) и "Отдел продаж" (Department) ( n=3 ), то результирующее множество (result set) будет включать в себя строки для 4-х уровней агрегации.
Рассмотрим примеры.
Пример 22.3. Пусть руководству компании требуется отчет о прибыли по всем регионам по всем отделам продаж за 2007-08 гг. Предложение SELECT для приведенной на рис. 22.3 схемы ХД может выглядеть следующим образом.
SELECT Time, Region, Department, SUM(Profit) AS Profit FROM sales GROUP BY ROLLUP(Time, Region, Department);
Вывод 1: Агрегирование в ROLLUP для трех измерений
| Time | Region | Department | Profit |
|---|---|---|---|
| 2007 | Центральный | VideoRental | 75,00 |
| 2007 | Центральный | VideoSales | 74,00 |
| 2007 | Центральный | NULL | 149,00 |
| 2007 | Восточный | VideoRental | 89,00 |
| 2007 | Восточный | VideoSales | 115,00 |
| 2007 | Восточный | NULL | 204,00 |
| 2007 | Западный | VideoRental | 87,00 |
| 2007 | Западный | VideoSales | 86,00 |
| 2007 | Западный | NULL | 173,00 |
| 2007 | NULL | NULL | 526,00 |
| 2008 | Центральный | VideoRental | 82,00 |
| 2008 | Центральный | VideoSales | 85,00 |
| 2008 | Центральный | NULL | 167,00 |
| 2008 | Восточный | VideoRental | 101,00 |
| 2008 | Восточный | VideoSales | 137,00 |
| 2008 | Восточный | NULL | 238,00 |
| 2008 | Западный | VideoRental | 96,00 |
| 2008 | Западный | VideoSales | 97,00 |
| 2008 | Западный | NULL | 193,00 |
| 2008 | NULL | NULL | 598,00 |
| NULL | NULL | NULL | 1124,00 |
Как видно из примера выше, запрос возвращает следующий набор строк:
- обычные строки агрегации, которые выдаются предложением GROUP BY без использования ROLLUP ;
- частичные суммы 1-го уровня, агрегированные для "Отдела продаж" (Department) для каждой комбинации измерений "Время" (Time) и "Регион" (Region);
- частичные суммы 2-го уровня, агрегированные для измерений "Регион" (Region) и "Отдела продаж" (Department) для каждого значения измерения "Время" (Time);
- строку с итоговой суммой.
Заметим, что NULL-значения показываются только для ясности. В действительности при выводе будут показаны пробелы.
NULL-значения, возвращаемые в результате выполнения предложений ROLLUP и CUBE, не всегда могут толковаться в общепринятом смысле, как неопределенные значения. NULL-значения могут указывать, что строка содержит частичную сумму. Например, первое NULL-значение в Выводе 1 появляется в колонке "Отдел продаж" (Department). Это NULL-значение означает, что строка есть частичная сумма для всех отделов продаж для Центрального региона за 2007 год.
Использование ROLLUP для вычисления частичных сумм
Можно использовать предложение ROLLUP только для вычисления некоторых частичных сумм. Такие команды с применением ROLLUP используют синтаксис как показано ниже:
GROUP BY expr1, ROLLUP(expr2, expr3);
В этом случае предложение ROLLUP создает частичные суммы для (2+1=3) уровней агрегации (aggregation levels), т.е. для уровней (expr1, expr2, expr3), (expr1, expr2) и (expr1). Итоговая сумма (grand total) не создается.
Пример 22.4. Пусть руководству компании требуется отчет о прибыли по всем регионам по всем отделам продаж за 2007-2008 гг. без итоговой суммы прибыли. Предложение SELECT для приведенной на рис. 22.3 схемы ХД может выглядеть следующим образом:
SELECT Time, Region, Department, SUM(Profit) AS Profit FROM sales GROUP BY Time, ROLLUP (Region, Department);
Вывод 2. Использование предложения ROLLUP для вывода частичных сумм
| Time | Region | Department | Profit |
|---|---|---|---|
| 2007 | Центральный | VideoRental | 75,00 |
| 2007 | Центральный | VideoSales | 74,00 |
| 2007 | Центральный | NULL | 149,00 |
| 2007 | Восточный | VideoRental | 89,00 |
| 2007 | Восточный | VideoSales | 115,00 |
| 2007 | Восточный | NULL | 204,00 |
| 2007 | Западный | VideoRental | 87,00 |
| 2007 | Западный | VideoSales | 86,00 |
| 2007 | Западный | NULL | 173,00 |
| 2007 | NULL | NULL | 526,00 |
| 2008 | Центральный | VideoRental | 82,00 |
| 2008 | Центральный | VideoSales | 85,00 |
| 2008 | Центральный | NULL | 167,00 |
| 2008 | Восточный | VideoRental | 101,00 |
| 2008 | Восточный | VideoSales | 137,00 |
| 2008 | Восточный | NULL | 238,00 |
| 2008 | Западный | VideoRental | 96,00 |
| 2008 | Западный | VideoSales | 97,00 |
| 2008 | Западный | NULL | 193,00 |
| 2008 | NULL | NULL | 598,00 |
Как видно, запрос возвращает следующее множество строк:
- обычные строки агрегации, которые выдаются предложением GROUP BY без использования ROLLUP ;
- частичную сумму 1-го уровня агрегации по "Отделам продаж" (Department) для каждой комбинации "Время" (Time) и "Регион" (Region);
- частичную сумму 2-го уровня агрегации по измерениям "Регион" (Region) и "Отдел продаж" (Department) для каждого значения измерения "Время" (Time);
- нет строки с итоговой суммой.
Можно вычислить частичные суммы без использования предложения ROLLUP следующим образом:
SELECT Time, Region, Department, SUM(Profit) FROM Sales GROUP BY Time, Region, Department UNION ALL SELECT Time, Region, '' , SUM(Profit) FROM Sales GROUP BY Time, Region UNION ALL SELECT Time, '', '', SUM(Profit) FROM Sales GROUP BY Time UNION ALL SELECT '', '', '', SUM(Profit) FROM Sales;
Как видно из примера выше, для этого требуется для n измерений n+1 SELECT с UNION ALL.
ROLLUP-предложение целесообразно использовать для задач, в которых вычисляются промежуточные или частичные суммы:
- в измерениях с иерархической структурой, таких как "время" или "географическое расположение": ROLLUP(y, m, day) или ROLLUP(country, state, city).
- для быстрой генерации отчетов с суммарными данными.
Предложение CUBE
Частичные суммы, генерируемые предложением ROLLUP, представляют только часть возможных комбинаций частичных сумм в измерениях. Например, в перекрестном отчете (см. табл. 22.1) итоги работы отделов продаж по регионам (279,000 и 319,000) не могут быть вычислены в предложении ROLLUP(Time, Region, Department). Для этого нужно изменить порядок колонок группировки в предложении ROLLUP: ROLLUP(Time, Department, Region). Простой способ генерации полного набора частичных сумм для перекрестных отчетов состоит в использовании расширения CUBE предложения GROUP BY.
Предложение CUBE позволяет команде SELECT вычислить частичные суммы для всех возможных комбинаций групп измерений. Оно также вычисляет итоговую сумму. Подобно ROLLUP, предложение CUBE является расширением предложения GROUP BY.
Синтаксис:
SELECT ... GROUP BY CUBE (grouping_column_reference_list)
Из примера ниже видно, что CUBE берет указанный набор колонок группировки и создает частичные суммы для всех возможных комбинаций значений этих колонок. С точки зрения многомерного анализа, предложение CUBE генерирует все частичные суммы, которые могут быть вычислены для куба данных с указанными измерениями. Если указывается CUBE(Time, Region, Department), то результирующее множество запроса будет включать все значения, которые входят в аналогичную конструкцию ROLLUP, плюс набор дополнительных комбинаций.
Пример 22.5. Пусть руководству компании требуется перекрестный отчет о прибыли по всем регионам по всем отделам продаж за 2007-2008 гг. Предложение SELECT для приведенной на рис. 22.3 схемы ХД может выглядеть следующим образом:
SELECT Time, Region, Department, SUM(Profit) AS Profit FROM sales GROUP BY CUBE(Time, Region, Department);
Вывод 3. Выполнение CUBE с агрегацией по трем измерениям
| Time | Region | Department | Profit |
|---|---|---|---|
| 2007 | Центральный | VideoRental | 75,00 |
| 2007 | Центральный | VideoSales | 74,00 |
| 2007 | Центральный | NULL | 149,00 |
| 2007 | Восточный | VideoRental | 89,00 |
| 2007 | Восточный | VideoSales | 115,00 |
| 2007 | Восточный | NULL | 204,00 |
| 2007 | Западный | VideoRental | 87,00 |
| 2007 | Западный | VideoSales | 86,00 |
| 2007 | Западный | NULL | 173,00 |
| 2007 | NULL | NULL | 526,00 |
| 2008 | Центральный | VideoRental | 82,00 |
| 2008 | Центральный | VideoSales | 85,00 |
| 2008 | Центральный | NULL | 167,00 |
| 2008 | Восточный | VideoRental | 101,00 |
| 2008 | Восточный | VideoSales | 137,00 |
| 2008 | Восточный | NULL | 238,00 |
| 2008 | Западный | VideoRental | 96,00 |
| 2008 | Западный | VideoSales | 97,00 |
| 2008 | Западный | NULL | 193,00 |
| 2008 | NULL | VideoRental | 279,00 |
| 2008 | NULL | VideoSales | 319,00 |
| 2008 | NULL | NULL | 598,00 |
| NULL | Центральный | VideoRental | 157,00 |
| NULL | Центральный | VideoSales | 159,00 |
| NULL | Центральный | NULL | 316,00 |
| NULL | Восточный | VideoRental | 190,00 |
| NULL | Восточный | VideoSales | 252,00 |
| NULL | Восточный | NULL | 442,00 |
| NULL | Западный | VideoRental | 183,00 |
| NULL | Западный | VideoSales | 183,00 |
| NULL | Западный | NULL | 366,00 |
| NULL | NULL | VideoRental | 530,00 |
| NULL | NULL | VideoSales | 594,00 |
| NULL | NULL | NULL | 1124,00 |
Владислав Нагорный
Лариса Парфенова
|
1) Можно ли экстерном получить второе высшее образование "Программная инженерия" ? 2) Трудоустраиваете ли Вы выпускников? 3) Можно ли с Вашим дипломом поступить в аспирантуру?
|