
|
Подскажите, пожалуйста, планируете ли вы возобновление программ высшего образования? Если да, есть ли какие-то примерные сроки? Спасибо! |
Инспектор
Спонсор: Microsoft
Вы можете этот курс.
Лекция 14:
Физическая модель хранилища данных: учет влияния транзакций, денормализация таблиц
Денормализация
Понятие о денормализации
Начиная с этого раздела, мы будем рассматривать методики настройки физической структуры реляционной БД, используемой для реализации ХД, с целью удовлетворения требования к производительности ХД. Эти методики представляют собой набор рекомендаций и эвристических правил по изменению физической структуры БД, которая была получена в результате первой итерации создания физической модели данных ХД. Ясно, что применение этих методик носит рекомендательный характер.
В этом разделе будут описаны различные типы денормализации и методы ее реализации. Кроме того, мы рассмотрим, как при выполнении денормализации обеспечить целостность данных, не прибегая к созданию дополнительного кода.
Под денормализацией понимают процесс достижения компромиссов в нормализованных таблицах посредством намеренного введения избыточности в целях увеличения производительности.
В большинстве случаев необходимость денормализации становится очевидной лишь на этапе проектирования приложений ХД или его эксплуатации. Другими словами, нельзя принять решение о денормализации на основании одной только модели данных. Обычно стараются найти в приложениях ХД критичные процессы и принимать решения о денормализации в основном в пользу этих процессов. Критичные процессы, как правило, определяют по высокой частоте, большому объему, высокой изменчивости или явному приоритету. Качественное описание транзакций БД позволяет определить наличие таких критических процессов.
Заметим, что применять денормализацию только для упрощения SQL-запросов при обращении к ХД является неправильным решением. Если вы хотите упростить SQL-запросы на уровне приложения или пользователя, то, наверное, лучше использовать представления, а не вводить избыточность. Чтобы повысить производительность запроса, можно ввести индексы.
Как правило, денормализация уменьшает время запроса за счет DML-операций. Денормализацию следует рассматривать как расширение нормализованной модели данных, которое повышает производительность запросов. При приятии решения о денормализации следует определить, что является наиболее важным для приложения – избыточность данных или высокая производительность. Если ведется журнал проектирования (некоторый внутренний документ произвольной формы, в котором фиксируются все принятые в процессе проектирования ХД решения), то в него необходимо занести обоснованное решение о денормализации. Необходимо помнить, что кроме денормализации существуют и другие пути повышения производительности. Денормализацию таблиц можно выполнять как на уровне логической модели данных, так и на уровне физической модели.
Нисходящая денормализация
Рассмотрим принципы денормализации на уровне физической модели данных. Нисходящая денормализация предлагает перенос колонки из одной (родительской) таблицы в подчиненную (дочернюю) таблицу.
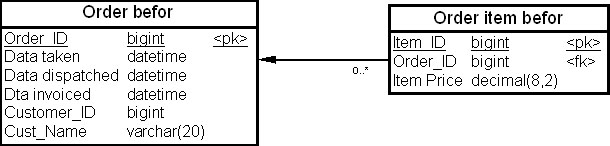
На рис. 19.1 показаны две таблицы – "Покупатель" (Customer befor) и "Заказ" (Order befor) – физической модели данных до проведения денормализации, а на рис. 19.2 — эти же таблицы, "Покупатель" (Customer after) и "Заказ" (Order after), после выполнения нисходящей денормализации.

увеличить изображение
Рис. 19.1. Таблицы "Покупатель" (Customer befor) и "Заказ" (Order befor) до денормализации

увеличить изображение
Рис. 19.2. Таблицы "Покупатель" (Customer after) и "Заказ" (Order after) после денормализации
Из рисунков видно, что в денормализованной модели мы переместили колонку "Фамилия покупателя" (Cust_Name) из таблицы "Покупатель" (Customer after) в таблицу "Заказ" (Order after).
Что дает введение избыточности (перенос колонки) в данном случае? Единственный выигрыш заключается в том, что мы исключаем операцию соединения, если захотим вместе с заказом увидеть фамилию клиента.
Таким образом, нисходящая денормализация – это процесс введения избыточных колонок в подчиненных таблицах с целью устранения операций соединения.
Однако устранение соединений посредством нисходящей денормализации редко оправдывает затраты на сопровождение дублирующей колонки в таблице "Заказ" (Order). Такие соединения, как правило, не являются глобальной проблемой, а выполнение нисходящей денормализации может привести к возникновению дорогостоящих каскадных обновлений. Например, если покупатель меняет фамилию, то приходится обновлять все заказы, чтобы отразить это изменение. А нужно ли это делать? Следует ли обновлять старые заказы, которые выполнены или закрыты? Если бы не была проведена денормализация, эти вопросы никогда и не возникли бы.
Нисходящая денормализация оправдана лишь в приложениях, где необходимо устранять операции соединения таблиц. Это имеет место в ХД большого объема. При этом проблем с каскадными обновлениями не возникает, потому что данные в ХД обладают свойством стабильности, т.е. не изменяются после занесения их в ХД.
Восходящая денормализация
Восходящая денормализация предлагает перенос колонки из подчиненной (дочерней) таблицы в родительскую таблицу, обычно в форме итоговых данных.
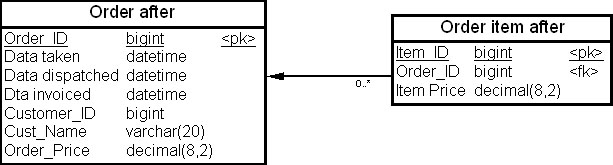
На рис. 19.3 показаны две таблицы – "Заказ" (Order befor) и "Позиция заказа" (Order item befor) – физической модели данных до проведения денормализации, а на рис. 19.4 — эти же таблицы "Заказ" (Order after) и "Позиция заказа" (Order item after) после выполнения восходящей денормализации.
Например, если вычисление общей суммы заказа в системе обработки заказов (суммирование колонок "Цена позиции заказа" (Item_Price) в таблице "Позиции заказа" (Order Item)) приводит к снижению производительности, то мы можем повысить производительность этой операции, поместив сумму заказа в избыточной колонке "Сумма заказа" (Order Price) таблицы "Заказ" (Order after).
В нашем примере в избыточном столбце хранится сумма значений, но восходящая денормализация применима к максимальным, минимальным и средним значениям, а также к другим агрегатным показателям.
Таким образом, восходящая денормализация - это процесс введения избыточных колонок в родительских таблицах с целью устранения операций соединения с операциями агрегирования.
Чтобы представить результат введения денормализации, рассмотрим процедуру сопровождения денормализованных таблиц "Заказ" (Order after) и "Позиция заказа" (Order item after), которые сводятся к поддержке следующих бизнес-правил.
- Когда в таблицу "Позиция заказа" (Order item after) добавляется новая строка, колонка "Сумма заказа" (Order_Price) в таблице "Заказ" (Order after) увеличивается на значение колонки "Цена позиции заказа" (Item_Price) таблицы "Позиция заказа" (Order item after) для новой позиции заказа.
- Когда строка удаляется из таблицы "Позиция заказа" (Order item after), значение колонки "Цена заказа" в таблице "Заказ" (Order after) уменьшается на значение колонки "Цена позиции заказа" (Item_Price) в таблице "Позиция заказа" (Order item after) для удаляемой строки из позиции заказа.
- Когда изменяется значение колонки "Цена позиции заказа" (Item_Price) в таблице "Позиция заказа" (Order item after), значение колонки "Сумма заказа" (Order_Price) в таблице "Заказ" (Order after) должна быть откорректирована на разницу между старым и новым значением колонки "Цена позиции заказа" (Item_Price).
Поддержка перечисленных выше бизнес-правил создает дополнительную нагрузку на процессы, выполняющие DML-операции в таблице "Позиция заказа" (Order item after). Это и есть цена, которую приходится платить за повышение производительности запросов.
Внутритабличная денормализация
Внутритабличная денормализация выполняется в пределах одной таблицы, т.е. это процесс введения избыточных колонок в одной таблице с целью увеличения производительности запроса строки по производному значению. Например, если строка содержит две числовых колонки, X и Y, то значение Z, равное произведению X и Y (Z=X*Y), легко вычислить во время выполнения.
Предположим, что есть запросы, в которых необходимо осуществить поиск по Z (например, Z принадлежит диапазону от 10 до 20). Сохранив избыточные значения Z в столбце, можно построить индекс по Z, и запросы будут использовать этот индекс. Если индекс по Z строить не надо, то решение о его хранении в отдельном столбце зависит от того, что является более приемлемым — увеличение времени загрузки, вызванное необходимостью постоянно пересчитывать Z, или увеличение времени сканирования, обусловленное удлинением строк таблицы за счет хранения дополнительной колонки.
Приведем еще один часто встречающийся пример внутритабличной нормализации. Допустим, что одинаковый текст хранится в двух видах: с символами в верхнем и в нижнем регистре — для отображения в отчетах и на экране, и с символами в верхнем регистре — для обеспечения работы ускоренных запросов без учета регистра.
Отметим, что обеспечить приемлемую производительность для таблиц умеренного размера (до 10000 строк) в последнем случае можно и без внутритабличной нормализации, переработав запрос с применением встроенной функции UPPER.
Внутритабличная нормализация редко используется при проектировании ХД.
Владислав Нагорный
Лариса Парфенова
|
1) Можно ли экстерном получить второе высшее образование "Программная инженерия" ? 2) Трудоустраиваете ли Вы выпускников? 3) Можно ли с Вашим дипломом поступить в аспирантуру?
|