|
Подскажите, пожалуйста, планируете ли вы возобновление программ высшего образования? Если да, есть ли какие-то примерные сроки? Спасибо! |
Инспектор
Вы можете этот курс.
Опубликован: 20.12.2010 | Уровень: специалист | Доступ: платный
Лекция 2:
Хранилища данных
Концепция хранилищ данных
Отметим, что складирование данных — это развивающаяся технология. Как и для любой развивающейся технологии, определенная доля осторожности должна присутствовать при оценке действий производителей ПО ХД, пытающихся позиционировать себя среди конкурентов. Например, дискуссии о размерах ХД — с какого размера хранилище данных можно считать собственно хранилищем? С 50 ГБ? Заметим, что в некоторых областях исследования размер анализируемого массива может быть очень небольшим. Просто нет данных. А анализ такого массива возможен.
Рассмотрим основные элементы концепции складирования данных.
Извлечение данных из операционных систем
Главный элемент концепции складирования данных состоит в том, что к данным, сохраняемым для анализа, может быть обеспечен наиболее эффективный доступ только при условии выделения их из операционной (транзакционной) системы, т.е. данные из операционной системы должны быть вынесены в отдельную систему складирования данных. Такой подход носит исторический характер. Из-за ограничений в аппаратном обеспечении и технологии, для того чтобы обеспечить производительность транзакционной системы, данные архивировались на магнитных лентах или носителях вне такой системы. Проблема доступа к ним требовала определенных технологических решений.
Нужно отметить, что с развитием концепции позиция отделения данных для анализа от данных в OLTP-системе претерпела мало изменений. Она стала более формальной и обогатилась за счет применения средств многомерного анализа данных. В настоящее время ХД можно строить и на существующей OLTP-системе, и над ней, и как самостоятельный объект. Это должно решаться руководителем ИТ-проекта в рамках выбора архитектуры ХД.
Необходимость интегрирования данных из нескольких OLTP-систем
Системы складирования данных наиболее полезны, когда данные могут быть извлечены более чем из одной OLTP-системы. Когда данные должны быть собраны от нескольких бизнес-приложений, естественно предположить, что это нужно сделать в месте, отличном от места локализации исходных приложений. Еще до создания структурированных ХД аналитики во многих случаях комбинировали данные, извлеченные из разных систем, в одну крупноформатную таблицу или базу данных. ХД может очень эффективно воедино собрать данные от конкретных приложений, таких как продажи, маркетинг, финансы, производство, с учетом их накопления, т.е. сохранить временные ряды основных показателей бизнеса — так называемые исторические данные.
Заметим, что одним из свойств данных, собранных из различных приложений и используемых аналитиками, является возможность делать перекрестные запросы к таким данным. Во многих ХД атрибут "время" является естественным критерием для фильтрования данных. Аналитиков интересует поведение временных рядов данных, характеризующих процессы бизнеса.
Целью многих систем складирования данных является обзор деятельности типа "год за годом". Например, можно сравнивать продажи в течение первого квартала этого года с продажами в течение первого квартала предшествующих лет. Время в ХД — фундаментальный атрибут перекрестных запросов. Например, аналитик может попытаться оценить влияние новой компании маркетинга, проходящей в течение определенных периодов, рассматривая продажи в течение тех же самых периодов. Способность устанавливать и понимать корреляцию между деятельностью различных подразделений в организации часто приводится как один из самых главных аргументов о пользе систем складирования данных.
Система складирования данных не только может работать как эффективная платформа для консолидации данных из различных источников, но может также собирать многократные версии данных из одного приложения. Например, если организация перешла на новое программное обеспечение, то ХД сохранит необходимые данные из предыдущей системы. В этом отношении система складирования данных может служить средством интеграции наследуемых данных, сохраняя преемственность анализа при смене программно-аппаратной платформы OLTP-системы.
Различия между транзакционной и аналитической обработкой данных
Одной из наиболее важных причин отделения данных для анализа от данных OLTP-систем было потенциальное падение производительности обработки запросов при выполнении процессов анализа данных. Высокая производительность и небольшое время ответа — критические параметры OLTP-систем. Потерю производительности и объем накладных затрат, связанных с обработкой предопределенных запросов, обычно легко оценить. С другой стороны, запросы для анализа данных в ХД трудно предсказать, и следовательно, для них сложно оценить время выполнения запроса.
OLTP-системы спроектированы для оптимального выполнения предопределенных запросов в режиме работы, близком к режиму реального времени. Для таких систем обычно можно определить распределение нагрузки во времени, определить время пиковых нагрузок, оценить критические запросы и применить к ним процедуры оптимизации, поддерживаемые современными СУБД. Также относительно легко определить максимально допустимое время ответа на определенный запрос в системе. Стоимость времени ответа такого запроса может быть оценена на основе отношения стоимости выполнения операций ввода-вывода / стоимость затрат на трафик по сети. Например, для системы обработки заказов можно задать число активных менеджеров по оформлению заказов и среднее число заказов в течение каждого часа работы.
Несмотря на то, что многие из запросов и отчетов в системе складирования данных предопределены, почти невозможно точно предсказать поведение показателей системы (время отклика, трафик сети и т.п.) при их выполнении. Процесс исследования данных в ХД происходит зачастую непредсказуемым путем. Руководители всех рангов умеют ставить неожиданные вопросы. В процессе анализа могут возникать непредопределенные (ad hoc) запросы, которые вызваны неожиданными результатами или непониманием конечным пользователем используемой модели данных. Далее, многие из процессов анализа имеют тенденцию принимать во внимание многие аспекты деятельности организации, в то время как OLTP-системы хорошо сегментированы по видам деятельности. Пользователю может потребоваться более детальная информация, чем хранящаяся в итоговых таблицах. Это может привести к соединению двух или более огромных таблиц, что закончится созданием временной таблицы объемом, равным произведению числа строк в каждой таблице, и резко снизит производительность системы.
Данные в системах складирования данных остаются неизменными
Другое ключевое свойство данных в системе складирования данных состоит в том, что данные в ХД остаются неизменными. Это означает, что после того, как данные разместятся в ХД, они не могут быть изменены. Например, статус заказа не меняется, размер заказа не меняется, и т. д. Эта характеристика ХД имеет большое значение для отбора типов данных при размещении их в ХД, а также выбор момента времени, когда данные должны быть занесены в ХД. Последнее свойство называется гранулированностью данных.
Рассмотрим, что означает для данных быть неизменяемыми. В OLTP-системе объекты данных проходят через постоянные изменения своих атрибутов. Например, заказ может многократно изменять свой статус до того, как будет оформлен. Или, когда изделие собирается на сборочной линии, к нему применяется множество технологических операций. Вообще говоря, данные из OLTP-системы нужно загружать в ХД лишь тогда, когда обработка их в рамках бизнес-процессов будет полностью завершена. Это может означать завершение заказа или цикла производства изделия. Как только заказ закончен и отправлен, он вряд ли поменяет свой статус. Или, как только изделие собрано и сдано на склад, оно вряд ли попадет на первую стадию сборочного цикла.
Другим хорошим примером может быть размещение в ХД снимка постоянно изменяющихся данных в определенные моменты времени. Модуль управления запасами в OLTP-системе может изменять запас почти в каждой транзакции; невозможно занести все эти изменения в ХД. Вы можете определить, что такой снимок состояния запаса следует вносить в ХД каждую неделю или ежедневно, так, как это будет принято для анализа в конкретной организации. Данные такого снимка, естественно, неизменяемы.
После того, как данные занесены в ХД, их модификация возможна в крайне редких случаях. Очень трудно (хотя такие попытки есть) поддерживать динамические данные в ХД. Задача синхронизации часто изменяемых данных в OLTP-системах и системах складирования данных еще далека от приемлемого решения. Здесь следует также упомянуть, что размещение динамично меняющихся данных в ХД в настоящее время является предметом интенсивных исследований. Например, разработка процедур поддержки в ХД медленно меняющихся таблиц измерений является задачей, которая уже находит свое решение на уровне ПО производителей решений в области ХД.
Данные в хранилище данных хранятся значительно более длительное время, чем в OLTP-системах
Данные в большинстве OLTP-систем архивируются сразу после того, как они становятся неактивными. Например, заказ может стать неактивным после того, как он выполнен; банковский счет может стать неактивным после того, как он был закрыт. Главная причина для архивирования неактивных данных — это производительность OLTP-системы (зачем хранить данные, если к ним не обращаются). Большие объемы таких данных могут заметно ухудшить производительность выполнения запросов в предположении, что обрабатываются только активные данные. Для обработки таких данных в СУБД предлагаются различные процедуры разбиения базовых таблиц на секции. С другой стороны, поскольку ХД предназначены, в частности, быть архивом для OLTP-данных, данные в них хранятся в течение очень длительного периода.
Фактически, проект системы складирования данных может начинаться и без любого определенного плана архивирования данных из ХД. Стоимость сопровождения данных после их загрузки в хранилище невысока. Наибольшие затраты при создании хранилища выпадают на трансформацию данных (data transfer) и их очистку (data scrubbing). Хранение данных в течение пяти и более лет типично для систем складирования данных. Поэтому процедурам архивизации данных из ХД на стадиях их создания и эксплуатации в начале периода можно не уделять много времени. Особенно если учесть снижение цен на аппаратные средства ЭВМ.
Иначе говоря, отделение данных OLTP-систем от данных систем анализа является фундаментальной концепцией складирования данных. Сейчас бизнес невозможен без принятия обоснованных решений. Такие решения могут быть построены на основе всестороннего анализа результатов выполнения бизнес-процессов в организации и деятельности организации на рынке товаров и услуг. Время принятия решений в современных условиях и потоках информации сокращается. Роль создания и поддержки систем анализа данных на основе новых информационных технологий возрастает. ХД является одним из основных звеньев применения таких технологий.
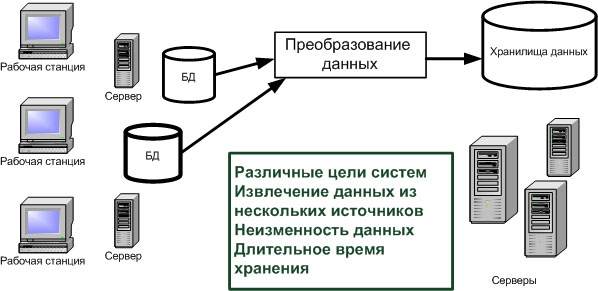
Можно выделить следующие причины для разделения данных систем складирования данных и систем операционной обработки данных ( рис. 1.5).
- Различие целевых требований к системам складирования данных и OLTP-системам.
- Необходимость собирать данные в ХД из различных информационных источников, т.е. если данные генерируются в самой OLTP-системе, то для системы складирования данных в большинстве случаев данные генерируются вне ее.
- Данные, попадая в ХД, остаются в большинстве случаев неизменными.
- Данные в ХД сохраняются длительное время.
Логическое преобразование данных OLTP-систем и моделирование данных
Данные в ХД логически являются преобразованными, когда они перенесены в него из OLTP-системы или другого внешнего источника. Проблемы, связанные с логическим преобразованием данных при переносе их в ХД, могут потребовать значительного анализа и усилий проектировщиков. Архитектура системы складирования данных и модели ХД имеют огромное значение для успеха таких проектов. Ниже будут рассмотрены некоторые фундаментальные понятия реляционной теории БД, которые полностью не применимы к системам складирования данных. Даже при том, что большинство ХД развернуто на реляционных БД, некоторые основные принципы реляционных БД сознательно нарушаются при создании логической и физической модели ХД.
Модель данных ХД определяет его логическую и физическую структуру. В отличие от просто архивированных данных, в данном случае невозможно обойтись без процедур детального моделирования. Такое моделирование на ранних стадиях проекта системы складирования необходимо для создания эффективной системы, охватывающей данные всех бизнес-процессов и процедур организации.
Процесс моделирования данных должен структурировать данные в ХД в виде, не зависимом от реляционной модели данных системы, которая поставляет эти данные. Как будет показано ниже, модель ХД, вероятно, будет менее нормализована, чем модель OLTP-системы – источника данных.
В OLTP-системах данные по разным подсистемам могут значительно перекрываться. Например, информация относительно разрабатываемых изделий используется в различных формах во многих подсистемах OLTP-системы. Система складирования данных должна объединить все такие данные в одной системе. Некоторые атрибуты объектов, которые являются существенными для OLTP-системы, окажутся ненужными для ХД. Могут появиться новые атрибуты, так как сущность (entity) в ХД изменяет свое качество. Основное требование — все данные в ХД должны участвовать в процессе анализа.
Модель данных ХД должна быть расширена и структурирована таким образом, чтобы данные от различных приложений могли быть добавлены. Проект ХД в большинстве случаев не может включать данные от всех возможных бизнес-приложений организации. Обычно объем данных в ХД увеличивается по принципу инкремента: данные экстрагируются из OLTP-систем и добавляются в ХД определенными порциями. Начинают с сохранения особенно существенных данных, затем планомерным образом наращивают по мере необходимости их объем.
Модель хранилища данных подстраивается под структуру бизнеса
Следующий важный момент состоит в том, что логическая модель ХД настраивается на структуру бизнеса (ориентирована на предметную область), а не на агрегацию логических моделей конкретных приложений. Сущности (объекты), поддерживаемые в ХД, аналогичны сущностям (объектам) бизнеса — таким как клиенты, продукция (товар), заказы и дистрибьютеры. В рамках конкретных подразделений организации может быть очень узкое представление об объектах бизнеса организации, например, о клиентах. Так, группа обслуживания ссуд в банке может знать что-либо о клиенте только в контексте одной или нескольких выданных ссуд. Другое подразделение того же банка может знать о том же клиенте в контексте депозитного счета. Представление данных о клиенте в ХД намного превышает аналогичное представление конкретного подразделения банка. Клиент в ХД представляет клиента банка во всех его взаимоотношениях с банком. С точки зрения реляционной теории меняется базисный набор функциональных зависимостей, поддерживаемых в БД.
ХД следует строить на атрибутах сущностей бизнеса (предметно ориентированно), собирая данные об этих сущностях из различных источников. Структура данных любого отдельного источника данных, вероятно, будет неадекватна для ХД. На структуру данных конкретного приложения оказывают влияние такие факторы, как:
- вид конкретного бизнес-процесса. Так, в автоматизированной подсистеме закупок структура данных может быть продиктована характером бизнес-процедур закупок на данном секторе рынка;
- влияние модели действующих систем. Например, исходное приложение может быть достаточно старым и учитывать развитие модели данных за счет изменения структуры БД приложения. Многие такие изменения могут быть плохо документированы;
- ограничения программно-аппаратной платформы. Логическая структура данных может не поддерживать некоторые логические взаимоотношения между данными или иметь ограничения, связанные с ограничениями программно-аппаратной платформы.
Модель ХД не связана с ограничениями моделей данных источников. Для нее должна быть разработана модель, которая отражает структуру бизнеса организации, а не структуру бизнес-процесса. Такая расширенная модель данных должна быть понятна как аналитикам, так и менеджерам. Таким образом, проектировщик ХД должен выполнить настройку объектов ХД к структуре бизнеса организации, с учетом ее бизнес-процессов и бизнес-процедур.
Преобразование информации, описывающей состояние объектов в OLTP-системе
Следующий важный момент состоит в том, что перед размещением данных в ХД они должны быть преобразованы. Большинство данных из OLTP-системы или иного внешнего источника не могут поддерживаться в ХД. Многие из атрибутов объектов в OLTP-системе очень динамичны и постоянно изменяются. Многие из этих атрибутов не загружаются в ХД, другие же атрибуты являются статичными во времени и загружаются в ХД. ХД вообще не должно содержать информации об объектах, которые являются динамическими и постоянно находятся в состоянии модификации.
Чтобы понять, что означает потеря информации, описывающей текущее состояние объекта, рассмотрим пример системы управления заказами, которая отслеживает состояния запасов при заполнении заказа. Сначала рассмотрим сущность "Заказ" в OLTP-системе. Заказ может пройти множество различных статусов или состояний, прежде чем он будет выполнен и обретет статус завершенного. Статус заказа может указывать, что он готов к заполнению, что заказ заполняется, возвращен обратно на доработку, готов к отгрузке и т.д. Конкретный заказ может пройти много состояний, которые отражаются в статусе заказа и определяются бизнес-процессами, которые применялись к нему. Практически невозможно перенести все атрибуты такого объекта в ХД. Система складирования данных, вероятно, должна содержать только один конечный снимок такого объекта, как заказ. Таким образом, объект "Заказ" должен быть преобразован для размещения в ХД. Тогда в ХД может быть собрана информация о многих объектах типа "заказ" и построен окончательный объект ХД – "Заказ".
Рассмотрим более сложный пример трансформации данных при управлении запасом товара в OLTP-системе. Запас может изменяться в каждой транзакции. Количество конкретного товара на складе может быть уменьшено транзакцией подсистемы заполнения заказа или увеличено при поступлении купленного товара. Если система обработки заказа выполняет десятки тысяч транзакций в день, то, вероятно, фактический уровень запаса в БД будет иметь много состояний и зафиксируется во многих снимках в течение этого дня. Невозможно зафиксировать все эти постоянные изменения в БД и перенести их в ХД. Отображение такого поведения объекта в системе – источнике данных по-прежнему является одной из нерешенных задач в системах складирования данных. Есть ряд подходов к решению этой проблемы. Например, можно периодически фиксировать снимки уровня запаса в ХД.
Этот подход может быть применим к очень большой части данных в OLTP-системах. В свою очередь, такое решение повлечет за собой ряд задач, связанных с выбором периода времени, объема снимаемых данных и т.д. Таким образом, большая часть данных о состоянии объектов в OLTP-системе не может быть непосредственно перенесена в ХД. Они должны быть преобразованы на логическом уровне.
Денормализация модели данных
Следующий момент в проектировании реляционных ХД состоит в решении вопроса о том, насколько важно в ХД соблюдать принципы реляционной теории, а именно: разрешить денормализацию модели, в частности, для увеличения производительности запросов. Прежде чем мы рассмотрим денормализацию модели данных в контексте складирования данных, давайте кратко вспомним основные моменты теории реляционных БД и процесса нормализации. Е.Ф. Кодд разработал реляционную теорию БД в конце 60-х прошлого века, когда он работал в исследовательском центре IBM. Сегодня большинство популярных платформ БД полностью следует этой модели. Реляционная модель БД — коллекция двухмерных таблиц, состоящих из рядов и колонок. В терминологии реляционной модели эти таблицы, строки и колонки соответственно называются отношениями или сущностями, кортежами, атрибутами (attribute) и доменами (domain). Модель идентифицирует уникальные ключи (Key) для всех таблиц и описывает отношения между таблицами через значения атрибутов (ключей).
Нормализация (Normalization) является процессом моделирования реляционной БД, где отношения или таблицы разбиваются до тех пор, пока все атрибуты в отношении полностью не будут определяться его первичным ключом. Большинство проектировщиков пытаются достичь третьей нормальной формы (3НФ) на всех отношениях до того, как они будут денормализоваться по тем или иным причинам. Три последовательных этапа нормализации реляционных БД кратко описаны ниже.
- Первая нормальная форма 1NF (1НФ). Говорят, что отношение находится в первой нормальной форме, если оно описывает одну единственную сущность и не содержит в качестве атрибутов массивов или повторяющихся групп значений. Например, таблица заказов, включающая в себя позиции заказа, не будет находиться в первой нормальной форме, поскольку содержит повторяющиеся атрибуты для каждой позиции заказа.
- Вторая нормальная форма 2NF (2НФ). Говорят, что отношение находится во второй нормальной форме, если оно находится в первой нормальной форме и все неключевые атрибуты функционально полно зависят от первичного ключа отношения.
- Третья нормальная форма 3NF (3НФ). Говорят, что отношение находится в третьей нормальной форме, если оно находится во второй нормальной форме и его неключевые атрибуты полностью независимы друг от друга.
Процесс нормализации приводит к разбиению исходного отношения на несколько независимых отношений. Каждому отношению в БД отвечает по крайней мере одна таблица. Несмотря на большую гибкость реляционной модели в представлении данных, она может быть более сложной и трудной для понимания. Кроме того, полностью нормализованная модель может быть очень неэффективной при реализации. Поэтому проектировщики БД при преобразовании нормализованной логической модели в физическую модель допускают значительную денормализацию. Основное назначение денормализации состоит в ограничении межтабличных соединений в запросах.
Еще одной из причин денормализации модели ХД является, так же, как и для операционных систем, производительность и простота. Каждый запрос в реляционных БД имеет свою стоимость выполнения (cost performance). Стоимость выполнения запросов очень высока в ХД из-за количества обрабатываемых данных в запросе (и межтабличных соединений, число которых растет пропорционально размерности модели). Соединение трех маленьких таблиц в OLTP-системе может иметь приемлемую стоимость выполнения запроса, но в системе складирования данных выполнение такого соединения может занять очень много времени.
Статичность взаимосвязей в исторических данных
Денормализация является важным процессом в моделировании ХД: взаимосвязь между атрибутами не изменяется для исторических данных. Например, в OLTP-системах товар может быть частью другого товара группы "А" в этом месяце и частью товара группы "В" в следующем месяце. В нормализованной модели данных для отображения этого факта необходимо включить атрибут "группа товаров" в отношение (сущность) "товар", но не в отношение (сущность) "заказ", которая формирует заказы на этот товар. В сущность "заказ" включается только идентификатор товара. Реляционная теория будет требовать соединения между таблицами "Заказ" и "Товар" для определения группы товаров и других атрибутов этого продукта. Этот факт (функциональная зависимость) не имеет значения для ХД, поскольку сохраняемые данные относятся к уже выполненным заказам, т.е. принадлежность товара группе уже зафиксирована (фактически указанная функциональная зависимость не поддерживается). Даже если товар принадлежал различным группам в разное время, взаимосвязь между группой товаров и товаром каждого отдельного заказа статична. Таким образом, это не является денормализацией для ХД. В данном случае функциональная зависимость OLTP-системы не используется в ХД.
В качестве другого примера возьмем цену товара. Цены в OLTP-системе могут изменяться постоянно. Некоторые изменения этих цен могут быть перенесены в ХД, как периодические снимки таблицы "Цена товара". В ХД история прайс-листа товара зафиксирована и уже привязана к заказам, т.е. не нужно динамически определять прайс-лист при обработке заказа, поскольку он уже был применен к сохраненному заказу. В реляционных БД проще поддерживать динамические взаимоотношения между сущностями бизнеса, в то время как ХД содержит взаимосвязи между сущностями предметной области в заданное время.
Концепция логического преобразования данных приложений-источников, рассмотренная выше, требует определенных усилий при реализации и очень полезна при разработке ХД.
Физическое преобразование данных приложений источников
Важным моментом в системах складирования данных является физическое преобразование данных. Эти процедуры в складировании данных известны как процессы очистки данных ("data scrubbing", "data staging" или "data purge"). Процесс очистки данных является наиболее интенсивным и трудоемким в любом проекте создания ХД. Физическое преобразование включает использование стандартных терминов предметной области ХД и стандартов данных. В течение процесса физического преобразования данные находятся в некотором промежуточном файле до того, как будут занесены в ХД. Когда данные собираются из многих приложений, их целостность может быть проверена в течение процесса формирования преобразованных данных до загрузки в ХД.
Термины и имена атрибутов сущностей, используемые в OLTP-системах, в процессе преобразования данных для ХД преобразуются в универсальные, стандартные термины, принятые для данной сферы бизнеса. Приложения могут использовать сокращения или трудные для понимания термины по множеству различных причин. Программно-аппаратная платформа может ограничивать длину и формат имен, а бизнес-приложения могут применять в разных предметных областях общие термины. В ХД необходимо пользоваться стандартными бизнес-терминами, которые понятны сами по себе большинству пользователей.
Идентификатор клиента (покупателя) в OLTP-системе может быть назван "Покуп.", "покуп_ид" или "покуп_но". Далее, различные приложения таких систем могут использовать различные имена (синонимы) при ссылке к одному и тому же атрибуту сущности. Проектировщик ХД выбирает простой стандартный бизнес-термин, такой, как "Идентификатор клиента". Таким образом, имена атрибутов сущностей из подающих систем должны быть унифицированы для использования в ХД.
Различные подсистемы OLTP-систем и внешних источников данных могут использовать различное определение доменов атрибутов на физическом уровне представления данных. Так, атрибут типа "идентификатор продукта" в одной системе имеет длину от 12 символов, а в другой — 18 символов. С другой стороны, ПО одних существующих систем может иметь ограничения на определение длин имен атрибутов и бедный набор типов для определения доменов, а в других такие ограничения могут отсутствовать и может предоставляться широкий выбор типов атрибутов.
При определении атрибутов в физической модели ХД необходимо использовать такие длины и типы данных в определении домена атрибута, которые позволили бы учесть как требования предметной области, так и возможности систем — источников данных. Определение стандартов доменов для ХД является одной из важных задач проектировщиков ХД. Правила преобразования доменов атрибутов систем — источников данных в домены атрибутов ХД следует фиксировать в метаданных ХД.
Все атрибуты в ХД должны согласованно использовать предопределенные значения. В различных приложениях могут быть приняты различные соглашения по предопределенным значениям атрибутов. К таким предопределенным значениям относятся значения по умолчанию, значения, заменяющие null-значения, и т. п. Например, признак пола в различных системах может иметь различные значения: в одних это символьные значения "М" и "Ж", в других — цифровые значения 0 и 1. Более неприятным примером является случай, когда одно значение данных используется в приложении в нескольких целях, т.е. атрибут на самом деле представляет множественное значение. Например, когда в атрибуте "тип метода измерения" две первые цифры означают метод измерения, а две вторые — метод физического контроля измерения. Такие различные значения перед загрузкой в ХД должны быть преобразованы к принятому в ХД предопределенному значению.
В некоторых системах — источниках данных могут отсутствовать значения (проблема пропущенных значений, "missing data") или преобразование для них не может быть выполнено ("corrupt data" — данные, для которых преобразование не может быть выполнено). Важно, чтобы в процессе преобразования такие данные принимали в ХД значения, которые позволяли бы пользователям интерпретировать их правильно. Одним атрибутам можно просто назначить разумное значение по умолчанию в случае отсутствия значения или конфликтов при преобразовании, а другим атрибутам — определить значения из значений прочих атрибутов. Например, пусть в сущности "Заказ" значение атрибута единицы измерения товара пропущено. Это значение может быть получено из соответствующего атрибута сущности "Товар" этой системы-источника. Для некоторых атрибутов не существует подходящих значений по умолчанию в случае, когда их значения отсутствуют. Для таких пропущенных значений в ХД следует также определять значение по умолчанию, например, как null-значение.
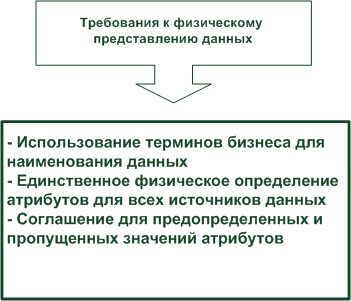
Таким образом, в процессе преобразования данных проектировщик ХД должен привести данные систем-источников к определенным стандартам ( рис. 1.6), а именно:
- стандартизовать наименования атрибутов в ХД;
- определить одинаковые домены для одних и тех же атрибутов различных систем-источников;
- принять соглашения о значениях по умолчанию для пропущенных данных;
- принять соглашения о предопределенных значениях атрибутов.
В табл. 1.1 приведены основные отличия использования данных в системах операционной обработки данных и системах анализа данных.
Владислав Нагорный
Лариса Парфенова
|
1) Можно ли экстерном получить второе высшее образование "Программная инженерия" ? 2) Трудоустраиваете ли Вы выпускников? 3) Можно ли с Вашим дипломом поступить в аспирантуру?
|