
| Россия, г. Москва |
Инспектор
Вы можете этот курс.
Опубликован: 11.05.2007 | Уровень: специалист | Доступ: платный
Лекция 4:
Сериализация объектов. Способы сериализации в .NET Framework
Аннотация: Рассматривается понятие графа объектов и проблема его передачи между двумя компьютерами.
Описывается проблема сериализация графа объектов, приводится классификация методов сериализации.
Приводятся описание различных методов сериализации, которые используются в .NET Framework, и их особенностей.
Ключевые слова: net, CLR, ПО, поток, объект, очередь, граф, CLI, сериализация, ориентированное дерево, ребро, вершина, информация, функция, значение, ссылка, список, вершины графа, адрес, обход графа, XML, корнем дерева, дерево, класс, message queuing, enterprise, Web, передача данных, закрытые методы, открытый метод, ASP, представление, открытые спецификации, десериализация, тип данных, компонент, поле, интерфейс, атрибут, место, конструктор, индексированное свойство, FCL, ключ, связь, XSD, файл, тип объекта, контейнерный класс, утилита, команда, WSDL, сборка, программа, операции, SGEN, .NET Remoting, SOAP, пространство имен, поля класса, методы класса, статический метод, доступ
4.1. Сериализация графа объектов
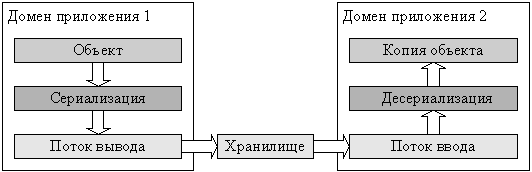
В отличие от приложений на неуправляемом коде, приложения .NET Framework не обязательно выполняются в виде отдельных процессов, а могут существовать в пределах одного процесса операционной системы в своих собственных областях, называемых доменами приложения. Такие области можно рассматривать как некоторые логические процессы виртуальной машины CLR. Использование управляемого кода позволяет при этом гарантировать изоляцию приложений в пределах своих областей. При передаче между доменами приложений некоторого объекта для его класса должна быть определена процедура сериализации, которая позволяет сохранить состояние объекта в некотором внешнем хранилище (например, в файле, или в сообщении транспортного протокола) при помощи потоков ввода-вывода, и процедура десериализации, создающая копию объекта по сохраненному состоянию (рис. 4.1). Следует отметить, что в общем случае это могут быть объекты разных классов, и даже созданные в разных системах разработки приложений.
Задача сериализации объекта, включающего только поля из элементарных типов значений (наследников класса System.ValueType ) и строк, не представляет принципиальных трудностей. Для такого объекта в ходе сериализации в поток записываются сами значения всех полей объекта. Однако в общем случае объект содержит ссылки на другие объекты, которые, в свою очередь, могут ссылаться друг на друга, образуя так называемый граф объектов ( object graph ). Сами ссылки не могут быть сохранены в потоке ввода-вывода, поэтому основной вопрос сериализации – это способ замены ссылок.
Граф объектов – ориентированный граф G = < V, E > , в котором вершины – это объекты (множество V ), а ребра направлены от объектов, содержащие ссылки, на ссылаемые объекты (рис. 4.2).
public class SampleClass
{
public SampleClass fieldA = null;
public SampleClass fieldB = null;
}
...
SampleClass root = new SampleClass();
SampleClass child1 = new SampleClass();
SampleClass child2 = new SampleClass();
root.fieldA = child1;
root.fieldB = child2;
child1.fieldA = child2;
...Наличие ссылки на объект B в объекте A есть принадлежность пары < A, B > множеству E. При рассмотрении графа все поля объектов, относящиеся к простым типам значениям и строкам, можно исключить из рассмотрения в силу тривиальности их сериализации. Хотя формально строки являются ссылочными типами, особенность реализации строк в CLI не дает возможность изменить уже созданную строку. Эта особенность позволяет тривиально обрабатывать строки при сериализации, сохраняя в потоке их содержимое.
Существует частный случай, когда сериализация выполняется тривиально. Для этого граф должен иметь вид так называемого ориентированного дерева. В каждую вершину дерева, отличную от корня, направлено единственное ребро, и существует единственная вершина, в которую не ведет ни одного ребра, называемая корнем. В таком случае сериализация может вестись от корня методом в глубину, а сериализация полей-ссылок выполняется аналогично сериализации полей значений – при обнаружении ссылки на объект вместо нее в хранилище помещаются значения полей ссылаемого объекта и некоторая дополнительная информация о типе объекта. Например, если существуют ребра < A, B1>, ... < A, Bn >, функция сериализации S для объекта A может быть определена как S(A) = < V(A), <S(B1), ... S(Bn)>> , где функция V – значение полей значений и строк указанного объекта.
Проблема сериализации графа объектов связана с тем, что ссылка на один и тот же объект может быть значением поля у разных объектов (существуют ребра < A1, B> и < A2, B > ). Возможно также наличие циклов вида A -> ... -> A.
В этом случае в ходе сериализации объектам должны быть поставлены в соответствие некоторые идентификаторы, и в хранилище отдельно сохраняется список объектов, отмеченный идентификаторами, а при сериализации вместо ссылок записываются идентификаторы ссылаемых объектов. Если A1, ... An – все вершины графа, то его образом после сериализации будет множество {<idA1, S(A1)>, ... <idAn, S(An)>} , где S(A) определена как S(A) = < V(A), <idB1, ... idBn> > , где B1, ... Bn – объекты, ссылки на которые непосредственно содержатся в объекте A. В программе роль идентификатора объекта выполняет его адрес, но вместо него обычно удобнее назначить некоторые идентификаторы в процедуре сериализации для более легкого чтения человеком полученного образа. В ходе сериализации нужно ввести список адресов уже записанных объектов, как для ведения списка идентификаторов, так и для обнаружения возможных циклов при обходе графа методом в глубину.
Следует отметить, что результат сериализации дерева легко представим в виде XML, когда содержимое каждого объекта представлено одним элементом с некоторым набором атрибутов и вложенных элементов. Поэтому при рассмотрения проблемы сериализации можно сформулировать рекомендацию, что классы, передаваемые между удаленными компонентами, должны являться корнем дерева объектов. В частном случае это дерево может быть вырожденным, то есть класс не содержит полей-ссылок вообще.
4.2. Методы сериализации в .NET Framework
Microsoft .NET Framework 2.0 поддерживает четыре технологии удаленного взаимодействия – Message Queuing, Enterprise Services, Remoting, Web services. Какая бы технология не была выбрана, в любом случае передача данных между удаленными компонентами является одним из основных моментов удаленного взаимодействия. Данные могу передаваться как сообщение в очереди (MSMQ) или как параметры удаленного вызова и результат вызываемой функции (остальные технологии). В любом случае, для реализации распределенной системы необходимо определить процедуры сериализации и десериализации для передаваемых классов.
Классы, производящие сериализацию и десериализацию в .NET Framework, называются классами форматирования ( formatters ). Не считая служащего для обеспечения совместимости ActiveXMessageFormatter, в .NET Framework выделяется три различных независимых класса форматирования: XmlSerializer, SoapFormatter, BinaryFormatter. Они используются как для записи и чтения объектов из потоков ввода-вывода, так и для построения распределенных систем:
- технология веб служб ASP.NET использует XmlSerializer ;
- технология Remoting использует SoapFormatter, BinaryFormatter или созданный пользователем класс;
- при работе с сообщениями MSMQ используется XmlSerializer (через XMLMessageFormatter ), или BinaryFormatter (через BinaryMessageFormatter ), или созданный пользователем класс;
- технология Enterprise Services основана на Remoting и использует BinaryFormatter.
Можно провести классификацию возможных методов сериализации по следующим основным признакам.
1. Классификация по виду обрабатываемого графа:
- универсальные методы: граф произвольного вида с циклами;
- произвольный ациклический граф;
- дерево.
2. Классификация по формату хранения информации в хранилище:
- бинарные методы, использующие двоичный формат хранения данных, который не пригоден для чтения человеком без использования специальных средств;
- текстовые методы, используют XML или иные текстовые форматы, пригодные для чтения или редактирования человеком при использовании текстового редактора.
3. Классификация по спецификации формата данных, полученного в результате сериализации:
- закрытые методы: спецификация задается только при помощи интерфейсов всех классов, объекты которых образуют граф; в этом случае обе удаленные компоненты должны быть созданы на одной языковой платформе, причем обе стороны должны иметь как минимум описание интерфейса сериализуемых классов;
- открытые методы: спецификация может быть задана в виде общепринятого формата, например схемы XSD.
По данной классификации XmlSerializer реализует открытый текстовый неуниверсальный метод, BinaryFormatter – закрытый двоичный универсальный метод, SoapFormatter – текстовый открытый метод. Дополнительной особенностью каждого из классов, за исключением BinaryFormatter, является ограничения на классы, которые подлежат сериализации. Данные ограничения будут рассмотрены далее.