| Россия |
Инспектор
Вы можете этот курс.
Опубликован: 28.04.2010 | Уровень: специалист | Доступ: платный | ВУЗ: Новосибирский Государственный Университет
Лекция 9:
Событийно-ориентированные архитектуры
Аннотация: У многих современных программистов слова "событийно-ориентированная архитектура"
ассоциируются в первую очередь с библиотеками для разработки графических
пользовательских интерфейсов - AWT/Swing, Qt и др. В действительности, событийно-ориентированные архитектуры были изобретены гораздо раньше и совсем для других целей,
только тогда еще никто не знал, что это так называется. Событийно-ориентированную
архитектуру имеют ядра операционных систем (в том числе систем семейства Unix), многие
серверные приложения и приложения реального времени. В ходе этой лекции вы изучите событийно-ориентированную архитектуру типичного
серверного приложения и получите обзор других подходов к реализации и использованию
событийно-ориентированных архитектур.
Ключевые слова: программа, ПО, объект, операции, очередь, обработка событий, файл, архитектура, драйвер устройства, указатель, драйвер, исключение, ядро, запись, Write, диспетчер, interrupt, символьное устройство, запрос, DEC, RSX-11, VMS, IP, RAW, конечный автомат, граф, матрица инцидентности, UML, диаграммы активностей, сообщение об ошибке, контроллер, пользователь, бит, контекст, стек, счетчик команд, системный вызов, исполнение, приложение, менеджер, POSIX, thread, пул, worker, HTTP, сервер, сокет, слушающий сокет, запуск процесса, процессорное время, асинхронный ввод/вывод, кэш, TCP/IP, множества, Internet, строка запроса, Windows, MTU, NOT, браузер, остаток, URL, разрыв соединения, идентификатор, буфер, reallocation, мегабайт, гигабайт, HD-DVD, память, DNS, API, интеграция
Обработка событий
Идею, лежащую в основе событийно-ориентированной архитектуры, можно описать следующим образом. программа рассматривается как набор объектов, реагирующих на события. События могут быть как внешними по отношению к системе - например, нажатие пользователем левой кнопки мыши, приход очередной порции данных из сетевого соединения, сработкой датчика в системе реального времени - так и внутренними. Внутренние события объекты-обработчики используют для коммуникации друг с другом.
Желая обрабатывать события определенного типа, программист регистрирует объект-обработчик.
При возникновении события, система вызывает метод объекта, ассоциированный с этим событием. Метод обрабатывает событие (возможно, генерируя при этом события, предназначенные другим объектам) и завершается. Если методы всех обработчиков выполняют свои операции быстро и без применения блокирующих системных вызовов, можно обеспечить высокую скорость реакции на события даже в рамках однопоточной программы. Если события поступают быстрее, чем обработчики успевают их обрабатывать, система выстраивает их в очередь.
В типичной системе с графическим пользовательским интерфейсом обработка событий происходит в несколько этапов. Рассмотрим простой пример окна с кнопкой "OK". Окна во всех системах графического интерфейса представляют собой обработчики событий. При добавлении кнопки в окно регистрируется еще один обработчик событий, связанный с кнопкой. Все, что делает этот обработчик при нажатии мышью на кнопку - генерирует командное событие, предназначенное окну. Далее,если наше окно представляет собой не главное окно приложения, а модальный диалог (например, диалог открытия файла), обработка командного события от кнопки "ОК" может свестись к посылке командного события главному окну - в случае диалога открытия файла это командное событие должно содержать команду "открыть файл" с указанным именем файла.
Основные идеи, лежащие в основе современных графических интерфейсов, были разработаны во второй половине 1970х в исследовательской лаборатории XeroxPARC. Однако сама по себе событийно ориентированная архитектура была придумана еще в 60е годы XX столетия и использовалась в ядрах операционных систем, главным образом при реализации подсистемы ввода-вывода. Драйвер устройства для типичной многозадачной ОС представляет собой набор функций ("точек входа") и блок переменных состояния устройства. Указатель на этот блок переменных состояния передается каждой из функций драйвера в качестве параметра. Благодаря этому, драйвер может обслуживать несколько однотипных устройств - ему для этого достаточно создать и зарегистрировать несколько блоков переменных состояния.
Фактически, драйвер представляет собой нечто очень похожее на объект в объектно-ориентированном программировании, однако в большинстве ОС драйверы до сих пор разрабатываются на не-объектно-ориентированных языках, чаще всего на C или даже на ассемблере. Наиболее известное исключение представляет ОС Apple Darwin (ядро MacOS X), в которой драйверы разрабатываются на специализированном подмножестве C++.
Драйвер обслуживает несколько потоков событий. Типичный драйвер физического устройства обслуживает два потока событий - запросы от пользовательских программ и прерывания от устройства. В простейшем случае обслуживание обоих типов событий состоит в том, что у драйвера вызываются соответствующие функции: при формировании запроса на запись пользовательская программа (при посредстве диспетчера системных вызовов) зовет функцию write драйвера, а при обработке прерывания ядро системы (точнее, диспетчер прерывания) вызывает функцию interrupt того же самого драйвера. Защита от одновременного вызова этих функций возлагается на драйвер и часто состоит в том, что драйвер запрещает прерывания на время работы критических секций своей функции write. Такая архитектура используется драйверами символьных устройств в старых (так называемых "монолитных") ядрах Unix-систем.
При работе с блочными устройствами, а в более современных Unix-системах также с символьными устройствами STREAMS, используется более совершенная архитектура, когда запросы пользовательских программ ставятся в очередь к драйверу. Каждый запрос снабжается кодом запроса (чтение, запись, ioctl). В некоторых ОС, например в DEC RSX-11 и VMS, такая архитектура была единственно допустимой архитектурой для драйверов.
Многие драйверы вынуждены иметь дело с множественными потоками событий. Так, например, драйвер сетевого протокола IP в машине с несколькими сетевыми интерфейсами должен обслуживать потоки событий от драйверов всех этих интерфейсов, потоки событий от драйверов протоколов транспортного уровня, а также, возможно, потоки событий от приложений, работающих с сетью напрямую, через сокеты типа RAW.
Драйвер, допускающий одновременную работу с устройством нескольких пользовательских процессов, должен обеспечивать обслуживание нескольких потоков пользовательских запросов.
С формальной точки зрения обработчик событий удобнее всего описывать в виде конечного автомата. Конечный автомат описывается в виде набора допустимых состояний и набора допустимых переходов между ними, т.е. представляет собой ориентированный граф. Этот граф может описываться как матрицей инцидентности (таблицей состояний), так и картинкой, состоящей из коробочек (состояний) и стрелочек (переходов), например, диаграммой состояний UML. В некоторых случаях применяют также диаграмму, в которой переходы ("активности") изображаются в виде коробочек, а состояния - в виде стрелочек, например диаграмма активностей UML (см. рис. 9.1). В действительности эти два типа диаграмм - два разных способа описания одного и того же.
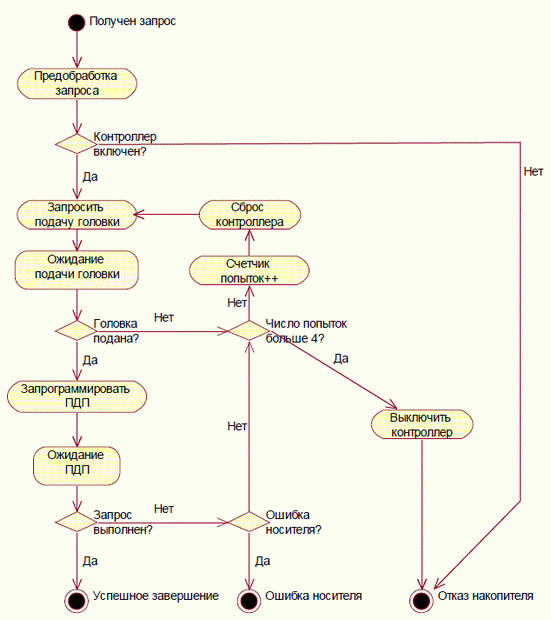
Рис. 9.1. Диаграмма активностей для обработки одного запроса драйвером привода для гибких магнитных дисков (для упрощения диаграммы опущено включение мотора и ожидание разгона диска до рабочей скорости)
При реализации конечного автомата, состояние кодируется одной из переменных в блоке переменных состояния автомата, а переходы инициируются источниками событий. Если источник событий пытается инициировать недопустимый переход (послать событие, которое обработчик сейчас не может или не должен обрабатывать), возможны разные стратегии поведения. Соответствующее событие может просто игнорироваться (на графе состояний это изображают кольцевой стрелкой, выходящей из состояния и возвращающейся в то же самое состояние), порождать встречное сообщение об ошибке или ставиться в очередь. В некоторых случаях обработчик может блокировать нежелательные для него источники событий - например, в графическом интерфейсе контроллер диалогового окна может заблокировать кнопку ОК, пока пользователь не введет в поля диалога все необходимые данные, а драйвер может заблокировать прерывания от устройства, установив соответствующую комбинацию бит в регистрах устройства.
Сравнение обработки событий и многопоточных приложений
С точки зрения нашего курса, интересно сравнить классические многопроцессные и многопоточные приложения с событийно-ориентированными.
В многопоточном приложении для каждой нити (потока) создается иллюзия последовательного исполнения. При переключении управления на другую нить система сохраняет контекст нити (в первую очередь стек и счетчик команд, но также и другие регистры процессора), а при возврате управления нашей нити - восстанавливает все эти регистры. Нить может хранить свое состояние в различных областях памяти - в регистрах, в стеке,в thread-specific data. Если нити необходимо обработать внешнее (по отношению к ней) событие, она блокируется в ожидании этого события, исполняя блокирующийся системный вызов или библиотечную функцию. После выхода из блокировки ее исполнение продолжается с той же точки, в которой было остановлено.
В событийно-ориентированной архитектуре, для методов обработчика событий не создается иллюзии последовательного исполнения. Если методу обработчика надо перейти к обработке следующего события, он просто завершается. Когда следующее событие возникнет, система его позовет. Таким образом, обработчик событий не имеет собственного контекста. Он должен хранить все свое состояние в блоке переменных состояния.
Таким образом, главное отличие между традиционными многопоточными и событийно-ориентированными приложениями можно описать так: многопоточное приложение блокируется на примитивах взаимодействия с источниками событий с сохранением контекста нити. Событийно-ориентированное приложение блокируется на примитивах взаимодействия с источниками событий с уничтожением контекста нити. На практике, разумеется, контекст нити обычно не уничтожается, а переиспользуется для обработки других событий другими обработчиками.
Как правило, переиспользование контекста достигается за счет того, что нить, которая вызывает методы обработчиков событий, исполняет цикл менеджера или диспетчера событий. Менеджер событий опрашивает источники событий, при отсутствии событий - блокируется, а при появлении событий - диспетчеризует события обработчикам.
Из такого описания очевидно, что событийно-ориентированная архитектура гораздо дешевле при исполнении, чем классическая многопоточная при обработке того же потока событий. Ей требуется гораздо меньше ресурсов - памяти для хранения контекстов и процессорного времени для сохранения и восстановления этих контекстов - чем классической многопоточной архитектуре.
Из такого описания понятны также возможные подходы к построению гибридной архитектуры. Действительно, при всех своих достоинствах, событийно-ориентированная архитектура предъявляет довольно жесткие требования к обработчикам событий - они должны завершаться за небольшое время и нигде не блокироваться. Далеко не для всех задач легко выполнить эти требования. Обработка некоторых событий может требовать длительных вычислений. Другие события могут иметь такую природу, что их нельзя включить в цикл опроса диспетчера событий. Например, если диспетчер событий опрашивает источники событий при помощи select/poll, мы не можем включить в этот цикл события, связанные с примитивами синхронизации POSIX ThreadsAPI. В третьем случае мы можем быть вынуждены в рамках обработки события запускать код, написанный другими программистами для других целей; этот код может ничего не знать про событийно-ориентированную архитектуру и про то, что ему нельзя блокироваться.
В этих случаях может оказаться целесообразной архитектура с несколькими менеджерами событий, исполняющимися в нескольких разных потоках.
Существует несколько вариантов такой архитектуры - асинхронная очередь сообщений, preforked processes, thread pool (пул нитей), рабочие нити (worker threads). В действительности, классификация вариантов этой архитектуры не является общепринятой и поэтому разные поставщики программного обеспечения часто называют одно и то же разными названиями, а разные архитектуры - одинаковыми терминами.
Так, например, популярный HTTP-сервер Apache 1.х имел следующую архитектуру. При запуске, основной процесс Apache привязывал сокет к порту 80 и, если это необходимо, создавал сокеты и привязывал их к другим обслуживаемым портам. Затем этот процесс несколько раз исполнял fork(2), создавая свои копии. Все эти копии наследовали слушающие сокеты, и блокировались в вызове accept(3SOCKET) (в действительности, на select(3C) с ожиданием всех слушающих сокетов). При приходе запроса на соединение, у одного из процессов accept разблокировался и этот процесс начинал обработку этого запроса. Разумеется, обработка запроса включает в себя многочисленные блокировки на вызовах read(2) и write(2) ; кроме того, обработка может включать в себя загрузку модулей и cgi-скриптов, которые исполняют практически произвольный код и, вообще говоря, могут блокироваться на чем угодно, чаще всего - на обращениях к базе данных. Если в это время приходит еще один запрос, его должен подхватить другой процесс.
Когда процесс Apache завершает обработку запроса, он не завершается, а возвращается к вызову accept и блокируется в ожидании следующего соединения. Таким образом, сервер не тратит время и ресурсы на запуск процесса при поступлении каждого нового запроса на соединение, но, тем не менее, каждое соединение все равно обслуживается отдельным процессом. Именно эта архитектура и называется preforked processes, или, если вместо процессов мы используем нити, пулом нитей (thread pool). Видно, что это частный случай событийно-ориентированной архитектуры, при которой обрабатываемым событием считается приход нового запроса на соединение.
Количество процессов, запускаемых Apache, подбирается эмпирически исходя из производительности сервера, потока запросов, скорости каналов, по которым приходят эти запросы, и среднего времени исполнения скриптов на страницах веб-сайта.
Несмотря на простоту этой архитектуры, она обладает очевидным недостатком. Если все процессы сервера заблокированы на том или ином системном вызове, это означает, что сервер имеет ресурсы (во всяком случае, процессорное время) для обработки еще одного соединения - но для этого ему надо запускать еще один процесс!
Чтобы обойти эту проблему, нам следует считать отдельным событием не приход нового запроса на соединение, а готовность каждого из соединений к приему и передаче данных. На предыдущей лекции мы изучали средства, которые специально предназначены для диспетчеризации таких событий - select(3C), poll(2), порты Solaris. Можно также считать событием не готовность соединений к приему и передаче данных, а завершение предыдущего запроса или группы запросов к этому соединению. В таком случае необходимо использовать асинхронный ввод/вывод, а для диспетчеризации событий можно использовать aio_suspend(3AIO), aio_wait(3AIO ), sigwait(2) (в сочетании с использованием сигналов для оповещения о завершении запроса) или опять-таки порты Solaris.
Обсуждаемую архитектуру невозможно реализовать при использовании preforked процессов. Действительно, чтобы один процесс мог обслуживать несколько соединений, он либо должен сделать accept(3SOCKET) на все эти соединения, либо должен быть запущен уже после того, как родитель сделает этот accept. Оба варианта противоречат самой идее preforked processes. Поэтому наиболее естественным вариантом для реализации предлагаемой архитектуры является многопоточное приложение.