

|
Подскажите, пожалуйста, планируете ли вы возобновление программ высшего образования? Если да, есть ли какие-то примерные сроки? Спасибо! |
Инспектор
Вы можете этот курс.
Опубликован: 18.09.2006 | Уровень: специалист | Доступ: платный | ВУЗ: Московский государственный университет имени М.В.Ломоносова
Лекция 7:
Образцы проектирования
Каналы и фильтры
Название. Каналы и фильтры (pipes and filters).
Назначение. Организация обработки потоков данных в том случае, когда процесс обработки распадается на несколько шагов. Эти шаги могут выполняться отдельными обработчиками, возможно, реализуемыми разными разработчиками или даже организациями. При этом нужно принимать во внимание следующие факторы:
Действующие силы.
- Должны быть возможны изменения в системе за счет добавления новых способов обработки и перекомбинации имеющихся обработчиков, иногда самими конечными пользователями.
- Небольшие шаги обработки проще переиспользовать в различных задачах.
- Не являющиеся соседними обработчики не имеют общих данных.
- Имеются различные источники входных данных — сетевые соединения, текстовые файлы, сообщения аппаратных датчиков, базы данных.
- Выходные данные могут быть востребованы в различных представлениях.
- Явное хранение промежуточных результатов может быть неэффективным, создаст множество временных файлов, может привести к ошибкам, если в его организацию сможет вмешаться пользователь.
- Возможно использование параллелизма для более эффективной обработки данных.
Решение. Каждая отдельная задача по обработке данных разбивается на несколько мелких шагов. Выходные данные одного шага являются входными для других. Каждый шаг реализуется специальным компонентом — фильтром (filter). Фильтр потребляет и выдает данные инкрементально, небольшими порциями. Передача данных между фильтрами осуществляется по каналам (pipes).
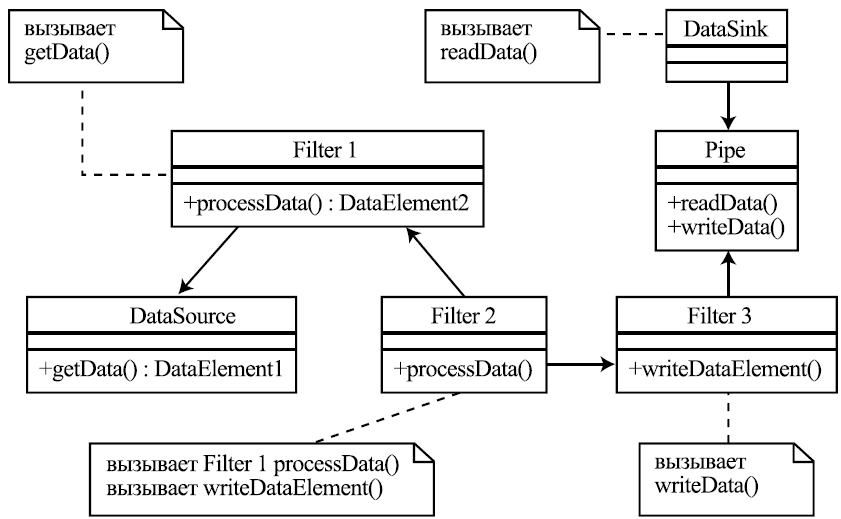
Структура. Основными ролями компонентов в рамках данного стиля являются фильтр и канал. Иногда выделяют специальные виды фильтров — источник данных (data source) и потребитель данных (data sink), которые, соответственно, только выдают данные или только их потребляют. Каждый поток обработки данных состоит из чередующихся фильтров и каналов, начинается источником данных и заканчивается их потребителем.
Фильтр получает на свой вход данные и обрабатывает их, дополняя их результатами обработки, удаляя какие-то части и трансформируя их в некоторое другое представление. Иногда фильтр сам требует входные данные и выдает выходные по их получении, иногда он, наоборот, может реагировать на события прихода данных на вход и требования данных на выходе. Фильтр обычно потребляет и выдает данные некоторыми порциями.
Канал обеспечивает передачу данных, их буферизацию и синхронизацию обработки их соседними фильтрами (например, если оба соседних фильтра активны, работают в параллельных процессах). Если никакой дополнительный буферизации и синхронизации не требуется, канал может представлять собой простую передачу данных в виде параметра или результата вызова операции.
На рис. 7.7 показан пример диаграммы классов для данного образца, в котором 3 канала реализованы неявно — через вызовы операций и возвращение результатов, а один — явно. Из участвующих в этом примере фильтров источник и потребитель данных, а также Filter 1 запрашивают входные данные, Filter 3 сам передает их дальше, а Filter 2 и запрашивает, и передает данные самостоятельно.
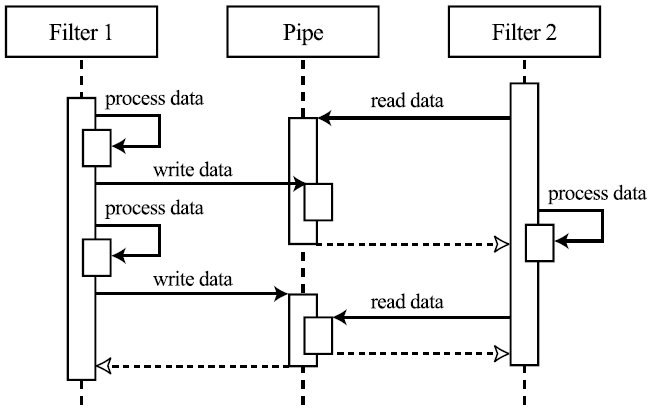
Динамика. Возможны три различных сценария работы одного фильтра — проталкивание данных (push model, фильтр сам передает данные следующему компоненту, а получает их только в результате передачи предыдущего), вытягивание данных (pull model, фильтр требует данные у предыдущего компонента, следующий сам должен затребовать данные у него) и смешанный вариант. Часто реализуется только один вид передачи данных для всех фильтров в рамках системы. Кроме того, канал может буферизовать данные и синхронизовать взаимодействующие с ним фильтры. Сценарии работы системы в целом строятся в виде различных комбинаций вариантов работы отдельных фильтров.
Реализация. Основные шаги реализации следующие:
- Определить шаги обработки данных, необходимые для решения задач системы. Очередной шаг должен зависеть только от выходных данных предшествующего шага.
- Определить форматы данных при их передаче по каждому каналу.
- Определить способ реализации каждого канала, проталкивание или вытягивание данных, необходимость дополнительной буферизации и синхронизации.
- Спроектировать и реализовать необходимый набор фильтров. Реализовать каналы, если для их представления нужны отдельные компоненты.
- Спроектировать и реализовать обработку ошибок. Обработку ошибок при применении этого стиля достаточно тяжело организовать, поэтому ею часто пренебрегают. Однако требуется, как минимум, адекватная диагностика случающихся на разных этапах ошибок.
Могут быть выделены специальные каналы для передачи сообщений об ошибках.
При возникновении ошибок ввода соответствующий фильтр может игнорировать дальнейшие входные данные до получения определенного разделителя, гарантирующего, что после него идут данные, не связанные с предыдущими.
- Сконфигурировать необходимый конвейер обработки данных, собрав вместе нужные фильтры и соединяющие их каналы.
Следствия применения образца.
Достоинства:
- Промежуточные данные могут не храниться в файлах, но могут и храниться, если это необходимо для каких-то дополнительных целей.
- Фильтры можно легко заменять, переиспользовать, менять местами, переставлять и комбинировать, реализуя множество функций на основе одних и тех же компонентов.
- Конвейерные системы обработки данных могут быть разработаны очень быстро, если имеется богатый набор фильтров.
- Активные фильтры могут работать параллельно, давая в результате более эффективное решение на многопроцессорных системах.
Недостатки:
- Управление обработкой с помощью большого общего состояния, которое иногда необходимо, не может быть эффективно реализовано с помощью этого стиля.
- Часто параллельная обработка не приносит никакого повышения производительности, поскольку передача данных между фильтрами может быть достаточно дорогой, фильтры могут требовать всех входных данных, прежде чем выдадут хоть что-то, и их синхронизация с помощью каналов может приводить к значительным простоям.
- Часто фильтры большее время тратят на преобразование формата поступающих входных данных, чем на их обработку. Использование одного формата, например, текстового, также зачастую снижает эффективность их использования.
- Обработка ошибок в рамках данного стиля очень сложна. В том случае, если разрабатываемая система должна быть очень надежной, а возвращение к самому началу работы в случае обнаружения ошибки, а также ее игнорирование, не являются допустимыми сценариями, использовать этот стиль не стоит.
Примеры. Наиболее известный пример использования данного образца — система утилит UNIX [8], пополненная возможностями оболочки (shell) по организации каналов между процессами. Большинство утилит могут играть роль фильтров при обработке текстовых данных, а каналы строятся при помощи соединения стандартного ввода одной программы со стандартным выводом другой.
Другим примером может служить часто используемая архитектура компилятора как последовательности фильтров, обрабатывающих входную программу — лексического анализатора (лексера), синтаксического анализатора (парсера), семантического анализатора, набора оптимизаторов и генератора результирующего кода. Таким способом можно достаточно быстро построить прототипный компилятор для несложного языка. Более производительные компиляторы, нацеленные на промышленное использование, строятся по более сложной схеме, в частности, используя элементы стиля "Репозиторий".
Владислав Нагорный
Лариса Парфенова
|
1) Можно ли экстерном получить второе высшее образование "Программная инженерия" ? 2) Трудоустраиваете ли Вы выпускников? 3) Можно ли с Вашим дипломом поступить в аспирантуру?
|