| Германия, Limburgerhof |
Инспектор
Вы можете этот курс.
Опубликован: 15.10.2008 | Уровень: профессионал | Доступ: платный
Лекция 15:
Кластеризация
Управление NLB-кластером с помощью Nlb.exe
После установки и конфигурирования службы NLB вы можете управлять ее операциями (и изменять настройки некоторых параметров) с помощью программы управления Network Load Balancing ( Nlb.exe ).
Вы можете использовать программу Nlb.exe, находящуюся в папке %SystemRoot%\System32, с хостов кластера или с любого удаленного компьютера Windows Server 2003, который может получать доступ к кластеру через локальную или глобальную сеть. Nlb.exe - это программа, которая позволяет администраторам писать и выполнять скрипты командной строки для упрощения администрирования.
Внимание. Nlb.exe нельзя использовать для изменения параметров хоста с удаленного компьютера, хотя вы можете просматривать информацию об удаленном компьютере.
Nlb.exe имеет следующий синтаксис.
nlb <команда> [<кластер>[:<хост>] [/passw [<пароль>]] [/port <порт>]]
где:
команда - одна из поддерживаемых команд (см. ниже); при доступе к кластеру с удаленного компьютера используются следующие параметры.
- кластер - основной IP-адрес кластера.
- хост - IP-адрес хоста в этом кластере (если не указан, то все хосты).
- /passw <пароль> - пароль для удаленного доступа.
- /port <порт> - порт UDP для удаленного доступа к кластеру.
Имеются следующие команды.
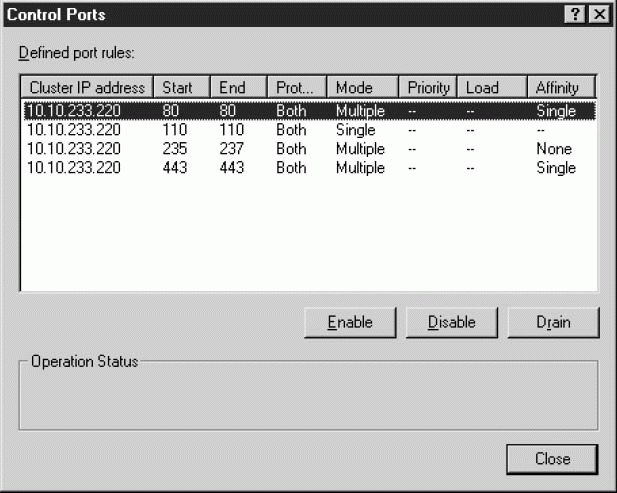
- ip2mac <кластер>. Преобразует IP-адрес кластера в MAC-адрес кластера.
- reload. Перезагружает параметры из реестра; действует только на локальной машине.
- query. Запрос, позволяющий увидеть, какие хосты входят на данный момент в кластер.
- display. Выводит параметры конфигурации, текущее состояние и недавние сообщения журнала событий.
- suspend. Задерживает управление операциями кластера; прекращает выполнение операций хостов кластера. Задержанные хосты кластера будут игнорировать все команды управления кластером, кроме Resume (и Query).
- resume. Возобновляет управление операциями кластера; не перезапускает работу задержанного кластера, а только разрешает ему принимать другие команды управления.
- start. Запускает операции кластера.
- stop. Прекращает выполнение операций кластера.
- drainstop. Разъединяет все существующие соединения и прекращает выполнение операций кластера.
- enable <порт>/all. Активизирует трафик для правила <порта> или для всех портов.
- disable <порт>/all. Отключает трафик для правила <порта> или для всех портов.
- drain <порт>/all. Отключает новый трафик для правила <порта> или для всех портов.
- igmp <enable/disable> <IP-адрес кластера>. Активизирует или отключает поддержку IGMP Multicast для кластера.
Кластеры серверов
Еще одним компонентом в кластеризации Windows являются кластеры серверов. Цель применения кластеров серверов несколько отличается от Network Load Balancing. Кластеры серверов больше подходят для обеспечения высокого уровня готовности и управляемости вашего сетевого окружения Windows Server 2003, в то время как NLB больше подходит для обеспечения высокой надежности и производительности. Кластер серверов обеспечивает высокий уровень готовности для приложений, которые не имеет смысла или невозможно запускать более чем на одном сервере, например, для многих программ управления базами данных.
Кластеры серверов обеспечивают готовность системы за счет использования технологии переходов по отказу (failover) с одного узла на другой. Кластерное ПО автоматически перемещает процессы и ресурсы с отказавшего компьютера на остальные компьютеры кластера. Служба Cluster имеется в версиях Windows Server 2003 Enterprise Edition и Datacenter Edition (обе эти версии поддерживают кластеры из восьми узлов).
Архитектура кластеров серверов
Как и в случае NLB, кластер серверов - это группа компьютеров, которые совместно работают как единое целое. Версии Windows Server 2003 Enterprise Edition и Datacenter Edition поддерживают кластеры из восьми узлов. (Windows 2000 Advanced Server поддерживает в кластере серверов два компьютера, и Windows 2000 Datacenter Server поддерживает четыре компьютера.)
В кластере серверов каждый компьютер называется узлом,и каждый узел несет равную ответственность за поддержку готовности серверов и приложений. Кроме того, имеется общий набор ЗУ (запоминающих устройств), подсоединенный к каждому узлу с помощью разделяемой шины. Это позволяет перемещать эффективное владение ЗУ на другой узел в кластере, когда ответственность за обработку приложений, находящихся на этом ЗУ, передается с одного узла на другой. Это называется архитектурой "без разделяемых ресурсов",поскольку доступ к ресурсам, которые используются кластеризованными приложениями, одновременно выполняется не более чем из одного узла. Эта архитектура гарантирует, что узел отказывается от владения ресурсом, прежде чем этот ресурс будет захвачен и будет использоваться другим узлом кластера.
Кластеры серверов позволяют централизованно управлять системами. Поскольку кластеры серверов работают как единое целое, то ПО управления может работать так, как будто оно управляет одной системой. Это упрощает процесс доступа к кластерам серверов и управление ими, что позволяет вам работать более рационально и эффективно.
Переход по отказу (failover) и возврат после восстановления (failback)
Кластеры серверов поддерживают высокий уровень готовности за счет обеспечения постоянного доступа к приложениям и узлам. Если узел или приложение должны перейти в состояние offline (в результате запланированного или не запланированного простоя), то другой узел этого кластера серверов должен немедленно взять на себя все задачи. Этот процесс называют переходом по отказу (failover).
Переход по отказу.Переход по отказу - это одна из многих возможностей кластера серверов, которые отличают его от NLB-кластера. Переход по отказу возникает при отказе какого-либо приложения или узла. Например, когда какой-либо аппаратный ресурс в узле приводит к аварии системы, другой узел в кластере серверов немедленно берет на себя управление (и становится узлом восстановления).
Узел восстановления сначала берет на себя владение ресурсами отказавшего узла. Зависимые ресурсы переводятся в режим offline раньше, чем ресурсы, от которых они зависят. Служба Cluster делает это путем использования Resource Monitor (Монитора ресурсов) для соединения с DLL, которая управляет этим ресурсом (см. ниже раздел "Монитор ресурсов"). Если не удается установить контакт с ресурсом или отключить его нормальным образом, то он немедленно отключается. После отключения ресурсов узел восстановления начинает брать на себя управление этими ресурсами, получает IP-адрес отказавшего узла и, наконец, автоматически запускается, предоставляя клиентам услуги отказавшего узла путем возврата ресурсов и служб в режим online.
При отказе приложения выполняется аналогичный процесс, который все же несколько отличается от случая отказа узла. После обнаружения отказа приложения узел может сначала попытаться перезапустить это приложение. Если это не удается, то узел инициирует переход по отказу, чтобы это приложение было запущено другим узлом кластера серверов.
Следует помнить две вещи, относящиеся к переходу по отказу.
- Переход по отказу по-настоящему полезен только в том случае, когда узел, восстанавливающий приложение, может адекватно обслуживать дополнительную рабочую нагрузку. Поскольку незапланированные отказы трудно или невозможно предсказать, то вам следует оборудовать все узлы таким образом, чтобы они могли легко брать на себя рабочую нагрузку в случае отказов.
- Процесс перехода по отказу является полностью настраиваемым. Вы можете использовать Cluster Administrator (Администратор кластера), чтобы определять политики и процедуры для перехода по отказу. Например, вы можете определять зависимости приложения (должен ли отказ приложения вызывать перезапуск приложения в том же узле) и политики возврата после восстановления (failback).
Возврат после восстановления.После перехода по отказу узел (или узлы) восстановления берет на себя службы из отключившегося узла или приложения. Вы должны всегда рассматривать переход по отказу как временное решение, поскольку это обычно вызывает перегрузку ресурсов. В результате вам следует постараться как можно быстрее вернуть приложение или узел в состояние online.
Механизм восстановления исходной конфигурации называется возвратом после восстановления (failback). По сути это процесс перехода по отказу в обратном направлении. Он автоматически выравнивает нагрузку, когда снова становится доступным данное приложение или узел.
Режимы работы кластера серверов
Имеется два основных режима работы для кластеров Windows Server 2003 в вашей сетевой среде. Эти режимы не следует путать со сценариями кластеризации, которые могут быть реализованы в вашей среде. Это внутренние механизмы, обеспечивающие гибкость кластеров серверов в вашей среде. Два следующих режима работы поддерживаются кластерами Windows Server 2003.
- Кластеризация типа active/active. Это наиболее продуктивный и эффективный режим работы, который вы можете использовать. В этом режиме все узлы действуют под нагрузкой (они обслуживают клиентов), и они могут обеспечивать восстановление для любого отказавшего приложения или узла. Преимущества этого режима заключаются в более эффективном использовании ресурсов оборудования. Иначе говоря, ресурсы не простаивают, ожидая, когда приложение или узел выйдет из строя.
- Кластеризация типа active/passive. Используется для обеспечения максимального уровня готовности, стабильности и производительности. В этом режиме один узел активно предоставляет услуги, в то время как другой простаивает, ожидая выхода из строя активного приложения или узла. Хотя этот режим обеспечивает наиболее высокий уровень безопасности для вашего кластера Windows Server 2003, его недостатком является то, что простаивают полезные ресурсы.
Компоненты оборудования кластера серверов
Компоненты оборудования, необходимые для кластера серверов, являются еще одним фактором, отличающим кластеры серверов от NLB-кластеров. Иными словами, к кластерам серверов предъявляются более высокие требования по ресурсам (переход по отказу, возврат после восстановления и кластеризация типа active/active). В следующих разделах подробно описываются основные компоненты оборудования, необходимые для создания и поддержки кластера серверов.
Узлы.Как уже говорилось выше, кластер серверов состоит из двух и более отдельных компьютерных систем (узлов), которые действуют как единое целое. Клиентские компьютеры "видят" и используют кластеры серверов как один ресурс. Чтобы сервер мог стать узлом в кластере серверов, он должен отвечать следующим необходимым условиям.
- На сервере должна работать система Windows Server 2003 Enterprise Edition или Datacenter Edition.
- Сервер должен быть членом домена, но не рабочей группы.
- На сервере должна быть установлена и запущена служба Cluster.
- Сервер должен быть подсоединен к одному или нескольким разделяемым ЗУ. Более подробные сведения см. ниже в разделе "Разделяемые ЗУ".
Совет. Поместите все серверы, которые будут узлами кластера серверов, в их собственную организационную единицу (OU) Active Directory, чтобы изолировать их от групповых политик, которые могут действовать для других серверов.
При выполнении этих условий сервер может активно участвовать совместно с другими серверами в кластере серверов. Узлы, по определению, обладают следующими свойствами.
- Поскольку каждый узел кластера серверов подсоединен к одному или нескольким разделяемым ЗУ, каждый из них совместно использует данные, хранящиеся на этих устройствах.
- Каждый узел обнаруживает присутствие других узлов в кластере серверов посредством межсоединения. Межсоединение - это обычно высокоскоростное соединение, которое подключено к каждому узлу. Узлы не обязательно должны иметь отдельное межсоединение, отличное от их сетевого адаптера, который связывает их с остальной частью сетевого окружения Windows Server 2003. Однако очень рекомендуется иметь отдельное межсоединение.
Примечание. Узлы кластера серверов могут также обнаруживать присоединение к кластеру серверов других узлов или их выход из кластера серверов. Эта способность обнаружения используется для выявления отказов компьютеров и приложений.
Узел может иметь различные состояния его участия в кластере серверов. В табл. 15.1 приводит список из пяти возможных состояний узла. Узел может находиться одновременно только в одном из этих состояний.
| Состояние | Описание |
|---|---|
| Down (Отключен) | Узел не работает в кластере серверов из-за отказа компьютера или приложения либо запланированного обслуживания. |
| Joining (Присоединение) | Узел становится членом кластера серверов. |
| Paused (Приостановлен) | Разделяемые ресурсы захвачены, поэтому узел находится в состоянии ожидания, пока не будут освобождены ресурсы. |
| Up (Включен) | Узел находится в активном состоянии и работает в кластере серверов. |
| Unknown (Неизвестно) | Рабочее состояние узла невозможно определить. |
Разделяемые ЗУ.Все узлы, участвующие в работе кластера серверов, совместно используют одно или несколько запоминающих устройств (ЗУ), как это показано на схеме рис. 15.12. Эти ЗУ используют разделяемую шину SCSI для подключения к двум узлам кластера серверов.
Если вы хотите поддерживать более двух узлов (до восьми узлов), то должны установить устройство с волоконно-оптическим каналом. Windows Server 2003 Enterprise Edition и Datacenter Edition поддерживают широкий диапазон устройств SCSI от различных изготовителей, но я настоятельно рекомендую обратиться к списку совместимости оборудования (Hardware Compatibility List - HCL), прежде чем приступить к созданию кластера серверов. Microsoft официально поддерживает только сертифицированные для кластеров комбинации серверов и ЗУ. См. www.microsoft.com/hcl со списком поддерживаемых систем.
Совет. Вы сэкономите кучу времени, если проверите работу устройств SCSI, прежде чем приступить к созданию кластера серверов.
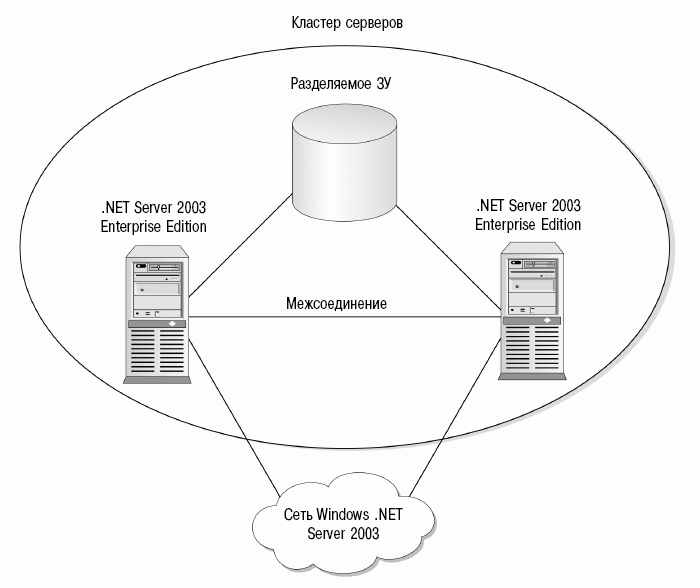
Рис. 15.12. Кластеры серверов с двумя узлами могут использовать разделяемую шину SCSI для совместного использования ЗУ
На самих ЗУ хранятся любые данные, которые требуются узлам для совместного использования, а также хранится вся информация о конфигурации и ресурсах кластера серверов. Только один узел может иметь временное владение данными, которые находятся на разделяемом(ых) ЗУ, что устраняет возможность конфликтов ресурсов.
Примечание. Для повышения отказоустойчивости вам следует использовать матрицы дисков RAID (Redundant Array of Independent Disks) 5. RAID 5 выполняет запись данных с чередованием между тремя и более дисками, организованными в виде массива, и поддерживает информацию по четности для повышения производительности и снижения риска потери данных из-за отказов дисковой подсистемы.
Межсоединения.Межсоединение - это физический носитель, используемый для обмена информацией в кластере серверов. Межсоединением может быть сетевой адаптер, используемый для связи с остальной частью сети (он принимает входящие клиентские запросы) или другой сетевой адаптер, который выделен для обслуживания обмена информацией в кластере серверов. Для повышения производительности и поддержки избыточности используйте выделенный сетевой адаптер для обмена информацией кластера и второй сетевой адаптер для связи с остальной частью сети.
Наличие двух сетевых адаптеров в каждом узле не является обязательным, но, несомненно, рекомендуемым требованием. Причина этого очевидна. Во-первых, на сетевой трафик, генерируемый между двумя узлами, не оказывает влияния остальной трафик сети. Но важнее всего то, что вы снижаете количество единственных точек отказа в кластере серверов. Ведь это и есть основная причина того, что вы хотите использовать кластеры серверов.
Clusnet.sys, сетевой драйвер кластера, запускается в каждом узле и управляет обменом данных кластера серверов.