|
Здравствуйие! Я хочу пройти курс Введение в принципы функционирования и применения современных мультиядерных архитектур (на примере Intel Xeon Phi), в презентации самостоятельной работы №1 указаны логин и пароль для доступ на кластер и выполнения самостоятельных работ, но войти по такой паре логин-пароль не получается. Как предполагается выполнение самосоятельных работ в этом курсе? |
Инспектор
Вы можете этот курс.
Опубликован: 30.05.2014 | Уровень: для всех | Доступ: платный | ВУЗ: Нижегородский государственный университет им. Н.И.Лобачевского
Лекция 3: Выполнение программ на Intel Xeon Phi. Модели организации вычислений с использованием Intel Xeon Phi
Модели использования сопроцессора Intel Xeon Phi
Архитектура Intel Xeon Phi поддерживает несколько режимов использования сопроцессора, которые можно комбинировать для достижения максимальной производительности в зависимости от характеристик решаемой задачи. Процесс может быть запущен как в операционной системе базовой системы, так и в ОС сопроцессора; в зависимости от режима использования могут использоваться вычислительные мощности только процессоров базовой системы, либо только сопроцессора, либо процессоров базовой системы и сопроцессора совместно.
Библиотека Intel MPI для ОС Linux соответствует версии 2.1 стандарта MPI (MPI-2.1) и базируется на реализациях MPICH2 и MVAPICH2. Intel планирует обеспечить полную функциональность библиотеки для использования на любых конфигурациях процессоров Intel Xeon и Intel Xeon Phi, чтобы обеспечить разработчикам единообразное окружение разработки и исполнения MPI-приложений. В настоящий момент не поддерживается ряд разделов спецификации: динамическое управление процессами, файловый ввод-вывод MPI, односторонние передачи пассивному получателю (получатель не вызывает функции MPI).
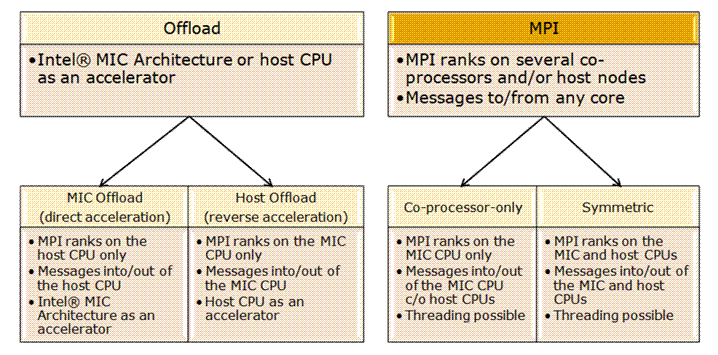
Поддерживается два режима выполнения приложений: режим Offload и режим MPI.
При работе в режиме Offload используется один из следующих подходов:
- Процессы MPI выполняются на процессорах Xeon базовой системы, для вычислений может использоваться запуск функций на сопроцессоре Xeon Phi. Данная модель поддерживается компиляторами C, C++, Fortran для архитектуры MIC, библиотекой Intel MKL, а также Intel MPI for Linux начиная с версии 4.0. Update 3.
- Процессы MPI выполняются на процессорах Xeon Phi с возможным запуском выполнения функций на процессорах Xeon базовой системы. Данная модель не поддерживается текущими версиями компиляторов и библиотек.
В режиме MPI базовая система и каждый сопроцессор Intel Xeon Phi рассматриваются как отдельные равноправные узлы, и процессы MPI могут выполняться на процессорах Xeon базовых систем и сопроцессорах Xeon Phi в произвольных сочетаниях. Поддерживаются следующие три основные модели:
- Модель симметричного выполнения (Symmetric model)
MPI-процессы выполняются как на процессорах базовой системы, так и на сопроцессорах. Эта модель выглядит естественной для использования на гетерогенных кластерах, но требуется обеспечить адекватной распределение нагрузки между процессами, выполняющимися на процессорах базовой системы и сопроцессорах. Вторая и третья модели являются частными случаями первой.
- Модель использования только сопроцессоров (Coprocessor-only model)
Все MPI-процессы выполняются на сопроцессорах.
- Модель использования только процессоров базовой системы (Host-only model)
Все MPI-процессы выполняются на процессорах базовой системы, сопроцессоры не используются.
Режим выполнения Offload
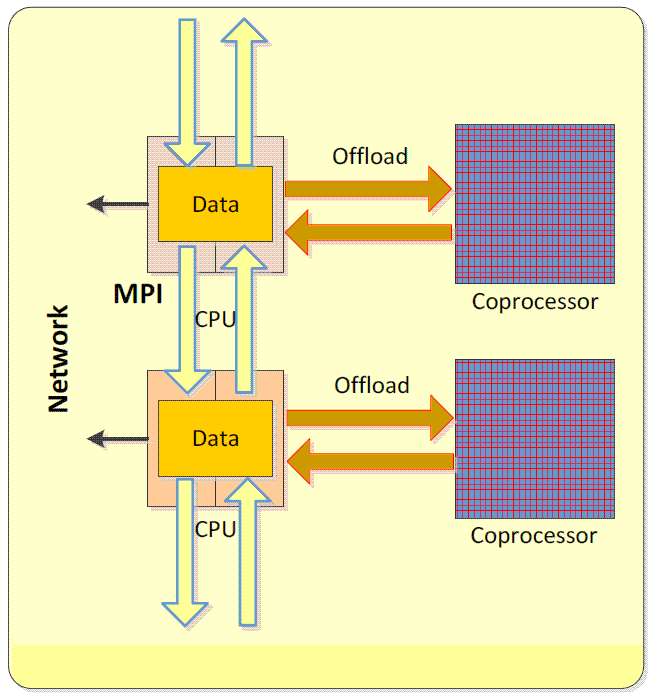
В режиме Offload все MPI-процессы выполняются на процессорах базовой системы, и MPI-взаимодействие не затрагивает сопроцессоры. Для использования вычислительных возможностей Xeon Phi используется выгрузка и выполнение функций на сопроцессоре, при этом вызов функций MPI в выгруженном коде не поддерживаться.
Необходимо отметить, что суммарный размер выгружаемых на сопроцессор кода и данных не должен превышать 85% объема памяти сопроцессора.
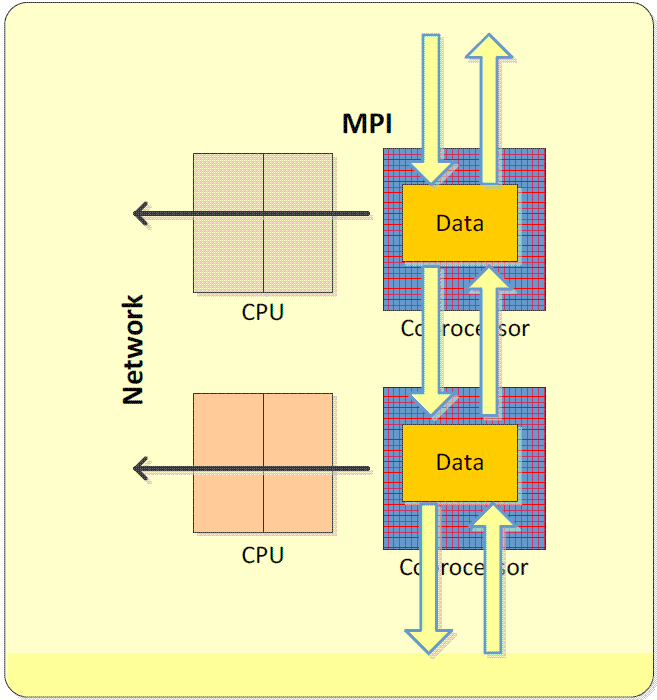
Модель использования только сопроцессоров (Coprocessor-only model)
Данная модель предполагает выполнение MPI-процессов только на сопроцессорах, и также называется "родной" (native) моделью для архитектуры Intel MIC.
Приложение, библиотека MPI и другие необходимые библиотеки загружаются на сопроцессор для выполнения, после чего запуск приложения может быть произведен как из базовой системы, так и из системы сопроцессора.
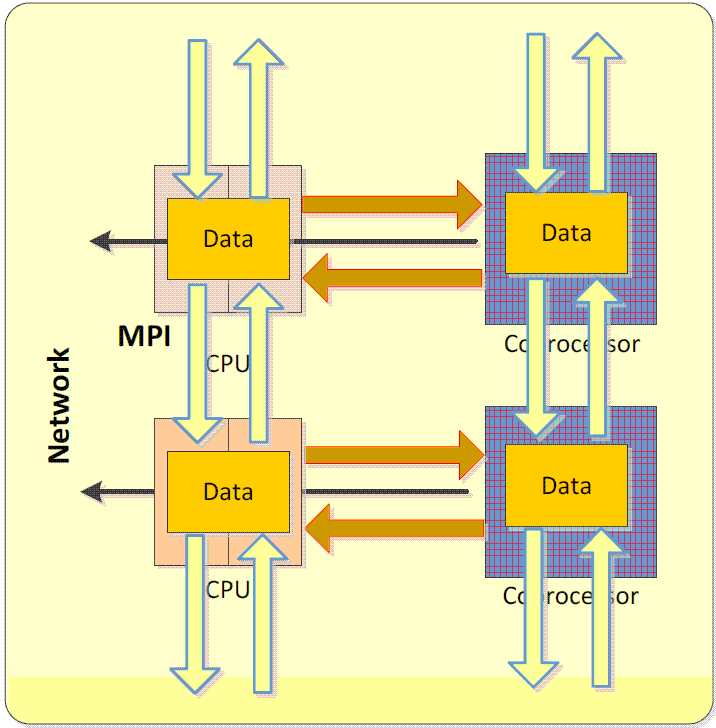
Модель симметричного выполнения (Symmetric model)
В данной модели MPI-процессы выполняются как на процессорах базовой системы, так и на сопроцессорах. Передача сообщений между процессорами базовой системы, в пределах сопроцессора и между сопроцессором и процессорами базовой системы может выполняться через механизмы разделяемой памяти или протокола tcp. По умолчанию используется tcp, для использования более производительного в данных случаях механизма разделяемой памяти необходимо для MPI-приложения установить значение переменной окружения: I_MPI_SSHM_SCIF={enable|yes|on|1}.
увеличить изображение
Рис. 3.7. MPI-процессы исполняются на процессорах базовой системы и на сопроцессорах Intel Xeon Phi
Приведем пример запуска параллельной программы, использующей модель симметричного выполнения. Посредством команды системы управления процессами Hydra выполняется запуск 4 процессов по 4 потока в каждом на основных процессорах и 2 процесса по 16 потоков в каждом на сопроцессоре mic0.
(host)$mpiexec.hydra –host $(hostname) -n 4 –env OMP_NUM_THREADS 4 ./test.exe.host -host mic0 –n 2 –env OMP_NUM_THREADS 16 –wdir /tmp /tmp/test.exe.mic
Svetlana Svetlana