

|
"Теоретически канал с адресацией EUI 64 может соединить порядка запись вида ее можно заменить например на записи вида 264 или 1,8 * 1019
|
Инспектор
Вы можете этот курс.
Опубликован: 30.07.2013 | Уровень: для всех | Доступ: платный
Лекция 9:
Управление групповым трафиком
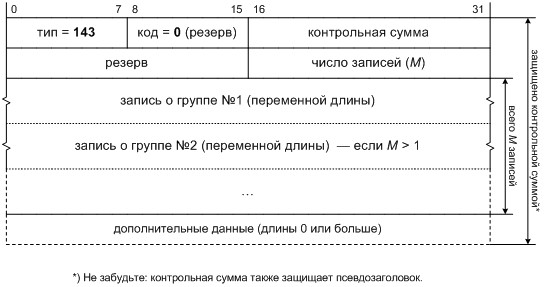
Первый пункт мы осуществим, усложнив формат отчета (см. рис. 8.4). Теперь он будет содержать переменное число записей о группах. Однако тогда нам придется пересмотреть адрес назначения отчета MLDv2. В MLDv1 это был адрес группы, о которой дается отчет, поскольку он был ровно один. Когда отчет дается о переменном числе групп, нам ничего не остается, как адресовать его фиксированной общепринятой группе "все маршрутизаторы с поддержкой MLDv2", FF02::16. Другие слушатели больше не получат этот отчет, а значит, механизм подавления избыточных отчетов работать не сможет. Его ценность уже упала благодаря понижению числа отчетов, так что в MLDv2 мы от него полностью откажемся. Пусть каждый слушатель MLDv2 говорит сам за себя, без оглядки на других. Это заодно упростит реализацию слушателя.
Еще один аргумент против подавления избыточных отчетов в MLDv2 связан с подслушиванием MLD, которое ведут интеллектуальные коммутаторы ЛВС [§A.2 RFC 3810]. В простейшем случае такой коммутатор продвигает групповые кадры только в те порты, откуда были замечены отчеты MLD о данной группе. Если же отчет подавлен, то коммутатор решит, что на этом порту слушателей нет, и продвигать групповые кадры туда не станет. Чтобы обойти эту проблему, коммутатор, в свою очередь, подавляет продвижение отчетов MLD в те порты, где, как ему кажется, нет групповых маршрутизаторов [§2.1.1 RFC 4541]. То же справедливо для IGMP. Не стоит сомневаться, что такой трюк только усложняет настройку сети и дестабилизирует ее работу.
Родственная проблема состоит в том, что коммутатор должен копировать весь групповой трафик в порты, где есть групповые маршрутизаторы, поскольку те ведут теневой прием всех групп, не вступая в них явным образом. В противном случае, например, маршрутизаторы не смогут получать отчеты MLDv1. Увы, коммутатор не может надежно обнаружить групповые маршрутизаторы по их запросам MLD, так как только генератор запросов ведет их постоянную передачу, а наблюдатели молча следят за чужими сообщениями MLD. Поэтому, чтобы коммутатор мог самостоятельно определить, на каких портах есть групповые маршрутизаторы, предложен отдельный простой протокол MRD (Multicast Router Discovery) [RFC 4286].
Объединение информации о многих группах в один отчет может привести к тому, что полная длина пакета с отчетом превысит MTU канала, а фрагментировать отчет было бы нежелательно. Чтобы обойти и эту трудность, один длинный отчет о множестве групп будет эквивалентен нескольким отчетам поменьше, каждый о подмножестве этого множества, вплоть до одного отчета на группу. Это позволит слушателю разбить длинный список групп на порции подходящего размера, не применяя никаких дополнительных механизмов, а просто управляя числом групп на отчет [§5.2.15 RFC 3810].
Перейдем ко второму пункту. Главная трудность здесь в том, что теперь каждый слушатель потенциально способен сделать сложный заказ: эти источники я принимаю, а те блокирую… Как говорится: "Здесь играть, здесь не играть, а здесь рыбу заворачивали". Задача маршрутизатора в том, чтобы по возможности удовлетворить все эти запросы сразу, расходуя минимум своих ресурсов.
Так как слушатель все равно фильтрует входящий групповой трафик, проникновение в канал пакетов от нежелательного источника не вызовет никаких проблем, кроме расхода ресурсов сети. Напротив, заблокировать желательный источник означало бы сделать невозможным какое-то нужное и запланированное сетевое взаимодействие. Поэтому маршрутизатор имеет право на погрешность, но только в сторону разрешения трафика. Чтобы гарантировать это, мы построим определенную модель фильтрации группового трафика по адресу источника и заставим обе стороны MLD следовать ей.
Для начала заметим, что для маршрутизатора нет принципиальной разницы между SSM и SFM. Это хост знает, что в режиме SSM разные источники S в комбинированном адресе (S,G) означают разные каналы вещания, которые могут принимать совершенно разные приложения, как мы обсудили в §2.9. Маршрутизатор же просто оптимизирует распространение группового трафика. Поэтому, когда хост принимает два канала,  , которые отличаются только адресом источника, но не адресом назначения, маршрутизатору достаточно допустить источники
, которые отличаются только адресом источника, но не адресом назначения, маршрутизатору достаточно допустить источники  к группе G, а остальные блокировать, чтобы не расходовать впустую ресурсы сети. То же самый подход применим и к SFM.
к группе G, а остальные блокировать, чтобы не расходовать впустую ресурсы сети. То же самый подход применим и к SFM.
Остаточные особенности фильтрации SSM обсуждаются в [RFC 4604].
В общем, картина такая: маршрутизатор допускает некое множество адресов источника S к данной группе G, а остальные адреса блокирует. Поэтому нашу модель фильтрации мы выразим на языке элементарной теории множеств, а оперировать она будет только адресами источника, так как у каждого группового адреса назначения будет свой независимый фильтр. Множество разрешенных адресов S мы станем называть первичным, потому что в нашей модели оно составляет истинный смысл фильтра, хотя способы фиксации (кодирования) этой информации могут быть разными.
Так, буквально через абзац мы обнаружим альтернативный способ кодирования фильтра при помощи множества блокируемых адресов.
Множество всех адресов IPv6 — это универсум данной задачи, то есть множество всех возможных значений. Оно конечно, и поэтому теоретически любой фильтр можно записать, просто перечислив адреса источника. Так, режим вещания ASM обеспечивает фильтр, содержащий все адреса IPv6, а полное прекращение приема группы равноценно фильтру, в котором нет ни одного адреса (пустое множество). А когда несколько слушателей выражают свои пожелания касательно фильтрации трафика в виде множеств, маршрутизатору достаточно найти их объединение, чтобы удовлетворить все запросы и не заблокировать ни один желательный источник: S=\bigcup_{i} S_i. На бумаге выглядит неплохо!
Как следствие, в MLDv2 можно вообще отказаться от сообщений типа "итог" и сигнализировать о выходе из группы на языке множеств. Мы сознательно не пытаемся исключить недопустимые адреса источника, такие как групповые адреса, из первичного фильтра, поскольку наша работа ведется в предположении, что входящий пакет с недопустимым адресом источника будет отбракован на самой ранней стадии его обработки. Это позволяет упростить наши теоретико-множественные выкладки и сделать их более прозрачными.
Но как нам быть со случаем, когда слушатель SFM на самом деле хочет заблокировать несколько источников, не препятствуя остальным? Этому отвечает первичное множество, равное дополнению множества блокируемых адресов .2 То есть разности множества всех адресов и множества блокируемых адресов. Нетрудно подсчитать, что при блокировании N адресов в первичном фильтре остается  элементов, и при небольшом N это
будет астрономическое число! Если множество всех адресов для режима ASM (N = 0) еще можно было бы кодировать кратко, как особый случай, режим SFM
с блокированием потребует явного перечисления этого фантастического количества адресов, потому что мы заранее не знаем, какие источники
предпочтет исключить слушатель. Очевидно, что ни передавать, ни хранить такое множество невозможно. Поэтому настало время нам перейти от
красивой теории к практическим хитростям и трюкам.
элементов, и при небольшом N это
будет астрономическое число! Если множество всех адресов для режима ASM (N = 0) еще можно было бы кодировать кратко, как особый случай, режим SFM
с блокированием потребует явного перечисления этого фантастического количества адресов, потому что мы заранее не знаем, какие источники
предпочтет исключить слушатель. Очевидно, что ни передавать, ни хранить такое множество невозможно. Поэтому настало время нам перейти от
красивой теории к практическим хитростям и трюкам.
Главный наш трюк мы позаимствуем из сценария с блокированием источников. Пока степень наполнения фильтра адресами близка к одной из двух
крайностей, все или ни одного, состояние фильтра можно записать довольно кратко. Когда наш первичный фильтр содержит всего несколько адресов,
мы перечисляем именно их. Когда же первичный фильтр включает в себя почти все возможные адреса, то достаточно перечислить множество недостающих
адресов  , потому что оно связано с первичным множеством фильтра однозначным образом:
, потому что оно связано с первичным множеством фильтра однозначным образом:  , где означает
дополнение множества S до универсума (множества всех адресов IPv6).
, где означает
дополнение множества S до универсума (множества всех адресов IPv6).
Переводя это в практическую плоскость, мы скажем, что фильтр группового маршрутизатора может работать в одном из двух режимов, включающем (INCLUDE) либо исключающем(EXCLUDE). Во включающем режиме фильтр допускает перечисленные источники, а в исключающем — блокирует их. Эти режимы взаимоисключающие, потому что каждый из них однозначно преобразует множество перечисленных адресов во множество допущенных адресов.
Сочетание этих режимов фильтрации имеет смысл, только когда элементами фильтра выступают диапазоны адресов разной величины, например, префиксы. Этот случай мы встречаем в настройках систем сетевой безопасности, таких как межсетевые экраны. Однако SFM оперирует только отдельными адресами.
Со своей стороны, слушатель тоже фильтрует трафик группы в одном из этих двух режимов, потому что его касаются те же самые практические соображения насчет размера фильтра. И тогда поддержка SFM в MLDv2 сводится к следующему: во-первых, передать информацию о фильтрах от слушателей к маршрутизатору, а во-вторых, свести вместе информацию от разных слушателей, чтобы объединенный фильтр маршрутизатора удовлетворил их всех.
В такой модели группового фильтра режим приема ASM (прием от любого источника) — это подмножество SFM и выражается фильтром EXCLUDE( ), где ( — пустое множество. Говоря по-русски, ASM — это прием от всех источников без исключения (подразумевая, что технически такое исключение возможно).
), где ( — пустое множество. Говоря по-русски, ASM — это прием от всех источников без исключения (подразумевая, что технически такое исключение возможно).
Чтобы передавать такого рода информацию, каждая запись в отчете MLDv2 (см. рис. 8.5) будет содержать, помимо адреса группы, список источников. В первом приближении, этот список и есть фильтр данной группы у слушателя, составившего отчет. Как мы только что установили, этот фильтр надо снабдить указанием, в каком режиме он должен работать, включающем или исключающем. Сделаем мы это про помощи поля "тип записи".
Чтобы провести начальную загрузку своего фильтра на маршрутизаторы, слушатель должен дословно перечислить адреса источника в фильтре и указать его режим работы. Для этой цели достаточно двух типов записи, CHANGE_TO_INCLUDE_MODE (тип 3) и CHANGE_TO_EXCLUDE_MODE (тип 4). Первый из них говорит, что слушатель перевел свой фильтр во включающий режим и загрузил в него приведенный список источников. Второй тип сообщает то же самое для фильтра в исключающем режиме. Чтобы нам было удобнее обсуждать теоретико-множественные свойства типов записей, мы станем их кратко записывать как TO_IN(S) и TO_EX(S) , соответственно, где S — множество источников, перечисленное в данной записи.
Сергей Субботин
 "
"
Павел Афиногенов
|
Курс IPv6, в тексте имеются ссылки на параграфы. Разбиения курса на параграфы нет. |
Анатолий Федоров
| Россия, Москва, Московский государственный университет им. М. В. Ломоносова, 1989 |