|
не хватает одного параметра: static void Main(string[] args) |
Инспектор
Вы можете этот курс.
Опубликован: 23.04.2013 | Уровень: для всех | Доступ: платный
Лекция 2:
Параллельные вычисления
Модель параллельного выполнения программы
Мы говорили об архитектуре вычислительных комплексов, способных обеспечить параллельное выполнение программ. Но архитектура комплекса - это лишь одно из требований, необходимых для реализации подлинного параллелизма. Другие два требования связаны с требованиями к операционной системе и к самой программе. Не всякую программу можно распараллелить независимо о того, на каком суперкомпьютерном комплексе она будет выполняться. В следующих главах мы подробнее поговорим о средствах операционной системы, обеспечивающих параллелизм вычислений, и о параллельных алгоритмах. Сейчас же рассмотрим некоторую модель параллельного выполнения, где главным действующим лицом будет программа.
Параллельные вычисления становятся одним из магистральных направлений развития информационных технологий. Можно указать на две причины, определяющие важность этого направления. Первая состоит в том, что стратегически важные для развития государства задачи могут быть решены только с применением суперкомпьютеров, обладающих сотнями тысяч процессоров, которые нужно заставить работать одновременно. Вторая причина связана с другим полюсом компьютерной техники, на котором находятся обычные компьютеры, ориентированные на массового пользователя. И эта техника становится многоядерной, и ее требуется эффективно использовать, так что параллельные вычисления требуются и здесь.
Для поддержки параллельных вычислений сделано достаточно много, начиная от архитектуры вычислительных систем, операционных систем, языков программирования до разработки специальных параллельных алгоритмов. Тем не менее, для программиста, решающего сложную задачу, построение и отладка эффективной параллельной программы все еще остается не простым занятием.
Рассмотрим одну из моделей параллельного вычисления. Для этой модели мы хотим получить оценки времени выполнения программы одним процессором - 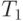 , конечным числом процессоров -
, конечным числом процессоров -  , и для идеализированного случая, когда число процессоров не ограничивается -
, и для идеализированного случая, когда число процессоров не ограничивается - 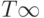 .
.
Рассмотрим программу P, состоящую из n модулей:
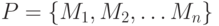
Будем предполагать, что программа P выполняется на компьютере, обладающим некоторым числом процессоров, работающих на общей памяти. Выходные данные, полученные в результате работы модуля 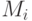 , могут являться входными данными для модуля
, могут являться входными данными для модуля 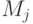 . Так естественным образом возникает зависимость между модулями, определяющая возможный порядок их выполнения.
. Так естественным образом возникает зависимость между модулями, определяющая возможный порядок их выполнения.
Множество модулей разобьём на k уровней. К уровню i отнесем те модули, для начала работы которых требуется завершение работы модулей верхних уровней, из которых хотя бы один принадлежит уровню i - 1. Модуль уровня i с номером k будем обозначать как 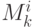 .
.
Модули, принадлежащие уровню 1, имеют все необходимые данные, полученные от внешних источников. Они не требуют завершения работы других модулей и в принципе могут выполняться параллельно, будучи запущенными в начальный момент выполнения программы.
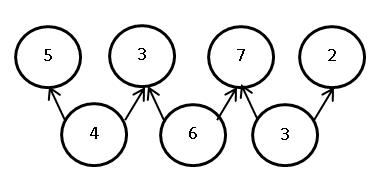
Свяжем с программой P ориентированный граф зависимостей модулей. Граф не содержит циклов и отражает разбиение модулей на уровни. Модули являются вершинами графа, а дуги отражают зависимости между модулями. Дуга ведет от модуля к модулю  , если для начала выполнения модуля требуется завершение работы модуля . В узлах графа содержится информация об ожидаемом времени выполнения модуля, где время измеряется в некоторых условных единицах. На Рис. 1.1 показан пример графа зависимостей:
, если для начала выполнения модуля требуется завершение работы модуля . В узлах графа содержится информация об ожидаемом времени выполнения модуля, где время измеряется в некоторых условных единицах. На Рис. 1.1 показан пример графа зависимостей:
Обозначим через - время, требуемое для выполнения программы P одним процессором, 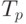 - p процессорами,
- p процессорами, 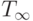 - время, требуемое в случае, когда число процессоров неограниченно. В последнем случае достаточно n процессоров, по числу модулей нашей программы.
- время, требуемое в случае, когда число процессоров неограниченно. В последнем случае достаточно n процессоров, по числу модулей нашей программы.
Предполагается, что все эти характеристики рассчитываются при соблюдении двух условий:
- Выполняются зависимости между модулями, заданные графом зависимостей.
- Характеристики вычислены для оптимального расписания работы процессоров.
В случае одного процессора достаточно выполнение только первого условия. Обычно предполагается естественный порядок выполнения модулей, - последовательное выполнение модулей одного уровня, затем переход к выполнению модулей следующего уровня.
Для случая неограниченного числа процессоров оптимальным является такое расписание, когда каждый модуль начинает выполняться, как только завершены все модули, необходимые для его работы.
Для случая p процессоров можно распределить модули по процессорам, задав для каждого процессора 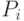 множество модулей, выполняемых этим процессором:
множество модулей, выполняемых этим процессором:
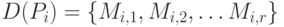
Распределение модулей по процессорам совместно с графом зависимостей однозначно определяет расписание работ и время выполнения программы при данном расписании. Предполагается, что каждый процессор выполняет модули из распределения  . После завершения очередного модуля он сразу же переходит к выполнению следующего модуля, если для этого модуля выполнены все зависимости, заданные графом зависимостей. В противном случае процессор ждет окончания работы требуемых модулей. Время завершения последнего модуля в распределении задает время работы данного процессора. Тот процессор, который последним заканчивает работу и определяет общее время решения задачи
. После завершения очередного модуля он сразу же переходит к выполнению следующего модуля, если для этого модуля выполнены все зависимости, заданные графом зависимостей. В противном случае процессор ждет окончания работы требуемых модулей. Время завершения последнего модуля в распределении задает время работы данного процессора. Тот процессор, который последним заканчивает работу и определяет общее время решения задачи 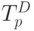 для данного расписания. Введенная ранее характеристика предполагает оптимальное расписание:
для данного расписания. Введенная ранее характеристика предполагает оптимальное расписание:

Задача составления оптимального расписания относится к сложным задачам. На практике для программ большого размера не удается явно вычислить значение . По этой причине несомненный интерес представляет получение оценок для .
Для введенных характеристик выполняется естественное соотношение:
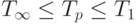 |
( 1.1) |
Нас будет интересовать получение более точных оценок для .
Рассмотрим вначале упрощенную ситуацию, предположив, что время выполнения всех модулей одинаково и равно t. Нетрудно видеть, что
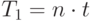 |
( 1.2) |
Действительно, один процессор должен выполнить все модули программы, проходя, например, последовательно один уровень за другим.
Нетрудно посчитать и время
 |
( 1.3) |
Действительно, пусть на первом уровне 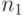 модулей. У них есть все необходимые данные, и они могут выполняться параллельно. Поскольку число процессоров неограниченно, то запустив каждый модуль на одном из имеющихся процессоров, за время t завершим выполнение модулей первого уровня. Пусть за время
модулей. У них есть все необходимые данные, и они могут выполняться параллельно. Поскольку число процессоров неограниченно, то запустив каждый модуль на одном из имеющихся процессоров, за время t завершим выполнение модулей первого уровня. Пусть за время 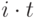 завершено выполнение всех модулей всех уровней от первого до i-го. Тогда возможно параллельно выполнять модули следующего i + 1-го уровня, число которых равно
завершено выполнение всех модулей всех уровней от первого до i-го. Тогда возможно параллельно выполнять модули следующего i + 1-го уровня, число которых равно 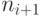 . Процессоров у нас хватает, поэтому на завершение всех модулей этого уровня потребуется t времени, и общее время выполнения равно
. Процессоров у нас хватает, поэтому на завершение всех модулей этого уровня потребуется t времени, и общее время выполнения равно  , что по индукции доказывает справедливость формулы (3).
, что по индукции доказывает справедливость формулы (3).
Для времени получим оценки сверху и снизу. Понятно, что p процессоров, начав одновременно работать, могут выполнить вычисление 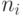 модулей уровня i за время
модулей уровня i за время  , где
, где  обозначает минимальное целое, большее или равное x. Два процессора смогут выполнить пять модулей уровня 1 за время
обозначает минимальное целое, большее или равное x. Два процессора смогут выполнить пять модулей уровня 1 за время 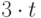 . Отсюда следует, что общее время работы дается формулой:
. Отсюда следует, что общее время работы дается формулой:
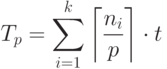 |
( 1.4) |
Поскольку  , то
, то
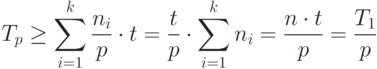 |
( 1.5) |
Формула (5) дает нижнюю оценку времени выполнения работы p процессорами.
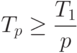 |
( 1.6) |
Если на каждом уровне число модулей кратно p, то оценка достижима. В лучшем случае p процессоров могут сократить время выполнения программы в p раз в сравнении со временем, требуемом для выполнения этой работы одним процессором.
Получим теперь оценку сверху. Поскольку  , то
, то
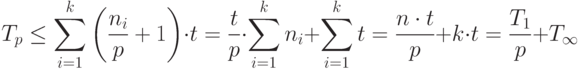 |
( 1.7) |
Объединяя (6) и (7), получим
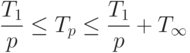 |
( 1.8) |
Оценки (8) для случая, когда время выполнения всех модулей одинаково, известны [5].
Рассмотрим теперь более интересный для практики случай, когда модули программы для своего выполнения требуют разного времени. Пусть 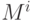 - множество модулей уровня i:
- множество модулей уровня i:
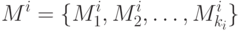 |
( 1.9) |
Для каждого из этих модулей известно время, требуемое на его выполнение - 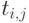 .
.
И в этом случае нетрудно рассчитать время - время, требуемое на выполнение всей работы одним процессором:
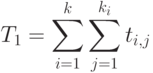 |
( 1.10) |
Как рассчитать время в этой ситуации, когда мы располагаем неограниченным числом процессоров? Введем для каждого модуля время окончания его работы - 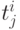 . Это время будем рассчитывать по следующей формуле:
. Это время будем рассчитывать по следующей формуле:
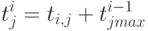 |
( 1.11) |
Здесь  - время окончания работы того модуля уровня i-1, который:
- время окончания работы того модуля уровня i-1, который:
- необходим для работы модуля
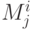 ;
;
- из всех необходимых модулей завершает свою работу последним.
Тогда время можно рассчитать следующим образом:
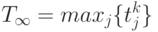 |
( 1.12) |
Формула (12) говорит, что время завершения последнего модуля уровня k и является временем при оптимальном расписании работ. Справедлива следующая теорема:
Алексей Рыжков
Никита Белов
|
Выставил оценки курса и заданий, начал писать замечания. После нажатия кнопки "Enter" окно отзыва пропало, открыть его снова не могу. Кнопка "Удалить комментарий" в разделе "Мнения" не работает. Как мне отредактировать недописанный отзыв? |