| Россия |
Инспектор
Вы можете этот курс.
Опубликован: 05.03.2013 | Уровень: для всех | Доступ: платный
Лекция 2:
Проблемы разработки параллельных приложений
Аннотация: Основными этапами разработки параллельных приложений являются: декомпозиция, выявление информационных зависимостей между подзадачами, масштабирование подзадач и балансировка нагрузки для каждого процессора.
Ключевые слова: разбиение, декомпозиция, приложение, форматирование, сохранение изменений, отправка, операции, поток, динамическая, алгоритм, произвольное, параметризация, пул, пространство, значение, переменная, вывод, операторы, список, индекс, доступ, быстродействие, открытие файла, поиск, память, значение переменной, блок памяти, байт, работ
Декомпозиция
Под декомпозицией понимается разбиение задачи на относительно независимые части (подзадачи). Декомпозиция задачи может быть проведена несколькими способами: по заданиям, по данным, по информационным потокам.
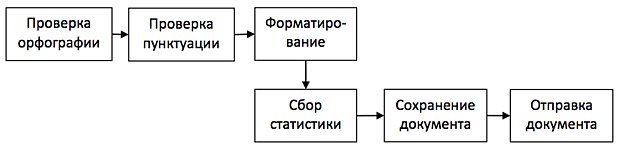
Декомпозиция по заданиям (функциональная декомпозиция) предполагает присвоение разным потокам разных функций. Например, приложение выполняющее правку документа включает следующие функции: проверка орфографии CheckSpelling, проверка пунктуации CheckPuncto, форматирование текста в соответствие с выбранными стилями Format, подсчет статистики по документу CalcStat, сохранение изменений в файле SaveChanges и отправка документа по электронной почте SendDoc.
Функциональная декомпозиция разбивает работу приложения на подзадачи таким образом, чтобы каждая подзадача была связана с отдельной функцией. Но не все операции могут выполняться параллельно. Например, сохранение документа и отправка документа выполняются только после завершения всех предыдущих этапов. Форматирование и сбор статистики могут выполняться параллельно, но только после завершения проверки орфографии и пунктуации.
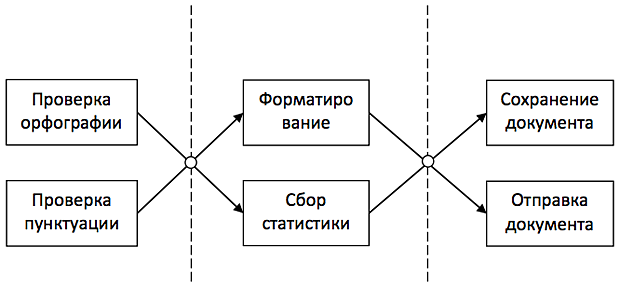
Декомпозиция по информационным потокам выделяет подзадачи, работающие с одним типом данных. В рассматриваемом примере могут быть выделены следующие подзадачи:
- Работа с черновым документом (орфография и пунктуация):
- Работа с исправленным документом (форматирование и сбор статистики);
- Работа с готовым документом (сохранение и отправка);
При декомпозиции по данным каждая подзадача работает со своим фрагментом данных, выполняя весь перечень действий. В рассматриваемом примере декомпозиция по данным может применяться к задачам, допускающим работу с фрагментом документа. Таким образом, функции CheckSpelling, CheckPuncto, CalcStat, Format объединяются в одну подзадачу, но создается несколько экземпляров этой подзадачи, которые параллельно работают с разными фрагментами документа. Функции SaveChanges и SendDoc составляют отдельные подзадачи, так как не могут работать с частью документа.
Декомпозиция по данным
При декомпозиции по данным каждая подзадача выполняет одни и те же действия, но с разными данными. Во многих задачах, параллельных по данным, существует несколько способов разделения данных. Например, задача матричного умножения допускает разделение по строчкам – каждый поток обрабатывает одну или несколько строчек матрицы, по столбцам – каждый поток обрабатывает один или несколько столбцов, а также по блокам заданного размера.
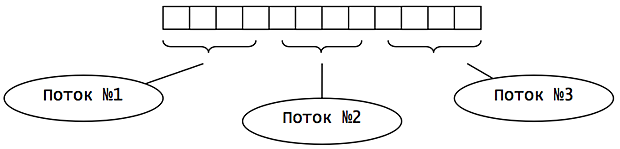
Два основных принципа разделения данных между подзадачами – статический и динамический. При статической декомпозиции фрагменты данных назначаются потокам до начала обработки и, как правило, содержат одинаковое число элементов для каждого потока. Например, разделение массива элементов может осуществляться по равным диапазонам индекса между потоками (range partition).
Основным достоинством статического разделения является независимость работы потоков (нет проблемы гонки данных) и, как следствие, нет необходимости в средствах синхронизации для доступа к элементам. Эффективность статической декомпозиции снижается при разной вычислительной сложности обработки элементов данных. Например, вычислительная нагрузка обработки i-элемента может зависеть от индекса элемента.
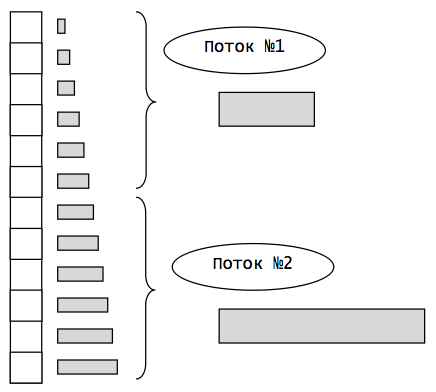
Разделение по диапазону приводит к несбалансированности нагрузки разных потоков. Несбалансированность нагрузки снижает эффективность распараллеливания. В некоторых случаях декомпозиция может быть улучшена и при статическом разбиении, когда заранее известно какие элементы обладают большей вычислительной трудоемкостью, а какие меньшей. Например, в случае зависимости вычислительной трудоемкости от индекса элемента, применение круговой декомпозиции выравнивает загруженность потоков. Первый поток обрабатывает все четные элементы, второй поток обрабатывает все нечетные.
В общем случае, когда вычислительная сложность обработки элементов заранее не известна, сбалансированность загрузки потоков обеспечивает динамическая декомпозиция.
/ При динамической декомпозиции каждый поток, участвующий в обработке, обращается за блоком данных (порцией). После обработки блока данных поток обращается за следующей порцией. Динамическая декомпозиция требует синхронизации доступа потоков к структуре данных. Размер блока определяет частоту обращений потоков к структуре. Некоторые алгоритмы динамической декомпозиции увеличивают размер блока в процессе обработки. Если поток быстро обрабатывает элементы, то размер блока для него увеличивается.
Масштабирование подзадач
Свойство масштабируемости заключается в эффективном использовании всех имеющихся вычислительных ресурсов. Параллельное приложение должно быть готово к тому, что завтра оно будет запускаться на системе с большими вычислительными возможностями. Свойство масштабируемости приложения тесно связано с выбранным алгоритмом решения задачи. Один алгоритм очень хорошо распараллеливается, но только на две подзадачи, другой алгоритм позволяет выделить произвольное число подзадач.
Обязательным условием масштабируемости приложения является возможность параметризации алгоритма в зависимости от числа процессоров в системе и в зависимости от текущей загруженности вычислительной системы. Такая параметризация позволяет изменять число выделяемых подзадач при конкретных условиях выполнения алгоритма. Современные платформы параллельного программирования предоставляют средства для автоматической балансировки нагрузки (пул потоков).
Проблема гонки данных
Потоки одного процесса разделяют единое адресное пространство, что упрощает взаимодействие подзадач (потоков), но требует обеспечения согласованности доступа к общим структурам данных.
Проблема гонки данных возникает при следующих условиях:
- Несколько потоков работают с разделяемым ресурсом.
- Конечный результат зависит от очередности выполнения командных последовательностей разных потоков.
Для иллюстрации проблемы гонки данных рассмотрим следующий фрагмент. Два потока выводят на экран значение общей переменной Msg.
// Код потока №1
(1) Msg = "I’m thread one";
(2) Console.WriteLine("Thread #1: " + Msg);
// Код потока №2
(3) Msg = "I’m thread two";
(4) Console.WriteLine("Thread #2: " + Msg);
Переменная Msg является общей – изменение переменной в одном потоке будут видны в другом потоке. При параллельной работе потоков вывод определяется конкретной последовательностью выполнения операторов.
Если операторы первого потока выполняются до операторов второго потока, т.е. при последовательности (1) – (2) – (3) – (4), то мы получаем:
Thread #1: I’m thread one Thread #2: I’m thread two
Если же в выполнение операторов одного потока вмешаются операторы другого потока, например, при последовательности (1) – (3) – (2) – (4), то получим следующее:
Thread #1: I’m thread two Thread #2: I’m thread two
Проблема гонки данных возникает не только при выполнении нескольких операторов, но и при выполнении одного оператора. Рассмотрим следующий случай. Оба потока выполняют один оператор над общей переменной x типа int:
x = x + 5
Данный оператор предполагает выполнение следующих действий:
загрузить значение операндов в регистры процессора осуществить суммирование записать результат по адресу переменной x
При выполнении командных последовательностей одного потока на одном исполнительном устройстве в работу может вмешаться другой поток. Конечный результат зависит от очередности выполнения командных последовательностей. Если потоки осуществляют суммирование последовательно, то получаем конечный результат: 10. Если потоки осуществляют суммирование одновременно, то раннее изменение будет затерто поздним:
| Действия | >Поток №1 | Поток №2 |
|---|---|---|
| Загрузка операндов | 0 | 0 |
| Вычисление | 5 | 5 |
| Запись результатов | 5 | |
| 5 | ||
| Значение переменной | 5 | 5 |
Еще одной "ловушкой" в многопоточной обработке является работа с динамическими структурами данных (списки, словари). Добавление и удаление элементов в динамические структуры данных осуществляется с помощью одного метода:
list.Add("New element");
dic.RemoveKey("keyOne");
Реализация методов включает несколько действий. Например, при добавлении элемента в список необходимо записать элемент по текущему индексу (указателю) и сдвинуть индекс на следующую позицию. Для корректного осуществления добавления элемента одним потоком необходимо, чтобы другие потоки дождались завершения манипуляций со списком.
// Добавление элемента в массив по текущему индексу data[current_index] = new_value; current_index++;
Для решения проблемы гонки данных необходимо обеспечить взаимно исключительный доступ к тем командным последовательностям, в которых осуществляется работа с разделяемым ресурсом. Взаимная исключительность означает, что в каждый момент времени с ресурсом работает только один поток, другие потоки блокируются в ожидании завершения работы первого потока. Фрагмент кода, к которому должен быть обеспечен взаимно исключительный доступ, называется критической секцией.
Проблема гонки данных не всегда возникает при работе с общей переменной. Например, в следующем фрагменте два потока перед завершением осуществляют изменение разделяемой переменной, а третий поток читает это значение.
// Общая переменная
bool b = false;
//Поток №1
void f1()
{
DoSomeWork1();
b = true;
}
//Поток №2
void f2()
{
DoSomeWork2();
b = true;
}
//Поток №3
void f3()
{
while(!b) ;
DoSomeWork3();
}
В этом примере третий поток в цикле "ожидает" завершения хотя бы одного потока. Проблемы гонки данных не возникает, несмотря на работу трех потоков с общей переменной. Порядок выполнения потоков не влияет на конечный результат. Изменения, вносимые потоками, не противоречат друг другу.