Инспектор

Вы можете этот курс.
Опубликован: 02.08.2007 | Уровень: специалист | Доступ: платный
Лекция 1:
Информационные системы с базами данных
Модели вычислений
Взгляд на использование компьютеров меняется в процессе их применения в различных сферах человеческого труда: большие вычислительные центры с мощными компьютерами, средние по мощности ЭВМ для автоматизации технологических процессов, персональные компьютеры, компьютеры, объединенные сетью коммуникаций. Неизменным остается требование пользователей к вычислительным ресурсам для удовлетворения потребностей в информации - время процессора (быстродействие), оперативная память, дисковое пространство и т.п. Проблема совместного использования ресурсов является одной из ключевых проблем решения любых прикладных задач на ЭВМ, в том числе и создания ИС. Решение этой проблемы приводит к разработке новых компьютерных технологий, которые являются сложным синтезом изменений в аппаратном и программном обеспечении. Основой таких модификаций как аппаратного, так и программного обеспечения являются модели вычислений.
Что принято понимать под моделью вычислений? Обычно под моделью вычислений подразумевают совокупность аппаратно-программных средств, схему их взаимодействия между собой и пользователями, т.е. постулируется ответ на вопросы, каким образом и какие вычислительные ресурсы используются в процессе выполнения вычислений. Поскольку понятие модели вычислений связано как и с аппаратным, так и с программным обеспечением, то нередко в качестве синонима слова модель используется слово архитектура. За всю историю развития вычислительной техники было предложено не так уж много моделей вычислений.
Централизованные вычисления:
- модель вычислений с использованием централизованной хост-ЭВМ;
- модель с автономными персональными вычислениями;
Распределенные вычисления:
- модель вычислений "файл-сервер" ;
- модель вычислений "клиент-сервер" ;
- модель "вычисление по требованию".
Исторически одной из первых моделей вычислений является модель с использованием централизованной хост-ЭВМ. В такой схеме вычислений пользователь получает доступ к вычислительным ресурсам ЭВМ через сеть неинтеллектуальных терминалов (т.е. терминалов, не обладающих никакими вычислительными возможностями). Центральный компьютер полностью отвечает за взаимодействие с пользователем и управление данными в многопользовательской среде.
Преимуществом такой модели вычислений является их централизация. Централизованные системы позволяют совместно использовать вычислительные ресурсы (диски, принтеры, оперативную память) с высокой эффективностью, а также обеспечивать высокую надежность и актуальность хранимых данных.
Самым большим недостатком такой схемы вычислений является линейная зависимость вычислительной мощности центральной ЭВМ от числа пользователей и, как следствие, высокая стоимость аппаратуры и программного обеспечения. Несмотря на устойчивую тенденцию снижения стоимости оборудования, такие системы по-прежнему остаются одними из дорогостоящих (отношение "цена/производительность" остается достаточно высокой).
В 80-е годы прошлого века появились персональные компьютеры и рабочие станции. Независимые друг от друга, предоставляющие вычислительные возможности, которые сопоставимы с большими ЭВМ, доступные по цене широкому кругу потребителей (отношение "цена/производительность" в данном случае гораздо ниже, чем при использовании больших ЭВМ). Персональные компьютеры положили конец централизованному подходу в обработке данных и обозначили переход к распределенным вычислениям.
Преимуществом такой модели вычислений является их автономность в использовании вычислительных ресурсов, т.е. централизованное использование компьютера, но на рабочем месте и независимо от других таких же компьютеров. В данном случае можно подобрать персональный компьютер адекватно решаемому кругу задач.
Однако у независимых персональных вычислений есть и свои проблемы. Эти проблемы порождают распределенность данных (невозможность совместной работы с данными различных пользователей) по персональным компьютерам в случае, когда эти данные должны использоваться совместно в рамках одной организации. При этом выигрыш в отношении "цена/производительность" компенсируется потерями в производительности труда коллективов, работающих с распределенными таким образом данными.
Проблемы совместного использования данных, расположенных на персональных компьютерах, привели к разработке концепции локальной вычислительной сети, которая восстанавливает преимущества коллективных вычислений и сохраняет простоту использования персональных компьютеров. Наличие вычислительной сети компьютеров характерно для всех моделей распределенных вычислений.
Модель вычислений "файл-сервер" (или архитектура "файл-сервер") основывается на понятии сервера. Термин сервер имеет двойственный смысл. С одной стороны, сервер есть узел вычислительной сети (компьютер с сети), предназначенный для предоставления совместно используемых ресурсов и услуг, а с другой - программный компонент, предоставляющий общий функциональный сервис другим программным компонентам вычислительной сети.
Файловый сервер является обычно центральным узлом сети, на котором хранятся файлы коллективного пользования и который является также концентратором совместно используемых периферийных устройств (например, принтера или дискового накопителя большой емкости). Файловый сервер не принимает участия в обработке приложения. Он выполняет сетевой транспорт совместно используемых данных (часто пересылая файл целиком конечному пользователю).
Преимуществом такой модели является, несомненно, корпоративное использование территориально распределенных вычислительных ресурсов, имеющее одним из своих следствий создание глобальных вычислительных систем и новых технологий обмена информацией.
Однако у такой модели есть два крупных недостатка при разработке многопользовательских приложений. Интенсивный обмен данными (рост трафика сети) приводит к быстрому достижению ее пропускной способности и тем самым к снижению (из-за увеличения времени реакции приложения за счет времени ожидания) производительности многопользовательской системы.
Другая проблема - это обеспечение согласованности данных, т.е. одновременного разделения доступа к одним и тем же данным группой пользователей. Обычно файл блокируется для других пользователей, когда его начинает обрабатывать приложение. В случае, когда часть файла реплицируется на конечный узел для обработки, снижается актуализация данных, что может быть неприемлемо для систем оперативной обработки информации.
Модель вычислений "клиент-сервер" явилась следующим шагом в развитии распределенных вычислений, объединив в себе преимущества коллективных вычислений в сети компьютеров с доступом к совместно используемым данным и высокие характеристики производительности вычислений с центральной ЭВМ. Основными понятиями данной модели являются сервер баз данных, клиентское приложение и сеть.
Основное назначение сервера баз данных - оптимальное управление разделяемыми ресурсами на уровне данных для множества клиентов. На этом уровне достаточно эффективно решаются задачи обеспечения согласованности данных, их актуальности, защиты и целостности.
Клиентское приложение является частью системы, которая обеспечивает интерфейс приложения с серверов баз данных. Логика приложения может быть полностью реализована на клиентской части системы, а обработку данных забирает на себя сервер баз данных.
Сеть и коммуникационное программное обеспечение являются средствами передачи данных. Реализация этой компоненты модели обеспечивает прозрачность сервера баз данных по отношению к клиенту.
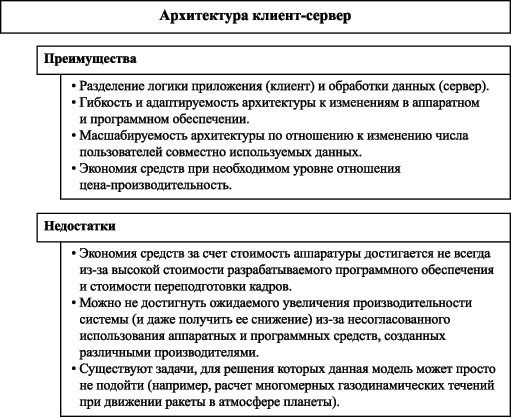
Несмотря на то, что модель вычислений "клиент-сервер" является высокопроизводительной распределенной моделью вычислений, она, помимо очевидных преимуществ, имеет присущие ей недостатки (рис. 1.10). Кроме того, другие модели вычислений также продолжают развиваться, обеспечивая приемлемые значения отношения "цена-производительность".
Модель "вычисления по требованию" или GRID является в настоящее время одной из перспективных распределенных моделей вычислений. Суть ее состоит в использовании вычислительных ресурсов, расположенных в локальной или глобальной вычислительной сети, аналогично тому, как мы в быту используем электричество, совершенно не отдавая себе отчета в том, с какой электростанции оно поступает к нам в дом.
В этой модели вычислений заявленные в сети GRID вычислительные ресурсы (компьютеры или кластеры ЭВМ) предоставляют свои свободные вычислительные ресурсы согласно правилам обслуживания заданий в очереди. Таким образом, находясь в России, вы можете запустить свою задачу на компьютере в Австралии, совершенно об этом не зная.
В этой лекции мы рассмотрели ряд основных понятий и терминов, которые потребуются проектировщику реляционных баз данных в процессе решения им своих профессиональных задач. В последующих лекциях мы последовательно и детально рассмотрим основные профессиональные задачи проектировщика реляционных баз данных.
Литература: [1], [2], [10], [12], [21], [29], [34], [36], [40], [41], [47].