
|
Прошу вас уточнить по курсу ITIL. IT Service Management по стандартам V.3.1 вопрос о количестве версий ITIL. |
Инспектор
Вы можете этот курс.
Опубликован: 17.05.2012 | Уровень: для всех | Доступ: платный
Лекция 12:
Управление событиями и инцидентами в рамках Эксплуатации услуг
12.2. Управление инцидентами
Управление инцидентами (Incident Management) - процесс, отвечающий за управление жизненным циклом всех инцидентов. Основная цель Управления инцидентами - скорейшее восстановление услуги для пользователей.
Инцидент (Incident) - незапланированное прерывание услуги или снижение качества услуги. Сбой конфигурационной единицы, который еще не повлиял на услугу, также является инцидентом. Например, сбой одного диска из массива зеркалирования[1].
Как видно из определения процесса, Управление инцидентами предназначено для максимально быстрого восстановления нормальной эксплуатации услуги и минимизации неблагоприятного влияния на бизнес в случае возникновения инцидента. Под "нормальной эксплуатацией услуги" здесь понимается эксплуатация в соответствии с SLA. Процесс рассматривает все события, которые нарушают или могут нарушить нормальную эксплуатацию услуги. Информация о таких событиях может поступать из разных источников, основными из которых являются звонки пользователей и технического персонала в сервис-деск и процесс Управления событиями.
Ценность Управления инцидентами для бизнеса более очевидна, чем у других процессов этапа Внедрения. Часто именно этот процесс является основой для формирования обоснования бизнесу о необходимости остальных процессов этапа Внедрения. В частности, Управление инцидентами помогает бизнесу тем, что:
- быстро находит и разрешает инциденты, в результате чего снижается время простоя услуг, что в целом увеличивает показатели доступности услуг;
- выравнивает деятельности IT в соответствии с приоритетами бизнеса;
- увеличивает способность выявления возможностей для улучшения услуг в результате расследования инцидентов;
- сервис-деск, разрешая инциденты, определяет дополнительные требования IT и бизнеса к услугам и обучению.
Время разрешения инцидента обычно формализовано в рамках SLA, OLA и других базовых соглашений. Команды поддержки должны быть готовы к соблюдению временных ограничений.
ITIL вводит также понятие Модель инцидентов, которая включает в себя:
- шаги, которые необходимо предпринять для того, чтобы разрешить инцидент;
- хронологический порядок шагов;
- распределение ответственностей - кто и что делает;
- временные рамки и пороговые величины для завершения каждого действия;
- вопросы того, с кем необходимо связать и на каком этапе;
Таким образом, Модель инцидентов описывает последовательность действий при возникновении определенного типа инцидентов. Использование моделей инцидентов позволяет стандартизовать процесс Управления инцидентами и ускорить его. Этот подход применим в отношении часто возникающих "стандартных" инцидентов. "Нестандартные" случаи обрабатываются отдельно, например, инциденты, связанные с информационной безопасностью. В отдельную категорию выделяются "значительные инциденты", которые должны разрешаться максимально быстро. Значительный инцидент (Major Incident) наивысшая категория влияния для инцидента. Значительный инцидент означает значительные потери для бизнеса[1]. То, какие инциденты будут считаться значительными, каждая организация решает индивидуально.
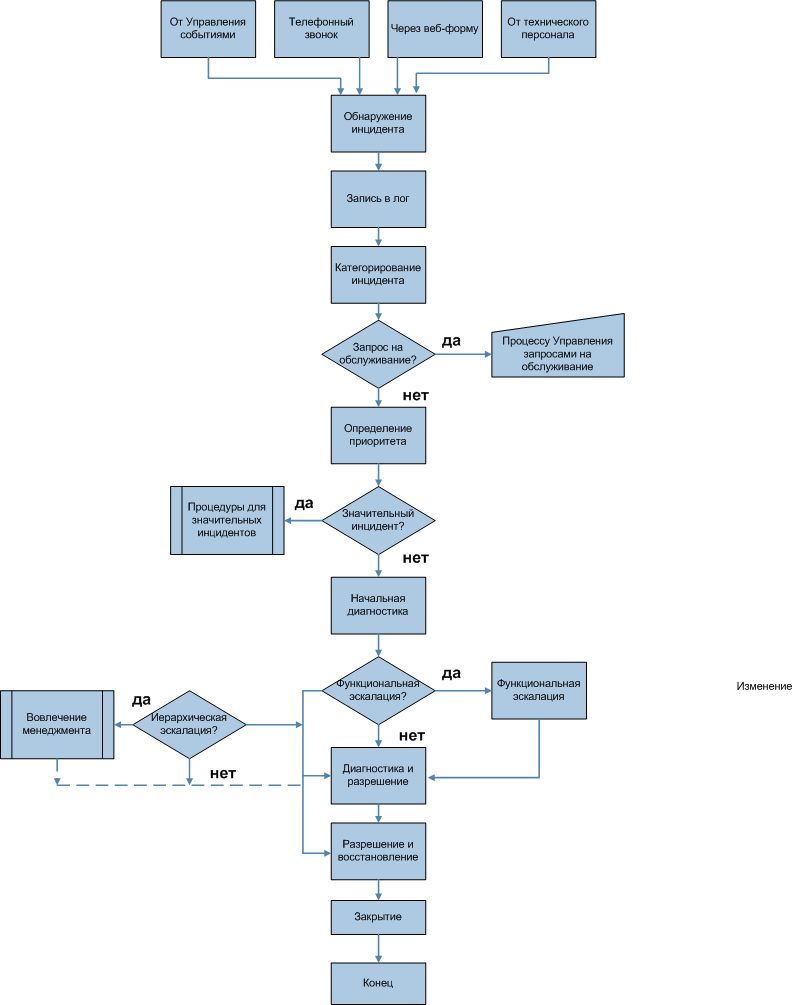
На рис. 12.2 схематически отображены основные деятельности в рамках Управления инцидентами.
Рассмотрим основные этапы, изображенные на рис. 12.2.
Для того чтобы разрешить инцидент, его необходимо сначала обнаружить, то есть идентифицировать. С точки зрения непрерывности бизнеса неприемлемо ждать обращений пользователей или технического персонала в сервис-деск. Все ключевые компоненты должны контролироваться, чтобы своевременно обнаруживать сбои или возможности их возникновения.
После того, как инцидент обнаружен, информацию о нем необходимо занести в лог. В логе должно быть отображено время обнаружения инцидента, вне зависимости от того, как он был обнаружен - по звонку в сервис-деск или в результате работы автоматических агентов. В логе также необходимо записать всю связанную с инцидентом информацию. Запись об инциденте должна послужить базой для его разрешения соответствующей командой поддержки.
Запись об инциденте должна включать:
- уникальный идентификатор инцидента;
- категорию инцидента;
- срочность инцидента. Срочность (Urgency) - мера того, насколько быстро с момента своего появления инцидент, проблема или изменение приобретет существенное влияние на бизнес. Например, инцидент с высоким уровнем влияния может иметь низкую срочность до тех пор, пока это влияние не затрагивает бизнес в период закрытия финансового года. Влияние и срочность используются для назначения приоритета[1].
- влияние инцидента;
- приоритет инцидента;
- дата и время записи;
- Имя/ID человека или группы, сделавшей запись об инциденте;
- метод уведомления;
- имя/отдел/номер/расположение пользователя;
- метод обратной связи;
- описание симптомов;
- статус инцидента;
- связанные конфигурационные единицы;
- группа поддержки/сотрудник, к кому переадресован инцидент;
- связанная с инцидентом проблема/известная ошибка;
- деятельности, осуществленные для разрешения инцидента;
- время и дата разрешения инцидента;
- категория закрытия;
- время и дата закрытия[17].
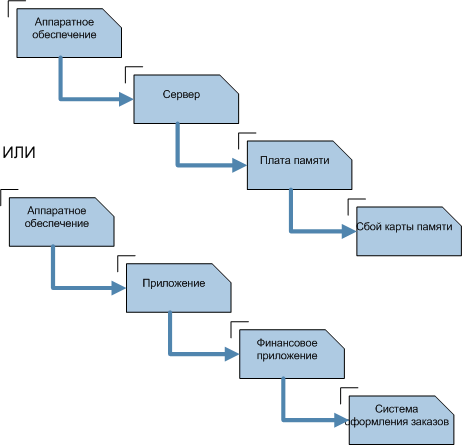
Следующий этап разрешения инцидента - категорирование. Оно необходимо для дальнейших работ, в частности, поиска известных ошибок и проблем, которые могли послужить причиной для возникновения инцидента. Обычно используется три-четыре уровня категорирования (рис. 12.3).
Нет стандартных методов для категорирования инцидентов, каждая организация сама определяет, какие категории будет использовать.
Приоритет инцидента определяется исходя из двух понятий - срочности и влияния. Влияние в отношении инцидентов чаще всего определяется на основе количества пользователей, которые он затронул. Тем не менее, этот показатель не всегда является объективным. В некоторых случаях влияние инцидента даже на одного единственного пользователя может оказать значительное негативное влияние на бизнес в целом.
Другие факторы, которые можно использовать для оценки влияния:
- риск для жизни или сегмента;
- количество услуг, которые затрагивает инцидент;
- уровень финансовых потерь;
- влияние на бизнес-репутацию;
- возникновение нарушений законодательства и требований регуляторов.
В таблицах 12.1 и 12.2 приведен пример матриц для определения приоритета инцидента и времени, в течение которого его необходимо разрешить.
| Приоритет | Характеристика | Время разрешения |
|---|---|---|
| 1 | Критичный | 1 час |
| 2 | Высокий | 8 часов |
| 3 | Средний | 24 часа |
| 4 | Низкий | 48 часов |
| 5 | Планируемый | Запланировать |
Для персонала поддержки необходимо разработать четкие инструкции определения приоритета инцидента на основе срочности и влияния на бизнес. Необходимо отметить, что приоритет инцидента может меняться в зависимости от изменения окружающих условий и требований бизнеса.
Далее следует этап начальной диагностики. В первую очередь он относится к инцидентам, поступившим в сервис-деск. Специалист службы сервис-деск должен попытаться найти причину, вызвавшую инцидент, понять, что именно работает некорректно и выявить максимальное количество характеристик инцидента во время связи с пользователем, например, по телефону. Другими словами, специалист должен попытаться решить инцидент и закрыть его. Если это невозможно, он сообщает пользователю идентификационный номер инцидента.
Если сервис-деск не может разрешить инцидент или сроки первой ступени разрешения инцидентов истекли, инцидент должен быть немедленно передан дальше.
Эскалация (Escalation) - деятельность, направленная на получение дополнительных ресурсов, когда это необходимо для достижения Целевых показателей уровня услуги или ожиданий заказчиков. Эскалация может потребоваться в рамках любого процесса Управления услугами, но наиболее часто ассоциируется с Управлением инцидентами, Управлением проблемами и управлением жалобами заказчика. Существует два типа эскалации: функциональная эскалация и Иерархическая эскалация[1].
- функциональная эскалация. Функциональная эскалация подразумевает передачу инцидента в группу поддержки с более высокой квалификацией и компетенцией. При этом если очевидно, что второй уровень поддержки не сможет разрешить инцидент, его можно сразу передать на третий уровень поддержки. Третий уровень поддержки может включать в себя не только сотрудников организации, но и поставщиков, вендоров и т.п. При этом ответственность за уведомление пользователя о ходе разрешения инцидента остается на сервис-деске, вне зависимости от того, где инцидент рассматривается на данный момент.
- иерархическая эскалация. Иерархическая эскалация подразумевает вовлечение или просто информирование руководителей более высокого уровня о возникновении инцидента. Она способствует своевременному принятию решений относительно выделения дополнительных ресурсов и вовлечения внешних организаций в процесс разрешения инцидента.
Следующий этап разрешения инцидентов называется исследование и диагностика. В случаях, когда пользователи обращаются только для поиска информации, сервис-деск должен предоставить ее в минимальные сроки. Но если сообщается о наличии сбоя, это требует определенных действий по исследованию и диагностике инцидента. При этом все предпринятые действия должны быть отображены в записи об инциденте. Действия чаще всего включают в себя:
- установление того, что именно не работает или что именно ищет пользователь;
- определение хронологии событий;
- оценка влияния инцидента, в том числе количества пользователей, которых он затронул;
- поиск в базе знаний аналогичных случаев в прошлом.
Когда потенциальное разрешение инцидента определено, необходимо провести тестирование того, что действия по восстановлению завершены, и услуга полностью восстановлена для пользователей. Группа, разрешившая инцидент, должна передать его на закрытие сервис-деску.
Сервис-деск, в свою очередь проверяет, что все действия, необходимые для разрешения инцидента, выполнены, пользователи удовлетворены и согласны закрыть инцидент. Это включает в себя следующее:
- закрытие категорирования - производится проверка корректности изначально установленной категории инцидента. Если она оказалось неправильной, ее исправление и занесение изменений в запись об инциденте;
- опрос удовлетворенности пользователей - - осуществляется по звонку или электронной почте для статистики и отображения эффективности работы сервис-деска;
- проверка полноты записи об инциденте;
- определение того, какая проблема вызвала инцидент, является она постоянной или периодически повторяющейся. Сюда относится также определение проактивных действий по предотвращению инцидентов этого типа в дальнейшем и формирование записи о проблеме, если она новая;
- формальное закрытие инцидента - формальное закрытие записи об инциденте.
В некоторых случаях инцидент может быть повторно открыт даже после формального закрытия. Правильным будет заранее определить правила о том, как, когда и при каких условиях инцидент может быть повторно открыт. Это используется, в частности, когда в один и тот же день возникают одинаковые инциденты. Для нового инцидента, тем не менее, необходимо сформировать новую запись со ссылкой на предыдущий инцидент. Запись о предыдущем инциденте может быть использована для разрешения нового.
Метриками эффективности процесса Управления инцидентами могут быть:
- общее количество инцидентов;
- количество инцидентов, находящихся на разных стадиях - закрыт, в работе, передан и т.п.
- размер текущего лога об инцидентах;
- количество значительных инцидентов;
- среднее время разрешения инцидентов;
- процент инцидентов, разрешенных в согласованное время разрешения инцидентов;
- средние затраты на инцидент;
- количество повторно открытых инцидентов и их процентное соотношение к общему количеству инцидентов;
- количество инцидентов, неправильно назначенных в команды поддержки;
- количество инцидентов, для которых были неправильно определены категории;
- количество удаленно разрешенных инцидентов ( без персонального присутствия);
- количество инцидентов, разрешенных с использованием каждой Модели инцидентов;
- количество инцидентов в разрезе определенных интервалов дня.
Для эффективного Управления инцидентами необходимо обеспечить следующее:
- способность обнаруживать инциденты как можно раньше. Это включает в себя обучение пользователей немедленно сообщать об инцидентах и конфигурирование инструментов Управления событиями;
- убедить персонал в том, что все инциденты должны быть занесены в журнал;
- доступность информации об известных проблемах и ошибках. Это позволит персоналу использовать опыт предыдущих инцидентов;
- взаимодействие с CMS для определения взаимосвязей конфигурационных единиц и обращения к их истории для поддержки первого уровня;
- взаимодействие с SLM для корректной оценки инцидентов, расстановки приоритетов и выполнения процедур Эскалации. SLM в свою очередь может использовать информацию от Управления инцидентами для определения того, что целевые уровни производительности реалистичны и могут быть достигнуты[17].
Основные риски для процесса Управления инцидентами:
- большое количество инцидентов, которые не могут быть разрешены в установленные сроки в связи с недостатком ресурсов или их недостаточной подготовкой;
- приостановка разрешения инцидентов из-за некорректной работы поддерживающих инструментов;
- недостаточность или несвоевременность информации из-за некорректной работы поддерживающих инструментов или плохой взаимосвязи с другими процессами;
- несоответствия с основными контрактами и соглашениями, которые возникают вследствие их плохой проработки и нереалистичности согласованных целевых показателей.
Александр Колотов