





| Россия, Нижний Новгород |
Инспектор
Вы можете этот курс.
Опубликован: 28.10.2009 | Уровень: специалист | Доступ: платный
Лекция 2:
Microsoft High Performance Computing Server 2008
Аннотация: В лекции даются краткий обзор систем управления кластерами, общая характеристика Microsoft Compute Cluster Server. Рассказывается об установке, настройке и управлении MS CCS.
Ключевые слова: суперскалярность, кластерная система, мэйнфрейм, система пакетной обработки, platform-specific, удобство использования, Linux-кластер, computer cluster, CCS, HPC, compute server, политика планирования, preemption, allocator, forum, администрирование систем, типы задач, deploy, интерфейс передачи сообщений, общая память, Профилирование, workflow, переобучение, EM64T, AMD, очередь заданий, список заданий, message passing, открытый стандарт, функциональное описание, создание процесса, Gigabit Ethernet, infiniband, NAT, системное программирование, механизм безопасности, joint, operating-system specific, шаблон узла, PXE, provisioning, SOA, латентность, job, управление заданиями, стандартный поток ввода, стандартный поток вывода, веб-сервис, computer basics
Введение
Во всю историю вычислительной техники не было момента, чтобы уровня развития вычислительной техники было достаточно для решения всех стоящих перед человечеством задач. Постоянно ставятся новые, все более сложные задачи, требующие все более мощных вычислительных ресурсов для своего решения. И современные технологии создания вычислительной техники подошли к рубежу, когда дальнейшее наращивание скорости работы индивидуальных устройств становится практически невозможным. В связи с этим развитие вычислительной техники пошло по экстенсивному пути, основанному на дублировании вычислительных устройств, которые в параллели могут работать над общей задачей. Вместе с этим родилось параллельное программирование, призванное дать возможность эффективно использовать параллельные архитектуры. И сегодня разработчики программных систем используют параллелизм на всех уровнях, начиная от нескольких конвейеров суперскалярных процессоров, и заканчивая параллельно работающими вычислительными узлами в GRID.
Отдельный класс параллельных архитектур представляют кластерные системы. Кластер - это совокупность вычислительных узлов, объединенных сетью. Параллельное приложение для кластерной системы представляет собой несколько процессов, которые общаются друг с другом по сети. Таким образом, если пользователь сумеет эффективно распределить свою задачу между несколькими процессорами на узлах кластера, то он может получить выигрыш в скорости работы, пропорциональный числу процессоров.
Как правило, кластерные системы крайне интенсивно используются для проведения вычислений. Предприятия и организации чаще всего приобретают кластеры для решения потока задач. И зачастую потребности желающих воспользоваться вычислительными ресурсами превосходят доступный объем ресурсов, поэтому к кластерам можно наблюдать очереди. Ситуация очень похожа на ту, что существовала с мэйнфреймами на заре компьютерной эпохи. В то время для эффективного управления потоками задач создавались так называемые системы пакетной обработки. Пользователи помещали свои задачи в очередь этих систем, а за результатом приходили через нескольких часов, а иногда и дней.
Примерно то же самое происходит сейчас на кластерах, поэтому правильное распределение нагрузки по вычислительным узлам кластера имеет очень большое значение. Этот вопрос приобретает еще большую важность в случае, если кластер имеет неоднородную структуру: различается мощность центральных процессоров, объем оперативной памяти, скорость участков локальной сети. Если не учитывать особенности аппаратуры, то можно наблюдать, как параллельное приложение простаивает, дожидаясь процесса, который был распределен на самый медленный вычислительный узел.
Помимо эффективного планирования запуска задач на кластере, необходимо также автоматизировать процессы приема пользовательских задач, постановки их в очередь, запуска и сбора результатов. Важно обеспечить безопасность использования кластера, его отказоустойчивость, сделав при этом работу с кластером максимально простой, избавляя пользователей от лишних технических подробностей. Все эти факторы приводят к необходимости создания специализированных систем управления кластерами, основная цель которых - предоставить удобные средства эффективного использования кластера.
История появления Microsoft High Performance Computing Server 2008
Долгое время среди операционных систем для кластеров лидировали UNIX-подобные системы. Прежде всего, это объясняется тем, что кластеры функционировали в основном в исследовательских организациях, большинство из которых по историческим причинам ориентированы на использование UNIX. Еще одним сдерживающим фактором распространения Windows на кластерах было отсутствие хорошей системы управления. Впоследствии, однако, многие системы управления были перенесены с UNIX на Windows (Condor, PBS, Platform LSF), но при этом остались трудны в эксплуатации для рядового пользователя Windows.
Отсутствие надежной и удобной системы управления причиняло многочисленные неудобства пользователям Windows-кластеров. В настоящее время многие организации для ведения своего бизнеса приобретают огромные парки вычислительных машин, и довольно часто выбор операционной системы решается в пользу Windows из соображений простоты и удобства использования. Если этой же организации необходимо было проводить массовые параллельные вычисления, то еще совсем недавно у нее практически не оставалось иного выбора, как приобретать Linux-кластер, поскольку стабильного и эффективного решения для Windows не существовало. Отсюда возникали различные сложности, связанные с интеграцией Linux-кластера в Windows-окружение, разработкой программного обеспечения под Linux и так далее. Фактически информационная инфраструктура организаций разделялась на Windows и Linux составляющие, поэтому много усилий уходило на то, чтобы организовать взаимодействие между ними.
9 июня 2006 года Microsoft объявила о выходе собственной системы управления Microsoft Compute Cluster Server 2003 (CCS). Система получила хорошую оценку и была признана очень удобной для небольших и средних Windows-кластеров. Крупные поставщики аппаратного обеспечения, такие как Hewlett Packard и IBM, практически сразу после появления CCS стали предлагать на ее основе интегрированные решения для HPC.
Появление CCS позволило снять целый ряд проблем. Существенно упростились процедуры разворачивания вычислительного кластера, его настройки и включения в информационную инфраструктуру организаций. Что особенно важно, вместе с CCS поставляется набор утилит для разработки параллельных приложений (реализация стандарта MPI2). Разработчики получили возможность разрабатывать и отлаживать параллельные программы в интегрированной среде Microsoft Visual Studio, а затем отправлять свои задания на кластер через дружественный графический интерфейс. Тем самым Microsoft обеспечил максимально простой переход разработчиков от последовательного программирования к параллельному, что раньше требовало приобретения массы дополнительных знаний, в том числе и об устройстве операционной системы Linux. Администратор Windows, даже без опыта в параллельных вычислениях, в состоянии развернуть CCS-кластер буквально за пару часов. Кластеры же на основе Linux при настройке обычно требуют значительных усилий и существенных знаний операци онной системы Linux.
В сентябре 2008 года вышел Microsoft High Performance Computing Server (HPC Server 2008 или HPC 2008) - новая версия системы управления кластером от Microsoft. HPC 2008 является логическим продолжением и наследует все лучшие черты CCS: простоту в использовании, развертывании и администрировании. При этом в HPC 2008 реализовано множество новых возможностей, которые могут существенно повысить отдачу от использования вычислительных ресурсов. Среди новых реализованных возможностей можно отметить следующее:
- Более эффективное распределение задач по узлам кластера:
- Возможность планирования на различных уровнях вычислительных ресурсов: ядра, сокеты, узлы,
- Новые политики планирования: подбор наилучших ресурсов, соответствующих запросу задания (resource matchmaking), приоритетное прерывание обслуживания (preemption), адаптивное выделение ресурсов (adoptive allocation),
- Поддержка стандарта HPC Basic Profile, разработанного Open Grid Forum, что дает возможность отправлять задания на кластер под управлением HPC 2008 из операционных систем и языков программирования, не поддерживаемых Microsoft,
- Удобные инструменты администрирования систем:
- Возможность создания групп из вычислительных узлов для автоматизации развертывания и выполнения обновлений и шаблонов задач для более удобного разграничения прав пользователей по запуску различных типов задач,
- Возможность использования нескольких головных узлов для повышения надежности системы,
- Упрощение развертывания больших кластеров за счет использования Windows Deployment Services,
- Новая, более удобная консоль администрирования, богатые возможности мониторинга вычислительных улов.
- Оптимизация интерфейса передачи сообщений (MPI):
- Улучшенная поддержка высокопроизводительных систем хранения данных.
Microsoft High Performance Computing Server 2008 тесно интегрируется с другими новейшими продуктами и технологиями Microsoft, такими как Microsoft Office SharePoint Server 2007, Windows Workflow Foundation и др., позволяет использовать информацию из Active Directory, что дает возможность встроить высокопроизводительный кластер в имеющуюся Windows - инфраструктуру без привлечения дополнительных специалистов и/или крупных расходов на переобучение сотрудников.
Системные требования
В качестве вычислительных узлов кластера могут быть использованы x64 процессоры семейства Intel Pentium или Xeon c технологией EM64T, 64 битные процессоры семейства AMD Opteron, AMD Phenom, AMD Athlon и совместимые. Минимальный размер оперативной памяти - 512 Мб, минимальный размер свободного дискового пространства - 50 Гб.
На вычислительных узлах кластера должна быть установлена операционная система Microsoft Windows Server 2008 x64 (Standard или Enterprise).
Архитектура системы
Компоненты системы
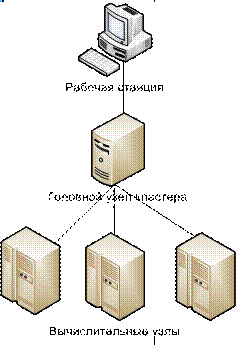
На рис.2.1 условно представлена архитектура вычислительного кластера, функционирующего под управлением HPC 2008:
- Вычислительные узлы (compute nodes) . Узлы, на которых происходит непосредственный запуск счетных заданий. На вычислительных узлах устанавливается Microsoft MPI и другие сервисы HPC Server 2008 управления вычислениям,
- Головной узел (head node). Выделенный узел, управляющий вычислениями на кластере. Головной узел принимает задания от пользователя, поддерживает очередь заданий, планирует запуски, собирает статистику выполнения и осуществляет другие служебные операции. Головной узел так же может совмещать роль вычислительного узла.
Дадим определение важнейшим понятиям, используемым в HPC 2008:
- Задание (job) - запрос на выделение вычислительного ресурса кластера для выполнения задач. Каждое задание может содержать одну или несколько задач,
- Задача (task) - команда или программа (в том числе, параллельная), которая должна быть выполнена на кластере. Задача не может существовать вне некоторого задания, при этом задание может содержать как несколько задач, так и одну,
- Планировщик заданий (job scheduler) - сервис, отвечающий за поддержание очереди заданий, выделение системных ресурсов, постанову задач на выполнение, отслеживание состояния запущенных задач,
- Узел (node) - вычислительный компьютер, включенный в кластер под управлением HPC 2008,
- Сокет (socket) - один из, возможно, нескольких вычислительных устройств (процессоров) узла. Даже в том случае, если процессор содержит несколько ядер под количеством сокетов будет пониматься количество устройств физически вставленных в материнскую плату (например, на компьютере с 2 процессорами Intel Xeon по 2 ядра в каждом 2 сокета),
- Ядро (core) - минимальный счетный элемент вычислительного узла. Количество ядер, доступное на вычислительном узле HPC 2008, совпадает с количеством виртуальных процессоров, отображаемых в программе Task Manager на узле,
- Очередь (queue) - список заданий, отправленных планировщику для выполнения на кластере. Порядок выполнения заданий определяется принятой на кластере политикой планирования,
- Список задач (task list) - эквивалент очереди заданий для задач каждого конкретного задания.
Microsoft MPI
Message Passing Interface (MPI, интерфейс передачи сообщений) - открытый стандарт, описывающий интерфейс обмена сообщениями между процессами параллельной программы. MPI объединяет узлы кластера вместе, предоставляя программисту функции, существенно упрощающие сложности, возникающие при программировании обмена данными между сотнями или тысячами узлов. В настоящее время MPI является наиболее часто используемым интерфейсом передачи сообщений на кластерных системах. Наиболее популярной реализации стандарта MPI является MPICH2, созданной в Argonne National Laboratory - организации, разработавшей и сам стандарт MPI.
MS MPI - реализация стандарта MPI (версии 2) от Microsoft. MS MPI основан на MPICH2 и продолжает разрабатываться так, чтобы остаться максимально совместимым с MPICH2. MS MPI включает всю функциональность, описанную в стандарте, за исключением динамического создания процессов.
При работе с HPC 2008 у пользователей остается возможность использовать реализации MPI сторонних компаний (например, MPICH2), но в этом случае часть функций HPC 2008 будет недоступна. Так, корректное освобождение всех ресурсов задания при его принудительной остановке гарантируется только при использовании MS MPI. Кроме того, использование MPI сторонних производителей, возможно, повлечет за собой необходимость ручного выполнения дополнительных административных операций.
Сетевые топологии
HPC 2008 может работать с различными сетевыми интерфейсами, среди которых наиболее популярные кластерные интерфейсы: Gigabit Ethernet, 10 Gigabit Ethernet, Infiniband и Myrinet. Для достижения наибольшей производительности рекомендуется использовать сетевое оборудование тех производителей, которые предоставляют NetworkDirect интерфейс, позволяющий максимально использовать сетевые ресурсы и при этом не загружать центральный процессор вспомогательной работой. Выигрыш от NetworkDirect интерфейса достигается за счет использования более короткой цепочки до сетевого оборудования, без промежуточного копирования пересылаемых данных, возникающего при использовании стандартного механизма сокетов.
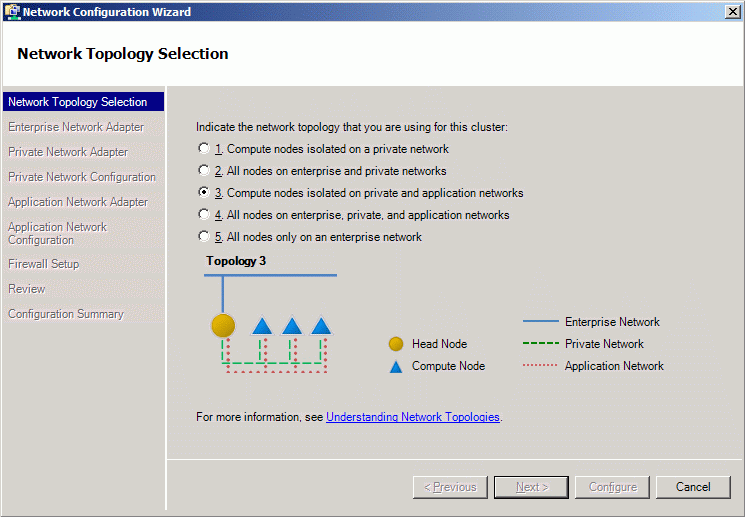
Использование нескольких сетевых интерфейсов одновременно может повысить производительность системы за счет разделения служебного трафика и MPI трафика. HPC 2008 поддерживает 5 вариантов сетевых топологий (см. рис. 2.2 ).
Правильный выбор топологии позволяет оптимизировать работу Ваших MPI-программ и системы в целом. При описании топологий используются следующие понятия:
- Открытая сеть ( Public network ) - корпоративная сеть организации, соединенная с головным и (возможно) вычислительными узлами кластера. Через открытую сеть пользователи подключаются к головному узлу для управления выполнением их заданий. MPI-трафик будет направлен через открытую сеть только в том случае, если нет закрытой или MPI - сети,
- Закрытая сеть ( Private network ) - выделенная сеть, предназначенная для коммуникации между узлами вычислительного кластера. Эта сеть (если она есть) будет использована для административного трафика (удаленный рабочий стол, установка вычислительных узлов с использованием RIS и пр.). Кроме того, через закрытую сеть будет направлен MPI - трафик в том случае, если нет специальной MPI - сети,
- MPI-сеть ( MPI network ) - выделенная сеть (предположительно, наиболее быстрая из 3 перечисленных), через которую идет трафик MPI - программ. В случае, если Ваша программа не использует MPI - библиотеки для передачи сообщений по сети, то MPI - сеть не будет использоваться.
Ниже приведено описание сетевых топологий, используемых в HPC 2008:
- Все узлы в открытой сети ( All nodes only on Public network ) - в этой конфигурации все узлы подключены к открытой сети (и только к ней). Весь сетевой трафик (MPI и административный) направляется через открытую сеть,
- Все узлы в открытой и закрытой сетях ( All nodes on Public and Private networks ) - в этой конфигурации все узлы соединены как открытой, так и закрытой сетями. Сетевой трафик (MPI и административный) направляется через закрытую сеть,
- Вычислительные узлы соединены только закрытой сетью ( Compute nodes isolated on Private networks ) - в этой конфигурации только головной узел соединен с открытой сетью, в то время как вычислительные узлы могут получить доступ к открытой сети только посредством NAT сервиса (сервис преобразования сетевых адресов) на головном узле. Сетевой трафик (MPI и административный) направляется через закрытую сеть,
- Все узлы в открытой, закрытой и MPI - сетях ( All nodes on Public, Private and MPI networks ) - в этой конфигурации все узлы подключены к открытой, закрытой и MPI-сетям. Административный трафик идет через закрытую сеть, а MPI-трафик - через MPI-сеть,
- Вычислительные узлы соединены закрытой и MPI - сетями ( Compute nodes isolated on Private and MPI networks ) - в этой конфигурации только головной узел подключен к открытой сети, в то время как в то время как вычислительные узлы могут получить доступ к открытой сети только посредством NAT сервиса на головном узле. Административный трафик идет через закрытую сеть, а MPI-трафик - через MPI-сеть.
Безопасность
Кластера обычно используются несколькими десятками или даже сотнями пользователей одновременно. При этом пользователи могут не иметь глубоких знаний в системном программировании и администрировании кластеров. Поэтому вопрос безопасности при использовании кластеров является очень важным. Пользователь кластера не должен иметь возможность нарушить правила использования вычислительного ресурса, нарушить ход выполнения задач других пользователей, посмотреть чужие результаты работы или изменить настройки системы. HPC Server 2008 использует Active Directory для выполнения всех пользовательских задач и команд администратора в контексте и именно с теми правами, которые имеет запускающий пользователь. Все права закодированы и хранятся вместе с заданием до окончания его выполнения. Административный трафик HPC 2008 пересылается с использованием закодированных каналов, что предотвращает несанкционированный перехват трафика и выполнение административных команд пользователями , не имеющими соответствующих прав. Механизмы безопасности, реализованные в MS MPI, не являются частью стандарта MPI, поэтому при использовании сторонних реализаций MPI информационная безопасность кластера может оказаться под угрозой.