Использование NAT в протоколе IPSec
Метод определения сбоя противоположной стороны IKE, основанный на наличии трафика
При взаимодействии по протоколам IKE и IPSec может возникнуть ситуация, когда между двумя участниками внезапно пропадает соединение. Такая ситуация возникает в результате проблем с маршрутизацией, переза-пуска одного из хостов и т.п. В этом случае часто не существует способа противоположной стороне определить потерю соединения. При этом SA могут существовать до тех пор, пока не истечет их время жизни. В результате этого образуется "черная дыра", в которую уходят пакеты. Часто тре-буется обнаружить черные дыры как можно скорее, чтобы обеспечить отказоустойчивость. Более того, часто необходимо определить черные дыры, чтобы предотвратить расходование лишних ресурсов.
Проблема определения падения противоположной стороны IKE реша-ется на стадии посылки Proposal, в которых указывается требование пе-риодической посылки сообщений HELLO/ACK, которые бы доказывали жизнеспособность противоположной стороны. Такая схема может быть как однонаправленной (только HELLO) или двунаправленной (пара HELLO/ACK). Часто используется термин "heartbeat" ("биение сердца") для однонаправленного сообщения проверки жизнеспособности, а термин "keepalive" используется для двунаправленных сообщений.
Как однонаправленные, так и двунаправленные сообщения посылаются через одинаковые интервалы времени. Частота, с которой они посылаются, во многом зависит от возможности их обработки. Если существует большое число одновременных IKE-сессий, то обработка доказательства жизнеспособности может быть затруднена.
Производители могут реализовать свои собственные подходы для определения жизнеспособности противоположной стороны без необходимости посылки сообщений через определенные интервалы. Данная схема, называемая Dead Peer Detection (DPD), основана на IKE-сообщениях Notify, в которых запрашивается жизнеспособность противоположной стороны IKE.
Сначала объясним использование обмена IKE-сообщениями для определения жизнеспособности противоположной стороны. Затем рассмотрим разницу в подходах heartbeat и keepalive. И, наконец, опишем формат Предложения DPD, который используется в описанных подходах. В заключении рассмотрим возникающие проблемы безопасности.
Обмен периодическими сообщениями для доказательства жизнеспособности
Как уже отмечалось, часто бывает необходимо как можно скорее определить, что соединение с противоположной стороной потеряно. IKE не предоставляет способа выполнить это, кроме как ждать до тех пор, пока не истечет период обновления ключей. В большинстве случаев это неприем-лемо, поэтому необходим способ проверки состояния противоположной стороны. В этом случае обычно использует IKE Notify либо в двунаправленном обмене сообщениями "keepalive" (HELLO, затем ACK), либо в однонаправленной посылке сообщения "heartbeat" (только HELLO).
Сравнение keepalive и heartbeat
Keepalive
Рассмотрим схему keepalive, в которой каждой стороне требуется регулярное подтверждение жизнеспособности противоположной стороны. Обмен сообщениями происходит с использованием аутентифицированного сообщения Notify. Оба участника в фазе I согласовывают интервал, в течение которого посылаются сообщения, например, 10 секунд. Каждое сообщение HELLO служит доказательством жизнеспособности противоположной стороны. В свою очередь каждая из сторон должна подтвердить сообщениеHELLO. Если по истечении 10 секунд какая-либо из сторон не получила HELLO, она сама посылает сообщение HELLO, ожидая ACK от противоположной стороны в качестве доказательства жизнеспособности. При получении как HELLO, так и ACK таймер перезапускается.
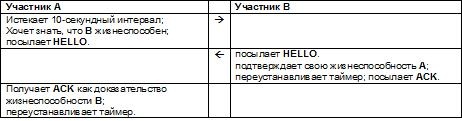
Сценарий 1:
У участника А 10-секундный таймер истекает первым, и он посылает HELLO участнику В. В отвечает ACK
Сценарий 2:
У участника А таймер истекает первым, он посылает HELLO участнику В. Участник В не отвечает. Участник А может повторить передачу, если он предполагает, что первое HELLO потеряно. Данная ситуация описывает, как участник А определяет, что соединение с противоположной стороной потеряно.

После определенного числа ошибок А считает, что у В произошел сбой, удаляет все SA и, возможно, инициализирует защиту от сбоев.
Преимущество данной схемы состоит в том, что участник, заинтересованный в жизнеспособности противоположной стороны, начинает обмен сообщениями. В Сценарии 1 участник А заинтересован в жизнеспособности участника В и, следовательно, посылает HELLO. В такой схеме возможно, чтобы участник В никогда не интересовался жизнеспособностью А. В данном случае ответственность за жизнеспособность соединения всегда лежит на стороне А, инициирующей обмен.
Heartbeat
Рассмотрим схему доказательства жизнеспособности, состоящую из однонаправленных (без подтверждения) сообщений. Сторона, которая за-интересована в жизнеспособности противоположной стороны, должна полагаться на то, что противоположная сторона сама периодически будет посылать сообщения, демонстрирую свою жизнеспособность. В данной схеме обмен сообщениями может быть следующим:
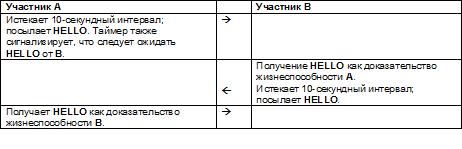
Сценарий 3:
Участники А и В заинтересованы в жизнеспособности друг друга. Определение жизнеспособности каждым участником зависит от того, будет ли другой периодически посылать HELLO
Сценарий 4:
Определение сбоя противоположной стороны.

Недостатком данной схемы является то, что предполагается, что противоположная сторона будет демонстрировать свою жизнеспособность. Но с другой стороны, участник В может никогда не интересоваться жизнеспособностью участника А. Тем не менее, если А интересуется жизнеспособностью В, В должен отдавать себе отчет в этом и поддерживать необходимую информацию о состоянии, периодически посылая HELLO к А. Недостаток данной схемы становится очевидным в сценарии удаленного доступа. Рассмотрим VPN-шлюз, на котором закан-чивается большое количество сессий (порядка 50 000 или более участников). Если какому-то участнику, требуется поддержка отказоустойчивости, то шлюз должен будет посылать HELLO-пакеты каждые 10 секунд. Такая схема плохо масштабируема, так как шлюз должен посылать 50 000 сообщений каждые несколько секунд.
В обеих схемах должны быть выполнены определенные переговоры, чтобы каждая сторона знала, как часто противоположная сторона предполагает получать сообщения HELLO. Это добавляет определенную слож-ность. Аналогично, необходимость периодически посылать сообщения (не зависимо от другого трафика IPSec/IKE) также добавляет вычислительную нагрузку на систему.