|
Прохожу курс "Построение распределенных систем на Java" в третьей лекции где описывается TCPServer вылетает эта ошибка
"Connection cannot be resolved to a type" Java version 1.7.0_05 |
Опубликован: 10.10.2010 | Уровень: специалист | Доступ: свободно
Дополнительный материал 1:
Параллелизм и репликация данных
Решение проблем параллелизма
Теперь можно приступить к рассмотрению описанных выше проблем, возникающих при параллельной обработке кортежей.
Проблема потери результатов обновления
Для нашего примера, поскольку мы собираемся изменять состояние объекта "Иванов", мы сначала должны наложить на него Х-блокировку. Соответственно, попытка наложения Х-блокировки другой транзакцией завершится успехом только после того, как первая транзакция блокировку снимет, а она это сделает только по завершении действия изменения. Таким образом, описанной проблемы просто не возникнет.
Следует отметить, что, хотя в таком случае результаты любых обновлений не будут утрачены, решение этой проблемы с помощью блокировки может привести к возникновению другой проблемы. Эта новая проблема называется тупиком,она рассматривается ниже в этом разделе.
Проблема незафиксированной зависимости
Проблема решается блокировкой объекта (аналогично предыдущему случаю).
Проблема несовместимого анализа
Проблема решается наложением S -блокировки на считываемые данные (в нашем случае это ВСЕ данные) и наложением Х -блокировок на два объекта, между которыми перемещаются средства. Проблема в этом случае только в том, что если транзакция по подсчету средств началась раньше, до ее завершения ни одна транзакция по переводу средств не сможет начаться (потому что ей придется наложить Х -блокировку на объекты, на которые уже наложена S -блокировка).
Тупиковая ситуация
Как было показано выше, блокировку можно использовать для разрешения трех основных проблем, возникающих при параллельном доступе к объектам. К сожалению, использование блокировок приводит к возникновению другой проблемы - тупиковой ситуации.
Тупиковая ситуация возникает тогда, когда две или более транзакции одновременно находятся в состоянии ожидания, причем для продолжения работы каждая из транзакций ожидает прекращения выполнения другой транзакции.
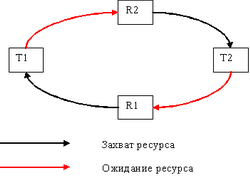
В случае двух транзакций она может быть проиллюстрирована следующим образом: первая транзакция заблокировала ресурс R1 и пытается наложить блокировку на ресурс R2. В то же время вторая транзакция заблокировала ресурс R2 и пытается наложить блокировку на R1. Очевидно, что ни одна из таких транзакций успешно завершена быть уже не может. Возможны и более сложные случаи тупиков, при использовании большего числа ресурсов и при участии в процессе блокировки большего числа транзакций. При анализе тупиков часто используют модель в виде графа, называемую графом состояния ожидания ресурсов. Такой граф содержит вершины двух типов - потоки и запрашиваемые ими ресурсы и дуги двух типов - захват потоком ресурса и ожидание потоком ресурса. Для нашего примера граф состояния ожидания будет иметь следующий вид (рис. 14.1).
Желательно, чтобы при возникновении тупиковой ситуации система могла обнаружить ее и найти из нее выход. Для обнаружения тупиковой ситуации следует обнаружить цикл в диаграмме состояний ожидания,т.е. в перечне транзакций, которые ожидают окончания выполнения других операций. Поиск выхода из тупиковой ситуации состоит в выборе одной из заблокированных транзакций в качестве жертвы и отмене ее выполнения. Таким образом, блокировка снимается, а выполнение другой транзакции может быть возобновлено.
На практике не все системы в состоянии обнаружить тупиковую ситуацию. Например, в некоторых из них используется хронометраж выполнения транзакций, и сообщение о возникновении тупиковой ситуации поступает, если транзакция не выполняется за некоторое предписанное заранее время.
Обратите внимание, что транзакция-жертва признается некорректной и отменяется не из-за собственной некорректности. В некоторых системах предусмотрен автоматический перезапуск транзакции с самого начала при условии, что обстоятельства, которые привели к тупиковой ситуации, не повторятся вновь. А в других системах в программу, связанную с данной транзакцией, просто посылается сообщение о вызвавшей тупиковую ситуацию транзакции-жертве для обработки этой ситуации в самой программе. С точки зрения программирования приложений предпочтительнее первый из этих подходов. Но, несмотря на это, всегда рекомендуется решать данную проблему с точки зрения пользователя.
Способность к упорядочению
В предыдущих разделах были описаны некоторые основы, необходимые для введения ключевого понятия "способность к упорядочению",которое является общепринятым критерием правильности управления параллельной обработкой данных. Точнее говоря, чередующееся выполнение заданного множества транзакций будет верным, если оно упорядочено, т.е. при его выполнении будет получен такой же результат, как и при последовательном выполнении тех же транзакций.
Полностью изолированные друг от друга транзакции принято называть упорядочиваемыми. Результат выполнения транзакций в таком случае не зависит от того, протекают ли они строго последовательно по одной в каждый момент времени либо все вместе и параллельно.
Уровни изоляции
Термин "уровень изоляции",грубо говоря, используется для описания степени вмешательства параллельных транзакций в работу некоторой заданной транзакции. Но при обеспечении возможности упорядочения не допускается никакого вмешательства, иначе говоря, уровень изоляции должен быть максимальным. Однако в реальных системах по различным причинам обычно допускаются транзакции, которые работают на уровне изоляции ниже максимального.
Уровень изоляции обычно рассматривается как некоторое свойство транзакции. В действительности нет никаких причин, по которым данная транзакция не могла бы работать в одно и то же время на различных уровнях изоляции в разных частях системы. Однако здесь для простоты уровень изоляции будет рассматриваться всего лишь как некоторое свойство транзакции.
Уровней изоляции может быть несколько, например, в стандарте языка SQL - четыре, а в системе DB2 фирмы IBM поддерживается два уровня. Если вас в первую очередь беспокоит проблема достоверности информации, следует применять максимальный уровень изоляции. Следует, однако, иметь в виду, что это приведет к резкому снижению степени параллелизма операций и пропускной способности системы в целом. Поэтому лучше попытаться отыскать разумный компромисс. Кроме того, никто не заставляет использовать одинаковые уровни изоляции для всех транзакций - следует выбирать те, которые в наибольшей мере отвечают имеющимся потребностям.
Далее мы рассмотрим уровни изоляции транзакций, и для того, чтобы это сделать, приведем неформальное описание эффектов, возникающих при параллельной обработке, и установим соответствие между уровнями изоляции и возможностью возникновения этих эффектов.
- Неаккуратное ("грязное") считывание.Допустим, транзакция Т1 выполняет обновление с некоторым объектом, затем транзакция Т2 извлекает состояние этого объекта, после чего выполнение Т1 отменяется. В результате транзакция Т2 обнаружит, что извлеченное ею состояние объекта никогда не существовало (поскольку не зафиксирована Т1).
- Неповторяемое считывание.Допустим, транзакция Т1 извлекает состояние объекта, транзакция Т2 изменяет это состояние и фиксирует транзакцию, после чего Т1 вновь извлекает состояние этого же объекта. Получается, что один и тот же объект для Т2 в разные моменты времени будет иметь разные состояния.
- Фиктивные элементы.Допустим, что транзакция Т1 извлекает какое-то множество элементов (процесс продолжителен во времени), транзакция Т2 добавила в это множество элемент и зафиксировала транзакцию. Т1, продолжая извлекать элементы, обнаружит элемент, которого раньше во множестве не было.
Далее приведена таблица возможных нарушений для разных уровней изоляции (таблица 14.5).
Фактически, последний из уровней изоляции обеспечивает наибольшую защиту транзакций от взаимного влияния.
Алмаз Мурзабеков