Спонсор: Microsoft
Вы можете этот курс.
Опубликован: 04.06.2009 | Уровень: специалист | Доступ: свободно | ВУЗ: Нижегородский государственный университет им. Н.И.Лобачевского
Лекция 6:
Вторая стадия концептуального проектирования (Модели данных СУБД. Представление концептуальной модели средствами модели данных СУБД)
6.2 Типовые модели данных СУБД и представление концептуальной модели
6.2.1. Сетевая модель данных
Это одна из наиболее ранних моделей данных СУБД. Типовая сетевая модель данных была предложена рабочей группой по базам данных (Data Base Task Group – DBTG) системного комитета CODASYL (Conference of Data System Languages), основными функциями которого были анализ известных фирменных систем обработки управленческих данных с единых позиций и в единой терминологии, обобщение опыта организации таких систем и разработка рекомендаций по созданию соответствующих систем. Структура данных сетевой модели определяется в терминах раздела 6.1 (элемент, запись, группа, групповое отношение, файл, база данных).
Реализация групповых отношений в сетевой модели осуществляется с использованием специально вводимых дополнительных полей - указателей (адресов связи или ссылок), которые устанавливают связь между владельцем и членом группового отношения. Запись может состоять в отношениях разных типов (1:1, 1:N, M:N). Заметим, что если один из вариантов установления связи 1:1 очевиден (в запись – владелец отношения, поля которой соответствуют атрибутам сущности, включается дополнительное поле – указатель на запись – член отношения), то возможность представления связей 1:N и M:N таким же образом весьма проблематична. Поэтому наиболее распространенным способом организации связей в сетевых СУБД является введение дополнительного типа записей (и соответственно, дополнительного файла), полями которых являются указатели.
Рассмотрим для примера представление группового отношения M:N. В модель вводится дополнительная группа (дополнительный вид записей). Элементы этой записи представляют собой указатели на две исходные группы и указатели на экземпляры рассматриваемой дополнительной записи, связывающие их в список (цепь), соответствующий M и (или) N членам группового отношения ( рис. 6.1.).
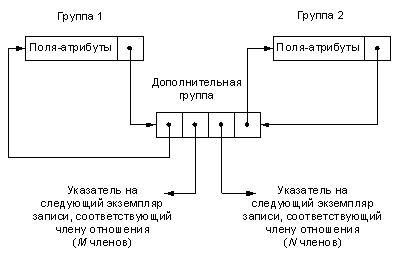
Представление связей 1:1, 1:M, N:1 является частным случаем связи типа M:N и осуществляется аналогично рассмотренному выше.
Заметим, что группа может быть членом более чем одного группового отношения. В этом случае вводится несколько дополнительных групп-указателей, а в группе – владельце отношений вводится несколько полей – указателей на дополнительные группы. Тогда множество записей (групп) и связей между ними образует некую сетевую структуру (ориентированный граф общего вида). Вершинами графа являются группы; дугами графа, направленными от владельца к члену группового отношения, – связи между группами.
Сетевая модель данных поддерживает все необходимые операции над данными, реализованные как действия со списковыми структурами. Сетевая модель данных является, вероятно, наиболее общей по возможностям представления концептуальной модели. По сути, любая ER-диаграмма без каких-либо изменений представляется средствами сетевой модели. К недостаткам сетевой модели обычно относят сложность получаемой на её основе концептуальной схемы и большую трудоемкость понимания соответствующей схемы внешним пользователем.
Рассмотрим пример записи части ER-диаграммы (СТУДЕНТ и ФАКУЛЬТЕТ) из предыдущей лекции в терминах сетевой СУБД. Для примера рассмотрим несколько экземпляров сущности СТУДЕНТ и сущности ФАКУЛЬТЕТ ( рис. 6.2.).
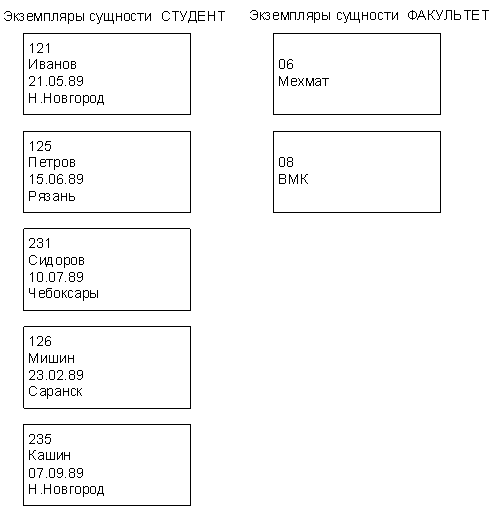
Пусть студенты Иванов, Петров, Мишин учатся на факультете ВМК, Сидоров и Кашин на механико-математическом факультете. Тогда сетевая модель соответствующего фрагмента ER-диаграммы будет выглядеть следующим образом ( рис. 6.3).
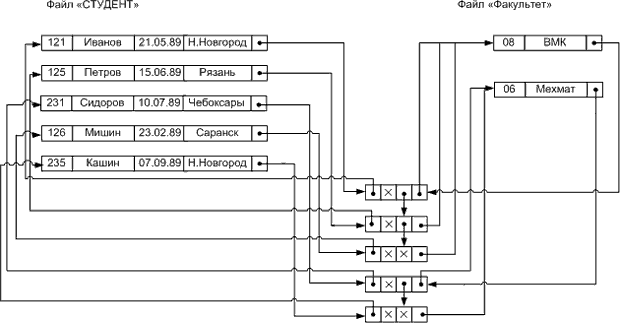
Заметим, что в дополнительном файле один из указателей не потребовался, так как рассматриваемая связь имеет тип 1:N, а не M:N. Значок x обозначает отсутствие дальнейшей связи.
Наиболее существенным недостатком сетевой модели является "жесткость" получаемой концептуальной схемы. Связи закреплены в записях в виде указателей. При появлении новых аспектов использования этих же данных может возникнуть необходимость установления новых связей между ними. Это требует введения в записи новых указателей, т.е. изменения структуры БД, и, соответственно, переформирования всей базы данных.
СУБД, поддерживающие сетевую модель, широко использовались на вычислительных системах серии IBM 360/370 (ЕС ЭВМ). В качестве примеров таких систем можно указать IDMS, UNIBAD (БАНК), и их аналоги СЕДАН, СЕТОР. На персональных компьютерах сетевые СУБД не получили широкого распространения. Примером сетевой СУБД для персонального компьютера является db_VISTA III. Отметим, что система db_VISTA реализована на языке С и поэтому является переносимой. Система может эксплуатироваться на ПЭВМ типа IBM PC, SUN, Macintosh.
6.2.2. Иерархическая модель данных
Это также одна из наиболее ранних моделей данных. Реализация групповых отношений в иерархической модели, как и в сетевой, может осуществляться с помощью указателей и представляется в виде графа. Однако, в отличие от сетевой модели, здесь существует ряд принципиальных особенностей.
- Групповые отношения являются отношениями соподчиненности. Группа (запись) – владелец отношения имеет подчиненные группы – члены отношений. Исходная группа называется предком, подчиненная – потомком.
- Групповые отношения образуют иерархическую структуру, которую можно описать как ориентированный граф следующего вида:
- имеется единственная особая вершина (соответствующая группе), называемая корнем, в которую не заходит ни одно ребро (группа не имеет предков);
- во все остальные вершины входит только одно ребро (все остальные группы имеют одного предка), а исходит произвольное количество ребер (группы имеют произвольное количество потомков);
- отсутствуют циклы.
- Иерархическая модель данных может представлять совокупность нескольких деревьев. В терминологии иерархической модели деревья, описывающие структуру данных, называются деревьями описания данных, а сами структурированные данные (база данных) – деревьями данных.
Особенностью реализации операций поиска в иерархической модели является то, что операция всегда начинает поиск с корневой вершины и специфицирует иерархический путь (последовательность связанных вершин) от корня до вершины, экземпляры которой удовлетворяют условиям поиска.
Необходимо отметить, что программы, реализующие операции иерархической модели, существенно проще, чем аналогичные программы для сетевой модели, т.к. здесь много легче осуществлять навигацию по структуре. Целесообразность появления иерархической модели обусловлена, конечно, тем, что большинство организационных систем реального мира имеют иерархическую структуру (административное деление страны, организационная структура предприятия и т.п.). Соответствующее концептуальное представление также будет иметь иерархическую структуру и естественным образом может быть описано в терминах иерархической модели. В качестве недостатков иерархической модели можно назвать вышеуказанные недостатки сетевой.
СУБД, поддерживающие иерархическую модель, достаточно широко использовались на вычислительных системах IBM 360/370 (ЕС ЭВМ). В качестве примеров таких систем можно указать IMS, OKA и широко тиражируемую в СССР отечественную разработку ИНЕС. Примером иерархической СУБД для персональных ЭВМ является отечественная система НИКА (адаптация системы ИНЕС к IBM PC).