


|
Подскажите, пожалуйста, планируете ли вы возобновление программ высшего образования? Если да, есть ли какие-то примерные сроки? Спасибо! |
Инспектор
Вы можете этот курс.
Опубликован: 20.12.2010 | Уровень: специалист | Доступ: платный
Лекция 13:
Метод моделирования "Свод данных"
Аннотация: В настоящей лекции рассматривается метод моделирования хранилищ данных, который получил название "Свод данных". Объясняются основные понятия метода, приводятся примеры построения логических моделей для "Свода данных".
Ключевые слова: метод моделирования "Свод данных", сущности-концентраторы (Hub Entities), связывающие сущности (Link Entities), сущности-сателлиты (Satellite Entities), сущность "Момент времени" (Point-In-Time), сущность-мост (Bridge), Data, звезда, table, relationship, parent, child, dimension, fact, artificial intelligence, извлечение знаний, Data Mining, файл, flat file, третья нормальная форма, 3NF, drilling, time stamp, подчиненная таблица, родительский ключ, non-conformity, data mart, data redundancy, гранулированность данных, взаимосвязанные киоски данных, гранулированность, graining, системы складирования данных, 1NF, 2NF, 4NF, 5NF, модель проектирования, многомерное моделирование, составной ключ, таблицы-мосты, сущность-связь для группировки пользователей (User Grouping Link), ADF, поддержка ссылочной целостности, referential integrity, supplier, объект, представление, БД, stage, алгоритм, предметной области
Цель лекции
Изучив материал настоящей лекции, вы будете знать:
- что представляет собой метод моделирования "Свод данных" ;
- что такое сущность-концентратор в модели "Свод данных";
- что такое сущность-связь в модели "Свод данных";
- что такое сущность-сателлит в модели "Свод данных";
- что такое сущность "момент времени" в модели "Свод данных";
- что такое сущность-мост в модели "Свод данных";
- алгоритм моделирования хранилища данных методом "Свод данных";
и научитесь:
- применять алгоритм моделирования хранилища данных методом "Свод данных";
- как формировать сущности-концентраторы в модели "Свод данных";
- как формировать сущности-связи в модели "Свод данных";
- как формировать сущности-сателлиты в модели "Свод данных";
- как заполнять объекты "Свода данных".
Литература: [57], [59], [60], [61], [37].
Введение
Свод данных (Data Vault) как метод моделирования данных для ХД был предложен в конце 2002 года Dan Linstedt [57]. Метод моделирования "Свод данных" — это методология проектирования, разработанная для глобальных ХД масштаба предприятия и имеющая в основе набор связанных нормализованных таблиц, ориентированных на поддержку функциональных областей бизнеса с возможностью отражения истории. Метод удачно сочетает требования нормализации и возможности схемы "звезда".
Использование этого метода предполагает наличие у проектировщика ХД базового уровня знаний в области моделирования данных, т.е. понимание таких терминов, как таблица (table), взаимосвязь (relationship), родитель (parent), потомок (child), ключ (primary/foreign key), измерение (dimension) и факт (fact).
Исследователи в области обработки данных постоянно ищут структуры данных для приложений искусственного интеллекта (artificial intelligence — AI) и извлечения знаний (data mining — DM). Большинство технологий DM предполагает импорт данных из подающих информационных систем в плоский файл (flat file) для того, чтобы объединить форму представления данных с функцией извлечения знаний. Поскольку объем данных в ХД растет быстро, экспорт информации для приложений DM становится затруднительным. Таким образом, возникает разрыв между формой представления (структурой), функцией (AI) и выполнением (DM).
Такой разрыв между формой, функцией и выполнением снижает эффективность использования методов AI и DM. Поэтому задача разработки структур данных, которые математически позволяют использовать технологии AI непосредственно в базах данных, остается очень актуальной. С точки зрения моделирования структур данных метод Data Vault основан на математических принципах, которые позволяют эффективно управлять большими объемами информации. Особенно этот метод эффективен для создания структур данных для динамического управления изменениями во взаимосвязях между данными как единицами представления информации в компьютерных системах. Он позволяет динамически управлять изменением взаимосвязей между данными в системе в процессе эволюции сохраняемых в ней данных.
Метод моделирования "Свод данных" (Data Vault)
Определение метода проектирования "Свод данных" (Data Vault)
Свод данных (Data Vault), по определению, является ориентированным на детали набором нормализованных связанных таблиц, которые обеспечивают информационную поддержку одной или более предметных областей деятельности организации. Этот подход является комбинацией методики реляционного проектирования (до третьей нормальной формы — 3NF) и методики многомерного проектирования. Метод моделирования "Свод данных" был разработан для создания моделей данных глобальных ХД масштаба предприятия. Он основан на математических принципах, которые поддерживают нормализованные модели данных. По существу модель "Свод данных" соответствует нормализованной до 3NF схеме "звезда", включая измерения, связи "многие ко многим" и таблицы стандартной структуры. Различие лежит в более детальном представлении взаимосвязей и элементов данных, структурированных и детализованных во временном изменении. Этот метод проектирования был разработан, чтобы объединить гибкость структур обработки данных OLTP-систем с мощностью аналитической обработки данных в OLAP-системах. Он является масштабируемым и легко адаптируемым методом разработки структур данных для решения задач анализа данных в масштабах предприятия.
Проблемы моделирования данных для хранилищ данных
Обычно применение известных методик проектирования к разработке модели ХД масштаба предприятия, например, таких как нормализация, сталкивается с рядом трудностей.
В частности, использование 3NF для структур данных приводит к следующему.
- Временная зависимость в первичном ключе (time-driven primary key) приводит к увеличению сложности поддержки отношения "родитель-потомок" и учету влияния каскадных изменений в таких отношениях.
- Сложно обеспечить высокую производительность при загрузке данных в реальном времени в структуру в 3NF.
- Во многих случаях усложняется доступ к данным при обработке запросов.
- Возникают проблемы при использовании анализа на основе свертки-развертки данных (drill-down analysis).
На рис. 18.1 показана попытка адаптировать структуру данных в 3NF к использованию в ХД. Одна из проблем этой структуры связана с размещением временной метки (data/time stamp) в первичном ключе родительской таблицы, для того чтобы представить изменения детальных данных во времени. Это проблема масштабируемости и гибкости структуры. Если данные добавляются в родительскую таблицу, изменения каскадно распространяются через все подчиненные таблицы. Например, когда новая строка вставляется с родительским ключом (parent key), у которого изменяется только поле временной метки, все дочерние строки должны быть переназначены на новый родительский ключ. Этот каскадный эффект имеет отрицательное влияние на обработку данных в таких таблицах, причем чем сложнее и больше структура, тем сильнее влияние каскадного эффекта. Для модели данных масштаба предприятия это создает трудности в расширении и сопровождении модели данных, и, как следствие, усложняется процесс проектирования.
Существует проблема и для взаимосвязанных киосков данных (conformed data marts). Такая архитектура глобального ХД представляет собой набор таблиц фактов, которые связаны между собой посредством первичных и внешних ключей или, другими словами, набор взаимосвязанных схем "звезда". При такой реализации ХД возникает ряд проблем, таких как изолированное представление предметно-ориентированных областей, возможное дублирование данных (data redundancy), различие представления таблиц фактов по уровню структурированности (детализуемости или гранулированности) данных, синхронизация данных во время загрузки в реальном времени, ограниченность использования технологии DM в масштабах предприятия и др. Схема "звезда" является типичной архитектурой, которая проектируется и реализуется по методологии "снизу вверх", и взаимосвязанные киоски данных создаются на основе подхода "снизу вверх", а реализуются на основе подхода "сверху вниз".
Одной из наиболее сложных проблем взаимосвязанных киосков данных является выбор правильного уровня гранулированности данных (grain) для таблиц фактов. Это означает, что агрегирование данных во всех таблицах будет согласованным по измерению времени, а структура каждой таблицы фактов не будет изменяться с точки зрения добавления новых измерений. Такой подход к проектированию ограничивает масштабируемость и гибкость модели данных. Другой проблемой могут быть вспомогательные таблицы в измерениях, которые обслуживают ссылки для взаимоотношений между измерениями. Гранулированность и стабильность измерений являются важными факторами успешного проектирования ХД.
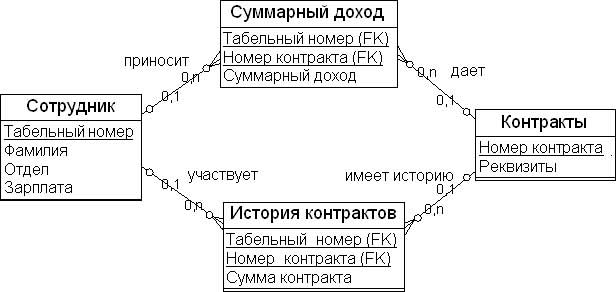
Например, если гранулированность факта "Суммарный доход" таблицы "Суммарный доход" ( рис. 18.2) изменяется, то это должно привести к дублированию таблицы фактов с добавлением дополнительных атрибутов. Предположим, что таблицы фактов связаны между собой только посредством одних и тех же ключей измерений. При добавлении нового измерения к одной из таблиц фактов (например, к таблице фактов "Суммарный доход" добавим измерение "Контракт") факты в таблице "История контрактов" также должны измениться. Таблицы фактов не изменятся, только если они имеют одну и ту же гранулированность.
Среди практиков-разработчиков ХД сложилось мнение, что архитектура ХД должна проектироваться на основе методологии "сверху вниз", а реализация выполняться на основе методологии "снизу вверх". Такой подход позволяет максимально приблизить архитектуру к пониманию задач предметной области ХД, в то время как реализация может поэтапно включать фрагменты предметной области в общее ХД, не нарушая миссию и видение системы складирования данных. Подходы к проектированию и разработке архитектуры ХД должны быть гибкими, чтобы быстро адаптироваться к росту объема данных и расширению или изменению предметных областей в системе.
Одним из подходов к решению задач разработки типовых моделей и архитектур данных является определенная нормализация структур данных. Так же, как и структуры БД OLTP-систем (1NF, 2NF, 3NF; 4NF, 5NF), БД ХД должны иметь определенную степень нормализации структуры данных. Модель "Свод данных" и является одной из таких нормализованных структур данных для ХД. Она включает методы построения структур данных для отношений "многие ко многим", ссылочной целостности, минимизации дублирования данных и установления семантических связей между ключевыми бизнес-функциями предметной области через концентраторы (hubs).
Элементы модели "Свод данных"
Модель проектирования "Свод данных", аналогично методам многомерного моделирования или " сущность-связь ", содержит ряд структурных компонент, новыми из которых являются сущности-концентраторы, или хабы, сущности-связи и сущности-сателлиты. Проектирование этим методом фокусируется на функциональных предметных областях деятельности организации. Каждая такая область характеризуется бизнес-ключом и представляется в концентраторе первичным ключом. Сущности-связи обеспечивают интеграцию операций между хабами. Сущности-сателлиты обеспечивают контекст первичного ключа хаба. Каждая из этих сущностей сконструирована для обеспечения максимальной гибкости и масштабируемости модели данных ХД масштаба предприятия.
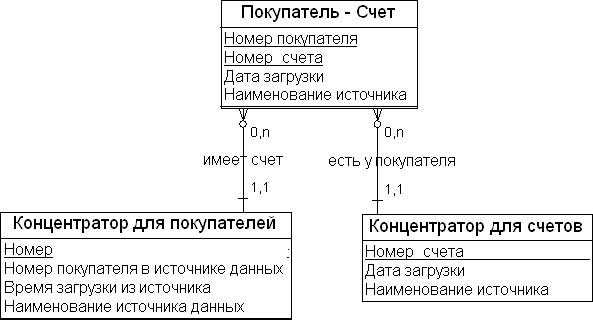
Сущности-концентраторы (Hub Entities). Сущности-концентраторы, или просто хабы (hubs), являются таблицей, которая содержит минимальный список бизнес-ключей (натуральных ключей). Это ключи, которые используются организацией в каждой ежедневной операции: например, номер счета, табельный номер сотрудника, номер покупателя, номер изделия и номер автомобиля. Если в процессе деятельности такой ключ был потерян, то, как правило, теряются и ссылка на контекст, и сопутствующая информация. Помимо натуральных ключей (на рис. 18.3 – атрибут "Номер покупателя в источнике данных"), концентраторы могут иметь следующие атрибуты:
- суррогатный ключ – опциональный атрибут, который является обычно членом числовой последовательности. На рис. 18.3 – атрибут "Номер";
- временная метка загрузки (Load Data/Time Stamp) – это дата и время, когда ключ впервые появился в БД. На рис. 18.3 — атрибут "Время загрузки из источника";
- источник данных (Record Source) – записывается для трассировки данных. На рис. 18.3 — атрибут "Наименование источника данных".
Рис. 18.3 показывает пример сущности "Концентратор для покупателей". В этой сущности атрибут "Номер покупателя в источнике данных" является первичным бизнес- ключом, а атрибут "Номер" является суррогатным ключом, назначенным для покупателей внутри системы. В табл. 18.1 приведен пример контекста для сущности "Концентратор для покупателей".
| Номер | Номер покупателя в источнике данных | Время загрузки из источника | Наименование источника данных |
|---|---|---|---|
| 1 | 1234 | 23.01.2009 | Продажи |
| 2 | 1235 | 24.01.2009 | Контракты |
| 3 | 2266 | 26.01.2009 | Финансы |
| 4 | 2344 | 28.01.2009 | Продажи |
Cущности-концентраторы не могут быть связаны отношением "один ко многим" (родитель-потомок). Для построения взаимосвязей между концентраторами используются сущности-связи.
Связывающая сущность, или сущность-связь (Link Entitiy). Сущности-связи являются физическим представлением взаимосвязи "многие ко многим" в 3NF. Связь представляет собой взаимоотношение или операцию между двумя или более бизнес-компонентами или бизнес-ключами. Сущности-связи содержат следующие атрибуты (см. рис. 18.4):
- суррогатный ключ – опциональный атрибут, который используется при связывании более двух концентраторов (на рис. 18.4 не показан);
- ключи концентраторов (Hub Key) – ключи концентраторов, которые мигрируют в сущность-связь для формирования составного ключа, связывающего эти концентраторы;
- временная метка загрузки (Load Data/Time Stamp) – дата и время записи связи в БД;
- источник данных (Record Source) – используется для трассировки данных.
Этот компонент модели предназначен для разрешения проблемы отношения "многие ко многим" для ХД. Вместе с сущностями-концентраторами связывающие сущности описывают поток данных предметной области ХД. Табл. 18.2 иллюстрирует содержание соответствующих сущностям таблиц БД.
| Концентратор для покупателей | |||
|---|---|---|---|
| Номер | Номер покупателя в источнике данных | Время загрузки из источника | Наименование источника данных |
| 1 | 1234 | 23.01.2009 | Продажи |
| 2 | 1235 | 24.01.2009 | Контракты |
| Связывающая сущность | |||
| Идентификатор покупателя | Идентификатор счета | Время загрузки из источника | Наименование источника данных |
| 1 | 100 | 25.01.2009 | Продажи |
| 2 | 200 | 26.01.2009 | Контракты |
| Концентратор для счетов | |||
| Номер | Номер счета в источнике данных | Время загрузки из источника | Наименование источника данных |
| 100 | 12/124 | 25.01.2009 | Продажи |
| 200 | 12/135 | 26.01.2009 | Контракты |
Владислав Нагорный
Лариса Парфенова
|
1) Можно ли экстерном получить второе высшее образование "Программная инженерия" ? 2) Трудоустраиваете ли Вы выпускников? 3) Можно ли с Вашим дипломом поступить в аспирантуру?
|