|
Не могу найти требования по оформлению выпускной контрольной работы по курсу профессиональной переподготовки "Менеджмент предприятия" |
Опубликован: 16.12.2009 | Уровень: для всех | Доступ: свободно
Лекция 4:
Статистический анализ числовых величин (непараметрическая статистика)
Аннотация: В лекции рассматриваются вопросы непараметрического доверительного оценивания характеристик распределения, проверки однородности двух независимых (критерии Стьюдента, Крамера-Уэлча, Вилкоксона, Смирнова, омега-квадрат) и для связанных выборок.
Ключевые слова: ПО, коэффициент вариации, нормальное распределение, погрешность, случайная величина, факторный анализ, параметр, функция, регрессионный анализ, аксиома, полезность, неравенство, константы, нормальный закон, нижняя граница, класс, сходимость, автор, дискретная случайная величина, аппроксимация, вероятность, вероятностная модель, грубые погрешности, робастность, гипотеза, решающее правило, статистический критерий, значение, Квантиль, выборка, значимость критерия, отрезок, верхняя граница, определение функции, вывод, расстояние, эмпирическая функция, анализ, пункт, предметной области, объем выборки, выборочной средней, дисперсия, доверительная вероятность, математическим ожиданием, натуральное число, статистика, основание, медиана, доверительный интервал, интервальная оценка, линеаризация, координаты, постановка задачи, однородность, сегменты, объединение, статистическая гипотеза, статистические методы, доказательство, товар, показатель эффективности, альтернативные, мощность критерия, точность, равенство, отношение, разность, множитель, метод статистических испытаний, асимметрия, место, принятия решений, ранг, таблица, пара функций, график, минимум, максимум, критическая область, отрицание, поиск, альтернатива, шкала измерений, мощность, работ, письмо, биномиальное распределение, интервал, программное обеспечение, уровень модели, excel
В учебных курсах по теории вероятностей и математической статистике рассматривают различные параметрические семейства распределений числовых случайных величин. А именно, изучают семейства нормальных распределений, логарифмически нормальных, экспоненциальных, гамма-распределений, распределений Вейбулла-Гнеденко и др. Все они зависят от одного, двух или трех параметров. Поэтому для полного описания распределения достаточно знать или оценить одно, два или три числа. Очень удобно. Поэтому широко развита параметрическая теория математической статистики, в которой предполагается, что распределения результатов наблюдений принадлежат тем или иным параметрическим семействам.
К сожалению, параметрические семейства существуют лишь в головах авторов учебников по теории вероятностей и математической статистике. В реальной жизни их нет. Поэтому эконометрика использует в основном непараметрические методы, в которых распределения результатов наблюдений могут иметь произвольный вид.
Сначала на примере нормального распределения подробнее обсудим невозможность практического использования параметрических семейств для описания распределений конкретных экономических данных. Затем разберем параметрические методы отбраковки резко выделяющихся наблюдений и продемонстрируем невозможность практического использования ряда методов параметрической статистики, ошибочность выводов, к которым они приводят. Затем разберем непараметрические методы доверительного оценивания основных характеристик числовых случайных величин - математического ожидания, медианы, дисперсии, среднего квадратического отклонения, коэффициента вариации. Завершат лекцию методы проверки однородности двух выборок, независимых или связанных.
Часто ли распределение результатов наблюдений является нормальным?
В эконометрических и экономико-математических моделях, применяемых, в частности, при изучении и оптимизации процессов маркетинга и менеджмента, управления предприятием и регионом, точности и стабильности технологических процессов, в задачах надежности, обеспечения безопасности, в том числе экологической, функционирования технических устройств и объектов, разработки организационных схем часто применяют понятия и результаты теории вероятностей и математической статистики. При этом зачастую используют те или иные параметрические семейства распределений вероятностей. Наиболее популярно нормальное распределение. Используют также логарифмически нормальное распределение, экспоненциальное распределение, гамма-распределение, распределение Вейбулла-Гнеденко и т.д.
Очевидно, всегда необходимо проверять соответствие моделей реальности. Возникают два вопроса. Отличаются ли реальные распределения от используемых в модели? Насколько это отличие влияет на выводы?
Ниже на примере нормального распределения и основанных на нем методов отбраковки резко отличающихся наблюдений (выбросов) показано, что реальные распределения практически всегда отличаются от включенных в классические параметрические семейства, а имеющиеся отклонения от заданных семейств делают неверными выводы, в рассматриваемом случае, об отбраковке, основанные на использовании этих семейств.
Есть ли основания априори предполагать нормальность результатов измерений?
Иногда утверждают, что в случае, когда погрешность измерения (или иная случайная величина) определяется в результате совокупного действия многих малых факторов, то в силу Центральной Предельной Теоремы (ЦПТ) теории вероятностей эта величина хорошо приближается (по распределению) нормальной случайной величиной. Такое утверждение справедливо, если малые факторы действуют аддитивно и независимо друг от друга. Если же они действуют мультипликативно, то в силу той же ЦПТ аппроксимировать надо логарифмически нормальным распределением. В прикладных задачах обосновать аддитивность, а не мультипликативность действия малых факторов обычно не удается. Если же зависимость имеет общий характер, не приводится к аддитивному или мультипликативному виду, а также нет оснований принимать модели, дающие экспоненциальное, Вейбулла-Гнеденко, гамма или иные распределения, то о распределении итоговой случайной величины практически ничего не известно, кроме внутриматематических свойств типа регулярности.
При обработке конкретных данных иногда считают, что погрешности измерений имеют нормальное распределение. На предположении нормальности построены классические модели регрессионного, дисперсионного, факторного анализов, метрологические модели, которые еще продолжают встречаться как в отечественной ноpмативно-технической документации, так и в международных стандартах. На то же предположение опираются модели расчетов максимально достигаемых уровней тех или иных характеристик, применяемые при проектировании систем обеспечения безопасности функционирования экономических структур, технических устройств и объектов. Однако теоретических оснований для такого предположения нет. Необходимо экспериментально изучать распределения погрешностей.
Что же показывают результаты экспериментов? Сводка, данная в монографии [1], позволяет утверждать, что в большинстве случаев распределение погрешностей измерений отличается от нормального. Так, в Машинно-электротехническом институте (г. Варна в Болгарии) было исследовано распределение погрешностей градуировки шкал аналоговых электроизмерительных приборов. Изучались приборы, изготовленные в Чехословакии, СССР и Болгарии. Закон распределения погрешностей оказался одним и тем же. Он имеет плотность
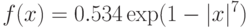
Были проанализированы данные о параметрах 219 фактических распределениях погрешностей, исследованных разными авторами, при измерении как электрических, так и не электрических величин самыми разнообразными (электрическими) приборами. В результате этого исследования оказалось, что 111 распределений, т.е. примерно 50% , принадлежат классу распределений с плотностью
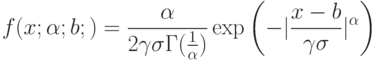
где  - параметр степени;
- параметр степени;  - параметр сдвига;
- параметр сдвига; 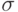 - параметр масштаба;
- параметр масштаба; 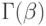 - гамма-функция от аргумента
- гамма-функция от аргумента 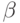 ;
;
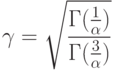
(см. [1, с. 56]); 63 распределения, т.е. 30%, имеют плотности с плоской вершиной и пологими длинными спадами и не могут быть описаны как нормальные или, например, экспоненциальные. Оставшиеся 45 распределений оказались двухмодальными.
В книге известного метролога проф. П. В. Hовицкого [2] приведены результаты исследования законов распределения различного рода погрешностей измерения. Он изучил распределения погрешностей электромеханических приборов на кернах, электронных приборов для измерения температур и усилий, цифровых приборов с ручным уpавновешиванием. Объем выборок экспериментальных данных для каждого экземпляра составлял 100-400 отсчетов. Оказалось, что 46 из 47 распределений значимо отличались от нормального. Исследована форма распределения погрешностей у 25 экземпляров цифровых вольтметров Щ-1411 в 10 точках диапазона. Результаты аналогичны. Дальнейшие сведения содержатся в монографии [1].
В лаборатории прикладной математики Тартуского государственного университета проанализировано 2500 выбоpок из архива реальных статистических данных. В 92% гипотезу нормальности пришлось отвергнуть.
Приведенные описания экспеpиментальных данных показывают, что погрешности измерений в большинстве случаев имеют распределения, отличные от нормальных. Это означает, в частности, что большинство применений критерия Стьюдента, классического регрессионного анализа и других статистических методов, основанных на нормальной теории, строго говоря, не является обоснованным, поскольку неверна лежащая в их основе аксиома нормальности распределений соответствующих случайных величин.
Очевидно, для оправдания или обоснованного изменения существующей практики анализа статистических данных требуется изучить свойства процедур анализа данных при "незаконном" применении. Изучение процедур отбраковки показало, что они крайне неустойчивы к отклонениям от нормальности, а потому применять их для обработки реальных данных нецелесообразно (см. ниже); поэтому нельзя утверждать, что произвольно взятая процедура устойчива к отклонениям от нормальности.
Иногда предлагают перед применением, например, критерия Стьюдента однородности двух выбоpок проверять нормальность. Хотя для этого имеется много критериев, но проверка нормальности - более сложная и трудоемкая статистическая процедура, чем проверка однородности (как с помощью статистик типа Стьюдента, так и с помощью непараметрических критериев). Для достаточно надежного установления нормальности требуется весьма большое число наблюдений. Так, чтобы гарантировать, что функция распределения результатов наблюдений отличается от некоторой нормальной не более, чем на 0,01 (при любом значении аргумента), требуется порядка 2500 наблюдений. В большинстве экономических, технических, медико-биологических и других прикладных исследований число наблюдений существенно меньше. Особенно это справедливо для данных, используемых при изучении проблем, связанных с обеспечением безопасности функционирования экономических структур и технических объектов.
Иногда пытаются использовать ЦПТ для приближения распределения погрешности к нормальному, включая в технологическую схему измерительного прибора специальные сумматоры. Оценим полезность этой меры. Пусть 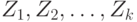 - независимые одинаково распределенные случайные величины с функцией распределения
- независимые одинаково распределенные случайные величины с функцией распределения 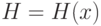 такие, что
такие, что  Рассмотрим
Рассмотрим

Показателем обеспечиваемой сумматором близости к нормальности является
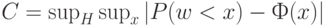
Тогда

Правое неравенство в последнем соотношении вытекает из оценок константы в неравенстве Берри-Эссеена, полученном в книге [3, с.172], а левое - из примера в монографии [4, с.140-141]. Для нормального закона 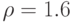 , для равномерного
, для равномерного 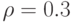 , для двухточечного
, для двухточечного  (это - нижняя граница для
(это - нижняя граница для  ). Следовательно, для обеспечения расстояния (в метрике Колмогорова) до нормального распределения не более 0,01 для "неудачных" распределений необходимо не менее
). Следовательно, для обеспечения расстояния (в метрике Колмогорова) до нормального распределения не более 0,01 для "неудачных" распределений необходимо не менее 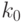 слагаемых, где
слагаемых, где
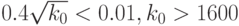
В обычно используемых сумматорах слагаемых значительно меньше. Сужая класс возможных распределений 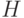 , можно получить, как показано в монографии [5], более быструю сходимость, но теория здесь еще не смыкается с практикой. Кроме того, не ясно, обеспечивает ли близость распределения к нормальному (в определенной метрике) также и близость распределения статистики, построенной по случайным величинам с этим распределением, к распределению статистики, соответствующей нормальным результатам наблюдений. Видимо, для каждой конкретной статистики необходимы специальные теоретические исследования, Именно к такому выводу приходит автор монографии [5]. В задачах отбраковки выбросов ответ: "Не обеспечивает" (см. ниже).
, можно получить, как показано в монографии [5], более быструю сходимость, но теория здесь еще не смыкается с практикой. Кроме того, не ясно, обеспечивает ли близость распределения к нормальному (в определенной метрике) также и близость распределения статистики, построенной по случайным величинам с этим распределением, к распределению статистики, соответствующей нормальным результатам наблюдений. Видимо, для каждой конкретной статистики необходимы специальные теоретические исследования, Именно к такому выводу приходит автор монографии [5]. В задачах отбраковки выбросов ответ: "Не обеспечивает" (см. ниже).
Отметим, что результат любого реального измерения записывается с помощью конечного числа десятичных знаков, обычно небольшого (2-5), так что любые реальные данные целесообразно моделировать лишь с помощью дискретных случайных величин, принимающих конечное число значений. Нормальное распределение - лишь аппроксимация реального распределения. Из принципа Дирихле следует, что в какой-то точке построенная по данным работы [6] функция распределения отличается от ближайшей функции нормального распределения не менее чем на 1/26, т.е. на 0,04. Кроме того, очевидно, что для нормального распределения случайной величины вероятность попасть в дискретное множество десятичных чисел с заданным числом знаков после запятой равна 0.
Из сказанного выше следует, что результаты измерений и вообще статистические данные имеют свойства, приводящие к тому, что моделировать их следует случайными величинами с распределениями, более или менее отличными от нормальных. В большинстве случаев распределения существенно отличаются от нормальных, в других нормальные распределения могут, видимо, рассматриваться как некоторая аппроксимация, но никогда нет полного совпадения. Отсюда вытекает как необходимость изучения свойств классических статистических процедур в неклассических вероятностных моделях (подобно тому, как это сделано ниже для критерия Стьюдента), так и необходимость разработки устойчивых (учитывающих наличие отклонений от нормальности) и непараметрических, в том числе свободных от распределения процедур, их широкого внедрения в практику статистической обработки данных.
Опущенные здесь рассмотрения для других параметрических семейств приводят к аналогичным выводам. Итог можно сформулировать так. Распределения реальных данных практически никогда не входят в какое-либо конкретное параметрическое семейство. Реальные распределения всегда отличаются от тех, что включены в параметрические семейства. Отличия могут быть большие или маленькие, но они всегда есть. Попробуем понять, насколько важны эти различия для проведения эконометрического анализа.
Михаил Агапитов
Подобед Александр
|
Я нажал кнопку "начать курс" и почти его уже закончил, но для получения диплома на бумаге, нужно его же оплатить? Как оплатить? |