Опубликован: 28.09.2007 | Уровень: специалист | Доступ: свободно
Лекция 2:
Транспортные протоколы Интернет
2.2.1 Модели реализации протокола TCP и его перспективы
Как известно протокол TCP (описание протокола смотри, например, в [2.38]) ориентирован на соединение, он использует для транспортировки IP-дейтаграммы (L3), которые пересылаются посредством протокольных кадров уровня L2. Между двумя партнерами может быть прямое соединение, а может располагаться большое число сетевых приборов уровней L2 и L3 (см. рис. 2.9). Если потоки входящих и выходящих сегментов для заданного сетевого устройства равны, режим стационарен и состояние его буферов не меняется. Но маршрутизаторы и переключатели обычно являются многоканальными устройствами. По этой причине, если даже партнеры ТСР-соединения рассчитаны на идентичную скорость обмена, возможна ситуация, когда некоторое сетевое устройство, вовлеченное в обмен, окажется перегруженным. Ведь всегда могут возникать и исчезать новые сессии информационного или мультимедийного обмена, использующие частично те же сетевые устройства. Протокол ТСР функционирует нормально при выполнении ряда условий.
- Вероятность ошибки доставки (BER) невелика, и потеря пакета вероятнее всего происходит из-за переполнения буфера. Если потеря пакета из-за его искажения существенна, понижение CWND не поможет, и пакеты будут теряться с той же вероятностью (здесь было бы уместно поискать оптимальное значение MTU ).
- Время доставки ( RTT ) достаточно стабильно, и для его оценки можно использовать простые линейные аппроксимации. Здесь подразумевается, что в рамках сессии все пакеты следуют одним и тем же путем и смена порядка прихода пакетов, хотя и допускается, но маловероятна. Разрешающая способность внутренних часов отправителя должна быть достаточно высока, в противном случае возникают серьезные потери из-за таймаутов.
- Сеть имеет фиксированную полосу пропускания и, во всяком случае, не допускает скачкообразных ее вариаций. В противном случае потребовался бы механизм для прогнозирования полосы пропускания, а действующие алгоритмы задания CWND оказались бы не эффективными.
- Буферы сетевых устройств используют схему первый_вошел-первым_вышел (FIFO). Предполагается, что размер этих буферов соответствует произведению RTT*B ( B - полоса пропускания, RTT - сумма времен транспортировки сегмента от отправителя к получателю и времени движения отклика от получателя к отправителю). Если последнее условие нарушено, пропускная способность неизбежно понизится и будет определяться размером буфера, а не полосой пропускания канала.
- Длительность TCP-сессии больше нескольких RTT, чтобы оправдать используемую протокольную избыточность. Короткие ТСР-сессии, широко используемые WEB-технологией снижают эффективность обмена. (Именно это обстоятельство вынудило в версиях HTTPv1.1 и выше не разрывать ТСР-соединение после вызова очередной страницы).
- Чтобы минимизировать влияние избыточности, связанной с заголовком ( 20 байт IP +20 байт ТСР + МАС-заголовок ), используемое поле данных должно иметь большой объем. Для узкополосных каналов, где MTU мало, нарушение данного требования делает канал низкоэффективным. По этой причине выявление допустимого MTU в начале сессии должно приветствоваться.
- Взаимодействие с другими ТСР-сессиями не должно быть разрушительным, приводящим к резкому снижению эффективности виртуального канала.
Конечно, данные условия выполняются отнюдь не всегда, и система не рухнет, если эти условия нарушаются часто. Но эффективность работы соединения окажется не оптимальной. Примером ситуации, когда перечисленные условия нарушаются сразу по нескольким позициям, может служить мобильная IP-связь и работа через спутниковые каналы.
В тех случаях, когда поток данных расщепляется, должны предприниматься специальные меры по балансировке загрузки каналов.
Для прояснения модели работы протокола ТСР рассмотрим простой фрагмент сети, отображенный на рис. 2.9.
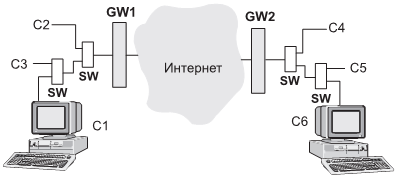
На данном рисунке ЭВМ С1С3 могут осуществлять обмен друг с другом и с ЭВМ С4С6. Переключатели SW работают на уровне L2 имеют буферы и могут быть причиной потерь, так же, как сами ЭВМ и маршрутизаторы GW1-GW2. Понятно, что объектом перегрузки, помимо названных устройств, может стать любой сетевой объект сети Интернет. Если устройства L3 при переполнении своего буфера могут послать отправителю пакета уведомление ICMP(4), то SW в общем случае могут этого и не делать (например, потому что не умеют). Причиной потери может быть и повреждение пакета на безбрежных просторах Интернет. Особые проблемы могут порождать каналы с большим произведением полосы на RTT [2.3]. В основных версиях протокола ТСР для подавления перегрузки используется механизм окон, который управляется потерей пакетов. В современных сетях передача данных, которая создает стационарный трафик, сосуществует с мультимедиа трафиком, который по своей природе нестабилен, что создает дополнительные проблемы для управления с применением оконных алгоритмов. Кроме того, мультимедийный трафик транспортируется обычно протоколом UDP, не предполагающим подтверждений доставки. Именно дейтаграммы UDP могут вызвать переполнение буфера, и об этом станет известно отправителю позднее, после регистрации потери ТСР сегмента.
Анализируя различные модели работы протокола ТСР, следует учитывать, что в сети Интернет могут встречаться участки с разными протоколами L2 (Ethernet, ATM, SDH, Frame Relay, PPP и т.д.). Эти технологии имеют разные алгоритмы обработки ситуаций перегрузки (или не имеют их вовсе), а отправитель и получатель, как правило, не имеют данных о том, какие протоколы уровня L2 реализуют виртуальное соединение (L4).
В настоящее время предложено и опробовано несколько разновидностей протокола TCP.
2.2.1.1. TCP-reno
В TCP-reno [17, 1990г; RFC-2581] при нормальной ситуации размер окна меняется циклически. Размер окна увеличивается до тех пор, пока не произойдет потеря сегмента. TCP-reno имеет две фазы изменения размера окна: фаза медленного старта и фаза избежания перегрузки. При получении отправителем подтверждения доставки в момент времени t + tA [сек] текущее значение размера окна перегрузки cwnd(t) преобразуется в cwnd(t + tA) согласно (1):
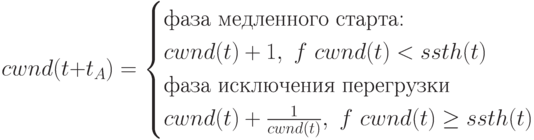 |
( 1) |
где ssth(t) [пакетов] - значение порога, при котором TCP переходит из фазы медленного старта в фазу исключения перегрузки. Когда в результате таймаута детектируется потеря пакета, значения cwnd(t) и ssth(t) обновляются следующим образом:
cwnd(t)=1; ssth(t)=(cwnd(t))/2;
С другой стороны, когда TCP детектирует потерю пакета согласно алгоритму быстрой повторной передачи, cwnd(t) и ssth(t) обновляются иначе:
ssth(t) = (cwnd(t))/2; cwnd(t)= ssth(t);
TCP-reno после этого переходит в фазу быстрого восстановления. В этой фазе размер окна увеличивается на один пакет, когда получается дублированное подтверждение. С другой стороны, cwnd(t) делается равным ssth(t), когда приходит недублированный отклик для пакета, посланного повторно. В случае таймаута ssth(t)= (cwnd(t))/2; cwnd=1 (смотри описание алгоритма TCP-Tahoe).
Результаты моделирования показывают, что каждое соединение обычно теряет около двух пакетов в каждом эпизоде перегрузки. Потери случаются, когда буфер полон и одно соединение увеличивает размер окна на единицу. Когда ячейки из этого нового пакета приходит в буфер, они обычно вызывают потерю ячеек, принадлежащих двум пакетам (конец пакета, пришедшего из другого соединения, и начало следующего). Итак, в среднем следует ожидать потерю трех пакетов на одно столкновение. В нашем примере двух соединений с RTT 40 мсек и 80 мсек, раз буфер полон и произошло столкновение, эпизод перегрузки длится 40 мсек. За время этого периода 80 мсек соединение увеличивает свое окно грубо 50% времени. То есть среднее число потерянных пакетов из-за этого увеличивается в 1.5 раза. Следовательно, всего 4.5 пакетов, или 2.25 пакетов на соединение теряется в среднем на один эпизод перегрузки.
В настоящее время наиболее популярной является модель NewReno, изложенная в документе RFC-3782 (апрель 2004 года), и использующая алгоритм Fast Retransmit & Fast Recovery (быстрая повторная пересылка и быстрое восстановление). В случае, когда доступна опция выборочного подтверждения (SACK), отправитель знает, какие пакеты следует переслать повторно на фазе быстрого восстановления (Fast Recovery). В отсутствие опции SACK нет достаточной информации относительно пакетов, которые нужно послать повторно. При получении трех дублированных подтверждений (DUPACK) отправитель считает пакет потерянным и посылает его повторно. После этого отправитель может получить дополнительные дублированные подтверждения, так как получатель осуществляет подтверждение пакетов, которые находятся в пути, когда отправитель перешел в режим Fast Retransmit. В случае потери нескольких пакетов из одного окна отправитель получает новые данные, когда приходит подтверждение для повторно посланных пакетов. Если потерян один пакет и не было смены порядка пакетов, тогда подтверждение этого пакета будет означать успешную доставку всех предыдущих пакетов до перехода в режим Fast Retransmit. Однако если потеряно несколько пакетов, тогда подтверждение повторно посланного пакета подтверждает доставку некоторых, но не всех пакетов, посланных до перехода в режим быстрой повторной пересылки (Fast Retransmit). Такие подтверждения называются частичными (смотри также http://www.acm.org/sigcomm/sigcomm96/ program.html).
Разработчики назвали алгоритм быстрого восстановления NewReno, так как он значительно отличается от базового алгоритма Reno, описанного в RFC-2581. Предложенный алгоритм дает определенные преимущества по сравнению с каноническим Reno при самых разных сценариях. Однако при одном сценарии канонический Reno превосходит NewReno - это происходит при изменении порядка следования пакетов.
Алгоритм NewReno использует переменную recover (восстановление), исходное значение которой равно исходному порядковому номеру пакета. Рассмотрим узловые этапы реализации алгоритма.
- Три задублированных ACK.
Когда отправителю приходят три задублированных ACK, а он не находится в состоянии Fast Recovery, проверяется, перекрывает ли поле Cumulative Acknowledgement больший диапазон, чем задано переменной recover. Если это так, то исполняется операция 1A. В противном случае - 1B.
1A) Запуск Fast Retransmit.
Если система находится в этом режиме, ssthresh делается равным значению не большему, чем задано уравнением 1. (Это уравнение 3 из [RFC-2581]).
ssthresh = max (FlightSize / 2, 2*SMSS) (1)
где FlightSize - объем доставляемых данных в сети. Кроме того, переменная recover делается равной наибольшему порядковому номеру переданного пакета, и осуществляется переход к пункту 2.
1B) Без быстрой повторной передачи.
Не производится вход в режим быстрой повторной передачи и быстрого восстановления. В частности, не изменяется ssthresh, не выполняется переход к пункту 2, чтобы передать потерянный сегмент, и не делается перехода к пункту 3 при последующих задублированных ACK.
- Вход в режим быстрой повторной передачи.
Передается потерянный сегмент и устанавливается cwnd равным ssthresh плюс 3*SMSS. Это искусственно увеличивает окно перегрузки на несколько сегментов (три), которые покинули сеть и буферизованы получателем (SMSS - MSS отправителя).
- Быстрое восстановление.
Для каждого нового дублированного ACK, полученного в режиме быстрого восстановления, cwnd увеличивается на SMSS. Это искусственно увеличивает окно перегрузки, чтобы учесть сегмент, который покинул сеть.
- Быстрое восстановление, продолжение.
Сегмент передается, если это разрешено новым значением cwnd и значением window, объявленным получателем.
- Когда приходит ACK, подтверждающий получение новых данных, это ACK может быть подтверждением, связанным с повторной передачей во время этапа 2 или с более поздней повторной передачей.
Полное подтверждение.
Если ACK подтверждает все данные вплоть до позиции, указанной переменной recover, тогда ACK подтверждает получение промежуточных сегментов, начиная с передачи потерянного сегмента и получения тройного дублированного ACK. cwnd устанавливается либо (1) min (ssthresh, FlightSize + SMSS) либо (2) ssthresh, где ssthresh равно значению, установленному на этапе 1; это называется снижением ("сдутием") значения окна. Заметим, что FlightSize ( FlightSize - объем посланных, но еще не подтвержденных данных) на этапе 1 относится к объему данных, не доставленных на этапе 1, когда произошел переход в режим быстрого восстановления, в то время как FlightSize на этапе 5 относится к объему данных, не доставленных на этапе 5, когда произошел выход из режима быстрого восстановления. Если выбрана вторая опция, реализации разрешено принять меры, чтобы избежать возможного всплеска информационного потока, в случае, когда объем недоставленных данных в сети много меньше, чем допускает окно перегрузки. Простым механизмом является ограничение числа информационных пакетов, которые могут быть посланы в ответ на одно подтверждение; это в программе моделирования NS называется "maxburst_".
Частичное подтверждение.
Если это ACK в действительности не подтверждает доставку всех данных вплоть до позиции, заданной recover включительно, тогда это частичное ACK. В этом случае передается первый неподтвержденный сегмент. Снижается значение окна перегрузки с учетом объема новых данных, подтвержденных с использованием поля группового подтверждения. Если частичное ACK подтверждает как минимум один SMSS данных, тогда к окну перегрузки добавляется SMSS байт. Так же, как на этапе 3, это искусственно увеличивает окно перегрузки, чтобы учесть сегмент, который покинул сеть. Посылается новый сегмент, если это разрешено новым значением cwnd. Это "частичное сокращение окна" пытается гарантировать, что, когда режим быстрого восстановления в конце концов завершится, объем недоставленных данных будет примерно равен ssthresh. Выхода из режима быстрого восстановления не производится (т.e., если позднее придет какой--либо задублированный ACK, выполняются шаги 3 и 4).
Для первого частичного ACK, который приходит во время реализации быстрого восстановления, сбрасывается таймер повторной передачи.
- Таймауты повторной передачи.
После таймаута RTO в переменную recover записывается наибольший порядковый номер переданного сегмента и производится выход из режима быстрого восстановления, если это возможно.
Этап 1 специфицирует проверку того, что поле кумулятивного подтверждения покрывает больший диапазон, чем это задано переменной recover. Так как поле подтверждения содержит порядковый номер, который получатель ожидает получить, "ack_number" подтверждения покрывает больший диапазон номеров, чем recover, когда:
ack_number - 1 > recover;
т.e. получено подтверждение, по крайней мере, на один байт данных больше, чем наибольший байт из недоставленных данных, с момента последнего входа в режим быстрой повторной отправки.
Возможным вариантом реакции на частичные подтверждения может быть сброс таймера повторной передачи после частичного подтверждения. В этом случае, если в пределах окна потеряно большое число пакетов, таймер повторной передачи TCP-отправителя выдает таймаут, а отправитель данных запускает процедуру медленного старта.
Одной из возможностей получения оптимального алгоритма в случае множественных потерь пакетов является схема, подобная медленному старту, когда осуществляется сброс таймера повторной посылки при каждом частичном подтверждении. Следует заметить, что существует определенное ограничение эффективности в случае, если не поддерживается опция SACK.
Другим вариантом реакции на частичное подтверждение может быть повторная посылка более чем одного пакета и сброс таймера повторной пересылки после повторной передачи. В случае множественных потерь пакетов повторная посылка двух пакетов при получении частичного подтверждения обеспечивает более быстрое восстановление системы. Такой подход требует меньше времени, чем N RTT в случае потери N пакетов. Однако при отсутствии опции SACK медленный старт обеспечивает достаточно быстрое восстановление системы без пересылки лишних пакетов.
TCP отправитель реагирует на частичные ACK сокращением окна перегрузки на величину, соответствующую объему подтвержденных данных, возвращая назад SMSS байт, если частичное ACK подтверждает, по крайней мере, SMSS байт новых данных, и посылая новый сегмент, если это допускается новым значением cwnd. Таким образом, посылается только один отправленный ранее пакет в ответ на каждое частичное подтверждение, но могут быть посланы и новые пакеты, в зависимости от объема подтвержденной частично доставки. Напротив, в варианте NewReno, описанном в (Fall, K. and S. Floyd, "Simulationbased Comparisons of Tahoe, Reno and SACK TCP", Computer Communication Review, July 1996. URL ftp://ftp.ee.lbl.gov/papers/sacks.ps.Z), в случае частичного подтверждения устанавливается значение окна перегрузки, равное ssthresh. Такой подход является более консервативным, и не пытается точно определить число недоставленных пакетов после получения частичного подтверждения.
В отсутствии опции SACK или временных меток задублированные подтверждения не несут какой--либо информации, позволяющей идентифицировать информационные пакеты, которые вызвали задублированные подтверждения. В этом случае отправитель TCP данных не может отличить задублированные подтверждения, вызванные потерей или задержкой пакетов, от дублированных ACK, связанных с повторно посланными информационными пакетами, которые уже получены адресатом.
Проблемы оптимальности для алгоритмов быстрого восстановления и быстрой повторной пересылки в Reno TCP, связанные с множественными быстрыми повторными пересылками, относительно проще по сравнению с аналогичными проблемами в случае алгоритма Tahoe TCP, который не использует быстрого восстановления. Несмотря ни на что, ненужные быстрые повторные пересылки могут произойти в Reno TCP, если не использовать дополнительные механизмы, связанные с применением переменной recover.
Алгоритм, описанный в RFC-3782, соответствует варианту Careful алгоритма NewReno TCP из RFC-2582 и исключает проблему множественных повторных пересылок. Этот алгоритм использует переменную recover, значение которой соответствует исходному порядковому номеру посланного пакета. После каждого таймаута повторной передачи, наибольший порядковый номер переданного пакета записывается в переменную recover.
Если после таймаута повторной передачи отправитель TCP повторно пошлет пакеты, уже полученные адресатом, то отправитель получит три задублированных отклика, которые перекроют диапазон, заданный переменной recover. В этом случае задублированные ACK не указывают на случай перегрузки. Они просто сообщают, что отправитель повторно послал, по крайней мере, три пакета.
Однако когда повторно посланные пакеты сами теряются, отправитель может получить три задублированные отклика, которые перекрывают меньший диапазон, чем определяется переменной recover. Для протокола TCP, который использует рассмотренный здесь алгоритм, отправитель в данном сценарии не предполагает, что потерянный пакет сопряжен с одним из задублированных подтверждений.
Существует несколько эвристических подходов, основанных на временных метках или на преимуществах поля кумулятивных (групповых) подтверждений, которые отправитель в некоторых случаях использует, чтобы различить случаи с тремя задублированными ACK, следующие за повторно посланным пакетом, который был потерян, и тремя задублированными подтверждениями, сопряженными с откликами на повторно посланные по ошибке сегментами. Отправитель может использовать эвристику, чтобы решить, следует ли запускать режим быстрой повторной передачи, даже если задублированные ACK не перекрывают диапазон номеров, определенный переменной recover.