| Россия |
Опубликован: 30.04.2008 | Уровень: специалист | Доступ: свободно | ВУЗ: Московский государственный университет имени М.В.Ломоносова
Лекция 12:
Обучение по прецедентам (по Вапнику, Червоненкису)
Аннотация: Материалы данной лекции включают в себя обучение по прецедентам (по Вапнику, Червоненкису), а также основные теоремы и определения, применимые для классификаторов
Ключевые слова: метрика, мера, вероятность, класс, параметр, функция, величина риска, эмпирический риск, значение, место, сходимость, случайная величина, дисперсия, множества, энтропия, классификатор, подмножество, очередь, максимум, размерность, длина
12.1. Задача построения классификатора
Пусть
-
 – пространство образов,
– пространство образов, -
 – признаковое пространство,
– признаковое пространство, -
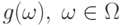 – индикаторная функция,
– индикаторная функция, -
 – множество признаков.
– множество признаков.
Тогда 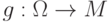 .
.
Пусть также
-
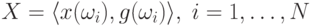 – множество прецедентов,
– множество прецедентов, -
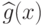 – решающее правило.
– решающее правило.
Тогда 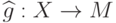
Выбор решающего правила исходит из минимизации 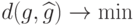 ,
где
,
где  – метрика, мера близости функций
– метрика, мера близости функций 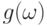 и
и 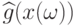 .
Построение
.
Построение 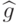 называют задачей обучения. – это ученик,
процедура формирования – это учитель, прецеденты – это обучающая последовательность.
называют задачей обучения. – это ученик,
процедура формирования – это учитель, прецеденты – это обучающая последовательность.
12.2. Качество обучения классификатора
Относительная доля несовпадений классификации с учителем для
решающего правила есть:  , где
, где  .
Надежность обучения классификатора – это вероятность получения решающего правила с заданным качеством.
.
Надежность обучения классификатора – это вероятность получения решающего правила с заданным качеством.
Пусть  – класс дискриминантных функций,
где
– класс дискриминантных функций,
где 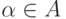 – параметр. Число степеней свободы при
выборе конкретной функции в классе определяется количеством
параметров в векторе
– параметр. Число степеней свободы при
выборе конкретной функции в классе определяется количеством
параметров в векторе  , т.е. размерностью
, т.е. размерностью  .
.
Например, для классов линейных и квадратичных функций имеем:
Линейная дискриминантная функция:  .
В таком случае имеем
.
В таком случае имеем  степень свободы.
степень свободы.
Квадратичная дискриминантная функция: 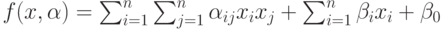 .
В таком случае имеем
.
В таком случае имеем 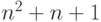 степеней свободы.
степеней свободы.
С увеличением степеней свободы увеличивается способность классификатора по разделению.
12.3. Вероятностная модель
Пусть прецеденты – это результат реализации случайных величин. Рассмотрим величину риска (т.е. ошибки) связанной с классификацией. Определим понятия риск среднего и риска эмпирического.
Пусть на заданы 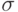 -алгебра и мера
-алгебра и мера 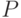 .
Пусть также
.
Пусть также
-
 – вектор признаков,
– вектор признаков, -
 – класс функций, из которых выбирается решающее правило,
– класс функций, из которых выбирается решающее правило, -
– решающее правило (результат классификации), которое принимает значение 0 или 1 при фиксированном векторе параметра,
-
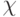 – характеристическая функция множества,
– характеристическая функция множества, -
– множество параметров, описывающие различные функции в .
Тогда 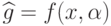 , где
, где  и
и 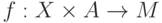 ,
,  .
.
В данных обозначениях средний риск выглядит следующим образом:

Для случая двух классов, при 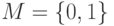 , имеем:
, имеем:
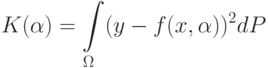
 – это вероятностная мера на пространстве .
– это вероятностная мера на пространстве .12.4. Задача поиска наилучшего классификатора
Рассмотрим минимизацию функционала:
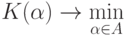
Задача же поиска наилучшего классификатора состоит в нахождении 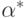 такого, что
такого, что
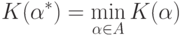
Если же минимума не существует, то надо найти такое, что
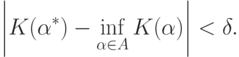
Другими словами, необходимо решить задачу минимизации среднего риска.
Поскольку неизвестно, будем решать задачу минимизации
эмпирического риска. Пусть  – число прецедентов. Тогда эмпирический
риск задается выражением:
– число прецедентов. Тогда эмпирический
риск задается выражением:
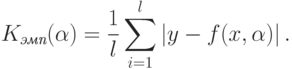
Таким образом, задача минимизации эмпирического риска выглядит так:
 – любой возможный параметр.
– любой возможный параметр.В идеале надо получить взаимосвязанные оценки эмпирического и среднего риска.
Отметим, что чем меньше , тем легче построить такую,
что  обращается в ноль, либо очень мало. Но при этом истинное
значение
обращается в ноль, либо очень мало. Но при этом истинное
значение  может сильно отличаться от .
Необходимо выбрать такую, чтобы имела
место равномерная сходимость по выражения:
может сильно отличаться от .
Необходимо выбрать такую, чтобы имела
место равномерная сходимость по выражения:
![P
\left\{
\sup_{\alpha}
\left|
K_{\textit{эмп}}(\alpha)-K(\alpha)
\right|
>\varepsilon
\right\}
\xrightarrow[l\rightarrow\infty]{\phantom{0}} 0.](/sites/default/files/tex_cache/aa6f765795f81ef44d2c15efa65ebca3.png)
Фактически это есть сходимость частот к математическому ожиданию.
В дальнейшем будем считать, что в зависимости от конкретного
набора прецедентов можем получить любые . Но необходимо, чтобы
полученные эмпирическое решающее хорошо работало (отражало общие
свойства) для всех образов. Поэтому в формуле присутствует равномерная
сходимость.