Опубликован: 18.05.2006 | Уровень: для всех | Доступ: свободно | ВУЗ: Ульяновский государственный университет
Лекция 11:
Параллельные системы
Классы параллельных систем
I. Векторно-конвейерные компьютеры (PVP). Имеют MIMD-архитектуру (множество инструкций над множеством данных).
Основные особенности:
- конвейерные функциональные устройства;
- набор векторных инструкций в системе команд;
- зацепление команд (используется как средство ускорения вычислений).
Характерным представителем данного направления является семейство векторно-конвейерных компьютеров CRAY.
Рассмотрим, например, суперкомпьютер CRAY Y-MP C90, имеющий следующие характеристики:
- Максимальная конфигурация - 16 процессоров, время такта - 4,1 нс, что соответствует тактовой частоте почти 250 МГц.
- Разделяемые ресурсы процессора:
- Оперативная память (ОП) разделяется всеми процессорами и секцией ввода/вывода, разделена на множество банков, которые могут работать одновременно.
- Секция ввода/вывода. Компьютер поддерживает три типа каналов с разной скоростью передачи:
Low-Speed Channels - 6 Мбайт/с
- Секция межпроцессорного взаимодействия содержит регистры и семафоры, предназначенные для передачи данных и управляющей информации.
- Вычислительная секция процессора состоит из:
- регистров (адресных, скалярных, векторных);
- функциональных устройств;
- сети коммуникаций.
- Секция управления.
Команды выбираются из ОП блоками и заносятся в буфера команд.
- Параллельное выполнение программ.
Все основные операции, выполняемые процессором - обращение в память, обработка команд и выполнение инструкций - являются конвейерными.
II. Массивно-параллельные компьютеры с распределенной памятью. Объединяется несколько серийных микропроцессоров, каждый со своей локальной памятью, посредством некоторой коммуникационной среды.
Достоинств у такой архитектуры много: если нужна высокая производительность, то можно добавить еще процессоров; если ограничены финансы или заранее известна требуемая вычислительная мощность, то легко подобрать оптимальную конфигурацию и т.д.
Каждый процессор имеет доступ лишь к своей локальной памяти, а если программе нужно узнать значение переменной, расположенной в памяти другого процессора, то задействуется механизм передачи сообщений. Этот подход позволяет создавать компьютеры, включающие в себя тысячи процессоров.
Но эта архитектура имеет 2 существенных недостатка:
- требуется быстродействующее коммуникационное оборудование, обеспечивающее среду передачи сообщений;
- при создании программ необходимо учитывать топологию системы и специальным образом распределять данные между процессорами, чтобы минимизировать число пересылок и объем пересылаемых данных.
Последнее обстоятельство и мешает широкому внедрению подобных архитектур.
К данному классу можно отнести компьютеры Intel Paragon, IBM SP1, Parsytec, IBM SP2 и CRAY T3D.
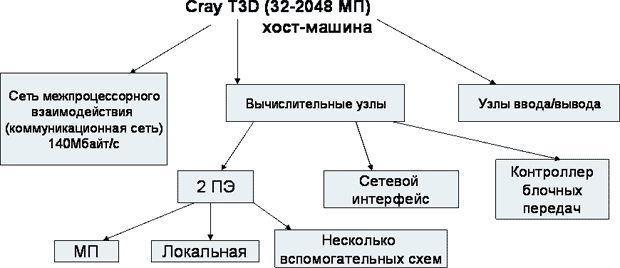
Компьютеры Cray T3D и T3E используют единое адресное пространство (общая виртуальная память) (см. рис. 11.1). По аппаратному прерыванию особого случая адресации ОС выполняет пересылку страницы с одного узла на другой. У каждого МП своя локальная память, но единое виртуальное адресное пространство.
Факторы, снижающие производительность параллельных компьютеров:
-
Закон Амдала.
В табл. 11.1 показано, на какое максимальное ускорение работы программы можно рассчитывать в зависимости от доли последовательных вычислений и числа доступных процессоров.
- Время инициализации посылки сообщения (латентность) и время передачи сообщения по сети.
Максимальная скорость передачи достигается на больших сообщениях, когда латентность, возникающая лишь вначале, не столь заметна на фоне непосредственно передачи данных.
- Возможность асинхронной посылки сообщений и вычислений.
Если или аппаратура, или программное обеспечение не поддерживают возможности проводить вычисления на фоне пересылок, то возникнут неизбежные накладные расходы, связанные с ожиданием полного завершения взаимодействия параллельных процессов.
- Неравномерная загрузка всех процессорных элементов.
Если равномерности нет, то часть процессоров будут простаивать, ожидая остальных, хотя в этот момент они могли бы выполнять полезную работу.
- Время ожидания прихода сообщения.
Для его минимизации необходимо, чтобы один процесс отправил требуемые данные как можно раньше, отложив независящую от них работу на потом, а другой процесс выполнил максимум работы, не требующей ожидаемой передачи, прежде чем выходить на точку приема сообщения.
- Реальная производительность одного процессора.
III. Параллельные компьютеры с общей памятью (SMP). Вся оперативная память разделяется между несколькими одинаковыми процессорами. Это снимает проблемы предыдущего класса, но добавляет новые - число процессоров, имеющих доступ к общей памяти, нельзя сделать большим. В данное направление входят многие современные многопроцессорные SMP-компьютеры или, например, отдельные узлы компьютеров HP Exemplar и Sun StarFire.
Основное преимущество таких компьютеров - относительная простота программирования. В ситуации, когда все процессоры имеют одинаково быстрый доступ к общей памяти, вопрос о том, какой процессор какие вычисления будет выполнять, не столь принципиален, и значительная часть вычислительных алгоритмов, разработанных для последовательных компьютеров, может быть ускорена с помощью распараллеливающих и векторизирующих трансляторов. SMP-компьютеры - это наиболее распространенные сейчас параллельные вычислители. Однако общее число процессоров в SMP-системах, как правило, не превышает 16, а их дальнейшее увеличение не дает выигрыша из-за конфликтов при обращении к памяти.
IV. Кластерная архитектура. По такому принципу построены CRAY SV1, HP Exemplar, Sun StarFire, NEC SX-5, последние модели IBM SP2 и другие.
Кластерная архитектура представляет собой комбинации предыдущих трех. Из нескольких процессоров (традиционных или векторно-конвейерных) и общей для них памяти формируется вычислительный узел. Если полученной вычислительной мощности не достаточно, то объединяется несколько узлов высокоскоростными каналами. Часто создаются из общедоступных компьютеров на базе Intel и недорогих Ethernet-сетей под управлением операционной системы Linux.