Создание и использование индексов
Неуникальные индексы
Неуникальный индекс действует так же, как уникальный индекс, за исключением того, что он может содержать дублированные значения в узлах-листьях. Все дублированные значения будут считываться, если они отвечают критерию, указанному в операторе SELECT.
Неуникальный индекс не столь эффективен, как уникальный индекс, поскольку для считывания запрошенных данных он требует дополнительной обработки (дополнительных операций ввода-вывода). Но некоторые приложения требуют использования дублированных ключей, поэтому иногда нет возможности создания уникального индекса. В некоторых случаях использовать неуникальный индекс лучше, чем вообще не использовать никакого индекса.
Типы индексов
Существует два типа индексов B-деревьев: кластеризованные индексы и некластеризованные индексы. Кластеризованный индекс хранит в своих узлах-листьях реальные строки данных. Некластеризованный индекс является вспомогательной структурой, которая указывает данные в таблице. В этом разделе мы рассмотрим отличия между этими двумя типами индексов. В этом разделе вы также ознакомитесь с полнотекстовым индексом, который является скорее каталогом, чем индексом.
Кластеризованные индексы
Как уже говорилось, кластеризованный индекс – это индекс в виде B-дерева, где хранятся реальные строки данных таблицы в отсортированном порядке в узлах-листьях (рис. 17.6). Эта система дает несколько преимуществ и имеет несколько недостатков.
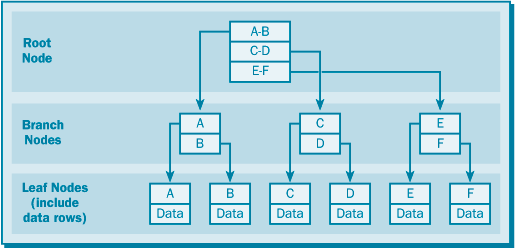
Поскольку данные кластеризованного индекса хранятся в узлах-листьях, то данные становятся доступны, как только найден определенный узел-лист, что может сокращать количество операций ввода-вывода. Любое сокращение числа этих операций повышает производительность отдельных операций и системы в целом.
Еще одним преимуществом кластеризованных индексов является то, что считываемые данные получаются в отсортированном по индексу виде. Например, если кластеризованный индекс создан по колонкам state, country и city и в запросе происходит выбор данных для значения Texas колонки state, то результирующий набор будет отсортирован по колонкам country и city в том порядке, как определен индекс. Эту возможность можно использовать, чтобы избежать ненужных операций сортировки, если приложение и база данных организованы соответствующим образом. Например, если вы знаете, что вам всегда требуется сортировка данных в определенном порядке, то использование кластеризованного индекса означает, что вам не потребуется выполнять сортировку после считывания данных.
Недостатком использования кластеризованного индекса является то, что доступ к таблице всегда происходит через индекс, что может приводить к дополнительной нагрузке на систему. SQL Server начинает доступ к данным в корневом узле и проходит через индекс, пока не будет достигнут узел-лист, содержащий нужные данные. Если из-за большого объема данных создается много узлов-листьев, то количество уровней индекса, необходимых для поддержки столь большого числа узлов-листьев, тоже становится большим, что увеличивает количество операций ввода-вывода, необходимых для перемещения от корневого узла к узлу-листу.
Поскольку в кластеризованном индексе хранятся реальные данные, вы не можете создать более одного кластеризованного индекса по таблице. С другой стороны, вы можете создать некластеризованный индекс по кластеризованной таблице. (Кластеризованная таблица – это просто таблица, имеющая кластеризованный индекс.) Вам следует создавать кластеризованный индекс, используя индексные ключи, к которым наиболее часто осуществляется доступ: это даст вам наибольшую вероятность доступа к данным через кластеризованный индекс и, тем самым, наиболее высокую производительность.
Некластеризованные индексы
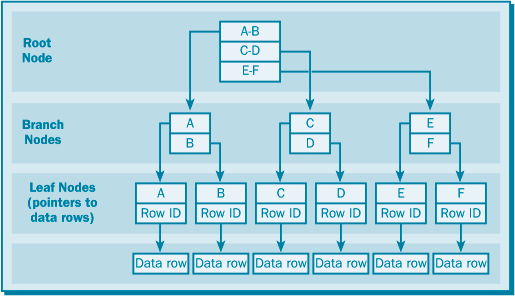
В отличие от кластеризованного индекса некластеризованный индекс не содержит реальных данных таблицы в своих узлах-листьях. Узлы-листья могут содержать один из двух типов информации о местоположении строк данных. Во-первых, если по таблице не создан кластеризованный индекс, то некластеризованные индексы по этой таблице хранят в своих узлах-листьях идентификаторы строк (Row ID) (рис. 17.7). Каждый идентификатор строки указывает реальную строку данных в таблице. Идентификатор строки – это значение, включающее в себя номер файла данных, номер страницы и местоположение строки на этой странице. Это значение обеспечивает быстрый доступ к реальным данным, указывая точное местоположение этих данных.
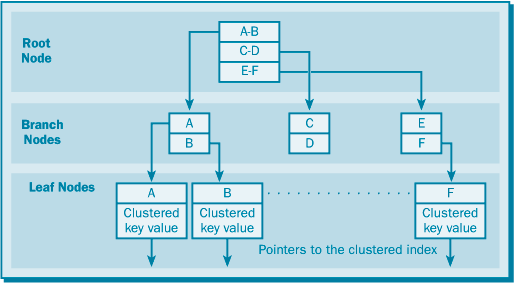
Если по таблице создан кластеризованный индекс, то некластеризованные индексы будут содержать в узле-листе значение ключа кластеризованного индекса для этих данных (рис. 17.8). При достижении узла-листа некластеризованного индекса находящееся в нем значение кластеризованного ключа используется для поиска в кластеризованном индексе, соответствующий узел-лист которого содержит искомую строку данных.
Как уже говорилось, каждая таблица может иметь только один кластеризованный индекс. Вы можете создать 249 некластеризованных индексов на одну таблицу, но это было бы неразумно (см. раздел "Рекомендации по использованию индексов"). Обычно на практике используется несколько некластеризованных индексов по различным колонкам таблицам. Чтобы определить, какой индекс использовать, оптимизатор запросов использует предикат в предложении WHERE.
Полнотекстовые индексы
Как уже говорилось, полнотекстовый индекс SQL Server на самом деле больше похож на каталог, чем на индекс, и он имеет структуру, отличную от B-дерева. Полнотекстовый индекс позволяет выполнять поиск по группам ключевых слов. Полнотекстовый индекс является частью службы Microsoft Search; он широко используется в механизмах поиска Wеb-узлов и других текстовых операциях.
В отличие от индексов, имеющих структуру B-дерева, полнотекстовый индекс хранится вне базы данных, но поддерживается базой данных. Ввиду своего внешнего хранения этот индекс может поддерживать свою собственную структуру. К полнотекстовым индексам относятся следующие ограничения:
- Полнотекстовый индекс должен иметь колонку, которая уникальным образом идентифицирует каждую строку таблицы.
- Полнотекстовый индекс должен также содержать одну или несколько колонок символьных строк таблицы.
- Для каждой таблицы может существовать только один полнотекстовый индекс.
- Полнотекстовый индекс не обновляется автоматически, как это происходит с индексами, имеющими структуру B-дерева. В индексе со структурой B-дерева операции вставки, обновления или удаления вызывают также обновление индекса. В случае полнотекстового индекса эти операции по таблице не приводят к автоматическому обновлению этого индекса. Для обновлений следует задавать расписание или выполнять их вручную.
Полнотекстовый индекс имеет массу возможностей, которых нет в индексах со структурой B-дерева. Поскольку этот индекс используется как механизм текстового поиска, он поддерживает больше возможностей текстового поиска, чем стандартные механизмы. Используя полнотекстовый индекс, вы можете выполнять поиск слов или фраз, отдельных слов или групп слов, а также похожих слов. (О том, как создавать полнотекстовый индекс см. раздел "Использование мастера Full-Text Indexing Wizard" далее.)