Опубликован: 31.07.2008 | Уровень: специалист | Доступ: свободно
Лекция 3:
Алгоритмы отдельных функций, выполняемые в станциях с программным управлением
Декодирование, анализ номера и выбор направлений
Структурная схема этого алгоритма показана на рис. 3.11.

На вход поступает информация, которая должна быть преобразована в другую форму. Пересчет одного числа или набора чисел в другие — довольно распространенная в коммутационной технике операция. В частности, она обусловлена многозначностью системы нумерации одного и того же прибора на телефонной станции. Например, абонентский комплект может иметь следующие номера:
- списочный — зафиксированный в абонентском справочнике и поступающий на АТС при наборе номера абонента;
- позиционный — номер места включения этого АК в коммутационном поле;
- порядковый — тип комплекта и номер в типе;
- по вводу — номер линейки определителя;
- по выводу — номер линейки управляющего устройства, в которое включены исполнительные элементы;
- зоны памяти — номер области, в которой хранятся данные о комплекте.
В процессе установления соединения все эти номера могут пересчитываться один в другой. При разработке АТС всегда стараются упорядочить связь между нумерациями. Наличие закона при таком переходе значительно экономит ресурсы, но, к сожалению, чаще всего такой закон отсутствует.
Очень простым алгоритмом пересчета является одноступенчатая дешифрация с помощью таблицы, когда каждому исходному номеру, подлежащему пересчету, отводится одна строка таблицы, в которую записывается соответствующий номер в другой системе нумерации.
Такой пример показан на рис. 3.12а. Этот дешифратор предназначен для определения порядкового номера абонентского комплекта. Каждой строке сопоставляется списочный номер (например, 512546 ), в который записан соответствующий порядковый номер абонентского комплекта (в данном случае АК-1).
Существенное влияние на алгоритмы дешифрации оказывают требования наращивания станции в процессе эксплуатации. Для удобства расширения станции в процессе эксплуатации часто вводится двухступенчатая или многоступенчатая адресация (см. рис. 3.12б).
На современных сетях с узлообразованием число возможных комбинаций первых цифр абонентского номера значительно превышает число направлений с каждой станции. Каждую АТС можно включить в узел исходящего сообщения. При этом внешние связи идут только через узел. Таким образом, число внешних направлений равно 1, и если номер абонента сети содержит 6-7 знаков, то одноступенчатая нумерация приведет к огромному объему неэффективно используемой памяти.
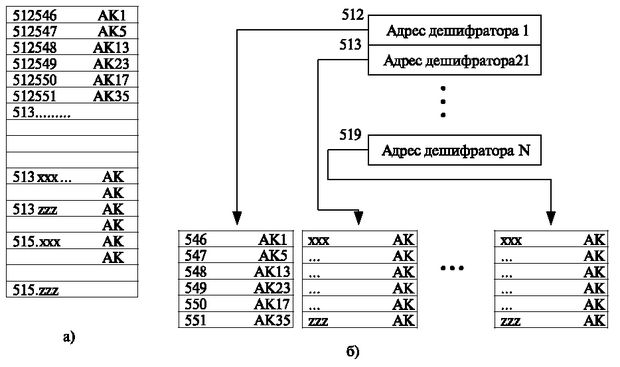
Рис. 3.12. Области памяти алгоритма декодирования а) организация памяти при прямом пересчете; б) при двухступенчатом пересчете
Учитывая вышесказанное, для уменьшения объема пересчета можно применить последовательный принцип анализа. При этом способе последовательно анализируется каждая отдельная цифра.
Результаты такого анализа могут быть следующими:
- данное число цифр (в том числе и одна цифра) достаточно для пересчета направления;
- анализ направлений должен быть продолжен с использованием того же числа цифр;
- необходимо продолжить анализ с добавлением для анализа еще одной цифры.
Для алгоритма, реализующего этот способ, организуются массивы памяти анализа первой, второй третьей и т. д. цифр номера (рис. 3.13). Каждая зона массива памяти содержит два слова (на рис. 3.13 показаны только зоны массива первых цифр). Первое слово заключает в себе эталон, с которым будет сравниваться i – цифра номера, и адрес (A1, A2, ..., An) очередного слова зоны массива первых цифр. В этой зоне находится другой эталон, сравнение с которым осуществляется в случае, если предыдущий эталон совпал с i -цифрой номера. Если такое совпадение произошло, во втором слове может содержаться один из двух видов информации: номер направлений или адрес массива следующей (i +1) -цифры, с эталонами которого надо последовательно сравнить эту цифру.
Эталон представляет собой десятиразрядное слово с информацией, записанной позиционно. Напомним, что в позиционном коде каждой цифре от 0 до 9 соответствует один двоичный разряд, единичное значение которого свидетельствует о наличии этой цифры в слове.
Модуль, реализующий этот алгоритм, использует в качестве входных данных заявки от алгоритма приема номера (адреса зоны, где накоплены цифры). Результатом его работы является номер направления.
Алгоритм настраивается (см. рис. 3.13) на основе таблиц, списочных номеров и соответствующих им направлений. Он осуществляет ряд следующих действий (рис. 3.14). Начинается алгоритм с чтения заявки. Затем устанавливается индекс i = 0 (оператор 2), соответствующий первой цифре номера. Далее эта цифра читается (оператор 3) и декодируется в позиционный номер (оператор 4), после чего читается эталон ( Эi ) — (оператор 5) и побитно проверяется на совпадение (оператор 6) с позиционным значением номера ( N ).

увеличить изображение
Рис. 3.13. Массивы алгоритма последовательного анализа цифр. A1, A2,…. An – адреса, по которым осуществляется переход при несвовпадении цифры и эталона; B1, B2,….Bm — направления или адреса , по которым возможен переход в зону (i+1) – й цифры; g – признак трактовки поля B – переход по адресу, либо окончание поиска направления

Если получено совпадение позиционного номера и эталона, то проверяется признак во втором слове эталона (оператор 8). Значение g = 0 говорит о том, что в этом слове записан номер направления, который вносится в рабочую ячейку (оператор 9) и является результатом работы алгоритма.
Если цифра не совпала с эталоном, то читается из первого слова эталона адрес зоны и эталона, размещенного в этой зоне (оператор 7), и процесс повторяется.
При совпадении цифры с эталоном и при g = 1 читается следующая цифра, и эталон вторых цифр, адрес которого указан во втором слове зоны ( i:=i+1 оператор 12). При этом проверяется, не превосходит ли индекс (i + 1) (оператор 13) заданное на сети число цифр. Если не превосходит, читается следующая цифра и процесс повторяется. В противном случае отмечается, что набранный номер соответствует несуществующему направлению (оператор 14).
Рассмотрим конкретный пример. На рис. 3.15 показаны сетевые соединения станции, обозначенной цифрой 1. От нее к другим АТС имеется шесть направлений, обозначенных шестизначными номерами. Первые два направления характеризуются одним знаком, одно направление — двумя знаками, остальные три — тремя знаками.

Далее на рис. 3.16 показаны зоны памяти, соответствующие данной сети.

По адресу 1 в эталоне значением 1 отмечены позиции 5 и 6, соответствующие первому направлению. Номер данного направления записан во втором слове ( g=0 ). В правой части первого слова содержится адрес второй зоны (адрес 2), используемый при несовпадении цифр с эталоном. Значением 1 в эталоне адреса 2 отмечены позиции 7 и 8, соответствующие второму направлению. Признак g = 1 в слове с адресом 3 указывает, что в случае совпадения позиционного номера цифры и хотя бы одного разряда эталона нужно перейти в эталон массива вторых цифр по адресу 5. Такой переход диктуется тем, что первая цифра со значением 1 не дает возможности определить направление, поскольку четыре направления (с третьего по шестое) характеризуются номерами, начинающимися с 1 (см. рис. 2.12). В конце каждого массива цифр стоит эталон, содержащий все единицы.
Он гарантирует, что цифры, не пересчитанные в номер направления или не переадресованные к другим ячейкам, не приведут станцию в тупиковую ситуацию. Таким цифрам приписывается индекс "Несуществующее направление". Действия для подобных исходных данных уже отображены в общем алгоритме анализа (рис. 3.14).
Взаимодействие с центральным алгоритмом заключается в запуске в работу этого алгоритма с указанием места информации, которая подлежит декодированию. Наиболее массовый случай — пересчет набранного номера в номер направления установления соединения. В этом случае дается заявка с указанием области памяти процесса, где находится информация, и указанием места, в которое следует записать номер найденного направления.