
| Казахстан |
Опубликован: 24.12.2013 | Уровень: для всех | Доступ: свободно | ВУЗ: Кубанский государственный университет
Лекция 11:
Хранение данных и доступ к ним
11.3.3 Индексы битовой карты
Побитовые (BitMapped) индексы это разновидность неуникальных индексов. Побитовые индексы предназначены в первую очередь для работы с хранилищами данных. Эффективны они при малой разрешающей способности столбца. Функционально битовый индекс идентичен обычному древесному индексу, хотя внутреннее их устройство различно. Сами битовые индексы хранятся в виде B*-структуры.
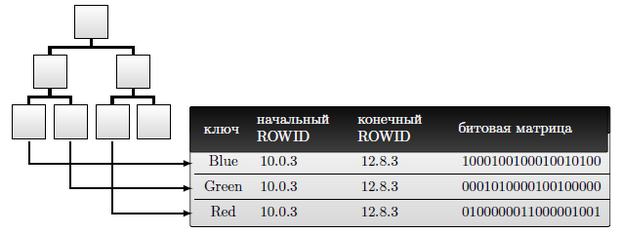
Структура строки битового индекса в Oracle (рисунок 11.5): (<зна-чение_ключа, начальное_значение_rowid, конечное_значение_rowid, сег-мент_двоичной_карты>). где:
- начальное и конечное значения rowid указывает диапазон строк в таблице с конкретным значением ключа
- сегмент битовой карты — это длинное битовое поле; установка бита в 1 означает наличие значения, а в 0 — на отсутствие значения ключа.
Сравним индексы. Пара <значение ключа, rowid> в B*-индексе заменена парой <значение ключа, сегмент двоичной карты>, где "значение_ключа" состоит из колонок "значение_ключа", "начало_rowid" и "конец_rowid". Битовые индексы, как и древесные, могут быть конкатенироваными.
Операции с индексами битовой карты могут выполняться очень быстро, так как логические операции над битовыми матрицами транслируются непосредственно в команды центрального процессора, выполняющие побитовые операции над словами длиной 32 или 64 бита.
Рассмотрим пример выполнения операции поиска в группе из 14-ти человек сильных программистов высокого роста.
Пример битовой карты приведен в таблицах 11.2 и 11.3.
| Значение признака "Рост" | Строка таблицы |
|---|---|
| Низкий | 10000011010000 |
| Средний | 01100000000101 |
| Высокий | 00011100101010 |
| Значение признака "Сила" | Строка таблицы |
|---|---|
| Недостаточная | 00000001000000 |
| Нормальная | 01101110000101 |
| Большая | 10010000111010 |
Тогда запрос "Найти сильных программистов высокого роста" оформляется как обычно:
SELECT фамилия FROM программисты WHERE Рост = 'Высокий' AND Сила = 'Большая'
В действительности сначала будет выполнено побитное И над битовыми картами для полей Рост и Сила (таблица 11.4).
| Высокий | 0 0 0 1 1 1 0 0 1 0 1 0 1 0 |
| Большая | 1 0 0 1 0 0 0 0 1 1 1 0 1 0 |
| Выбранные строки | 0 0 0 1 0 0 0 0 1 0 1 0 1 0 |
Подходят 4-я, 9-я, 11-я и 13-я строки. Они и будут выбраны.
11.3.4 Замечание о других индексах
Вспомним, что В*-индексы строятся в предположении возможности линейной упорядоченности значений столбца.
В многомерных данных линейное упорядочение не возможно. Данные, представленные набором гиперкубов, применяются в хранилищах, на которых построены системы поддержки принятия решений. Пространственные данные, например, картографические, представляют один или несколько слоев двумерных изображений, на которые нанесены некоторые объекты.
Используя Z-упорядочение, кривую Гильберта и другие средства, можно отобразить многомерное пространство в одномерное.
Ниже показано порождение кривой Гильберта (рисунок 11.6).
Однако, при этом топологические свойства нарушаются. Обратим внимание на следующие особенности:
- Кривые на плоскости или в пространствах большей размерности строятся на некоторой сетке. Как узнать, какая сетка понадобится?
- Отношения типа "быть соседом" или "принадлежать одной области" могут нарушаться.
- Отсюда следует, что возникают проблемы с запросами типа:
- Поиск ближайших соседей.
- Вычисление пространственных соединений областей.
И еще одна проблема: как выполнять операции над объектами, описанными в разных сетках?
Естественным расширением В*-деревьев на многомерные области являются R-деревья. Это сбалансированные деревья, в которых листья ссылаются на минимальные прямоугольники, имеющие стороны параллельные осям координат и ограничивающие все объекты, по которым выполняются запросы.
11.4 Буферы базы
Обычно СУБД работают с базами данных, размер которых существенно превышает объем доступной оперативной памяти. Поэтому для повышения быстродействия можно поместить в буферы оперативной памяти только небольшую часть базы. Это означает, что буферные пулы даже очень больших размеров быстро переполнятся. СУБД должна будет удалить некоторые блоки памяти, освободив место для вновь поступающих блоков, которые будут считаны с дисков.
Способа организации обменов данными между оперативной памятью и дисками, оптимальных одновременно для баз данных и всех других задач, не существует. Старая идея создания машины баз данных или разработки операционных систем приспособленных для работы с базами данных только в последние годы была реанимирована. Однако, в настоящее время во многих случаях базы данных работают на операционных системах, не идеально приспособленных для решения их задач.
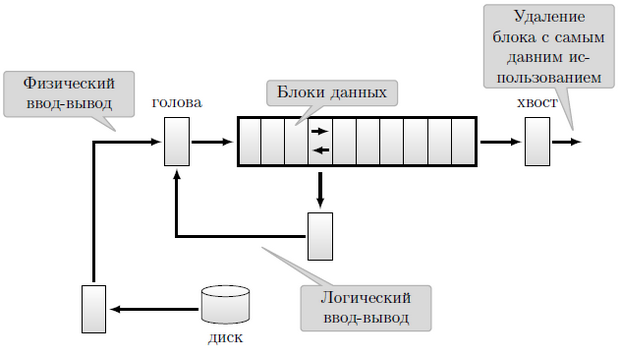
Рассмотрим один вариант буферизации данных. Кэш буферов данных, реализующий алгоритм LRU (рисунок 11.7) может содержать большое количество блоков, исчисляемое сотнями тысяч и более. Вспомним, что название стратегии LRU (Least Recently Used) переводится как "самый давно используемый". По этой стратегии в первую очередь должны быть удалены блоки, к которым дольше всего не было обращений.
При физическом чтении блок, считываемый с диска, помещается в голову кэша. Все содержимое кэша сдвигается на один блок. Хвостовой блок выталкивается.
При логическом чтении выбранный блок из середины кэша перемещается в голову. Часть кэша левее выбранного блока смещается вправо на один блок.
Со временем кэш заполнится. Часто используемые блоки будут находиться ближе к голове. Редко используемые блоки будут сдвигаться к хвосту.
А теперь давайте представим, как реализовать такой алгоритм. При числе блоков в сотни тысяч и размере блока 4 Кбайт время сдвига на один блок может составить десятые доли секунды. То есть, алгоритм не реализуем по скорости. Однако, можно выполнить эквивалентные действия с указателями и не производить сдвигов данных фактически.
Стратегия LRU теряет эффективность при использовании индексов, так как блокам индексов нужно отдавать предпочтение перед блоками данных, стараясь удерживать в кэше в первую очередь их.
Заметим, что существуют более эффективные стратегии, например, LRU-K. Можно также использовать несколько кэшей буферов базы.