Фундаментальные структуры данных, универсальность и сложность алгоритмов
5.3. Оценка алгоритмической сложности
Последний комментарий поднимает проблему эффективности (производительности), которая включает как время выполнения, так и требуемый объем памяти. Главная причина использования различных видов контейнеров состоит в том, что они обладают разной эффективностью по памяти и времени, зависящей от выполняемых над контейнером операций.
Необходим надежный способ сравнения производительности для выбора нужного типа контейнера. Недостаточно провести эксперименты над конкретным контейнером и сделать вывод, что "в среднем запрос на вызов элемента требует 10 наносекунд при работе с массивом и 40 наносекунд при работе со связным списком".
- Корректные рассуждения "о средних" требуют знания статистического распределения. Для размеров контейнеров трудно ожидать разумного определения такого распределения (сколько контейнеров может быть с 10 элементами, сколько с 1000 элементами и т. д.).
- Нельзя полагаться на результаты измерений из-за проблем масштабирования. Некоторые методы прекрасно работают для небольших размеров структуры, но становятся критическими для больших структур.
- Результаты измерений существенно зависят от окружения – компьютера, операционной системы, даже от языка программирования и компилятора; те же эксперименты в другом окружении могут дать принципиально различные результаты.
Основной способ оценки сложности алгоритмов свободен от таких привходящих обстоятельств. Он известен как абстрактная сложность, а также как асимптотическая сложность или нотация "О-большое".
Измерение порядка величин
Абстрактная сложность основывается на двух принципах.
- Рассматривает меру сложности как функцию от размера структуры данных. Для большинства примеров этой лекции размер задается одним параметром – count – числом элементов контейнера.
- Функция определяется не точной формулой, а порядком величины, задаваемой нотацией "О-большое", как O(count).
Когда мы говорим, что время поиска элемента в списке из count элементов составляет O(count), это означает, что с ростом count оно возрастает, в худшем случае, пропорционально count. Другая операция может иметь время 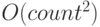 , означающее, что время возрастает самое большее пропорционально квадрату числа элементов. Те же соглашения действуют при оценке требуемой памяти.
, означающее, что время возрастает самое большее пропорционально квадрату числа элементов. Те же соглашения действуют при оценке требуемой памяти.
Для такой меры:
- константные мультипликативные множители не играют роли:
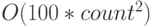 означает то же самое, что и . Объяснение этого соглашения состоит в том, что не следует придавать большого значения умножению на константу, так как реализация того же алгоритма может быть в сто раз быстрее или медленнее, будучи перенесенной на другую машину. Но рост времени вычислений при изменении count не зависит от таких технических деталей;
означает то же самое, что и . Объяснение этого соглашения состоит в том, что не следует придавать большого значения умножению на константу, так как реализация того же алгоритма может быть в сто раз быстрее или медленнее, будучи перенесенной на другую машину. Но рост времени вычислений при изменении count не зависит от таких технических деталей; - понятно, что не имеет значения и константная аддитивная составляющая:
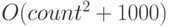 означает то же самое, что и . Конечно, константа может оказывать влияние при небольших значениях count, но с его ростом влияние становится ничтожным;
означает то же самое, что и . Конечно, константа может оказывать влияние при небольших значениях count, но с его ростом влияние становится ничтожным; - аналогично: любая аддитивная составляющая с меньшим значением экспоненты также не оказывает влияния на порядок величины –
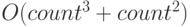 означает то же самое, что и
означает то же самое, что и 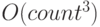 .
.
Как следствие, чтобы выразить тот факт, что алгоритм работает константное время, более точно – что на любой платформе время выполнения ограничено константой, будем говорить, что время работы O(1). Конечно с тем же успехом можно писать O(37) или O(1000), но принято писать O(1).
Математические основы
Нотация "О-большое" может показаться неформальной, но ее можно строго определить, как отношение между функциями.
Определение: нотация "О-большое" и абстрактная сложность
Алгоритм является O (g (n)) по времени или по памяти, если функция, задающая время выполнения или требуемый объем памяти при входном размере n, есть O (g (n)).
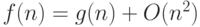 ", что является сокращением записи "f (n) = g (n) + s (n) для некоторой функции s, где s (n) есть
", что является сокращением записи "f (n) = g (n) + s (n) для некоторой функции s, где s (n) есть 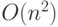 ". Тем самым устанавливается, что f "подобна" g, отличаясь на терм .
". Тем самым устанавливается, что f "подобна" g, отличаясь на терм .Следствием определения является тот факт, что если функция есть , то верно, что она есть также 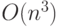 ,
, 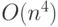 и так далее. Это потому, что О-большое задает верхнюю границу, а не представляет точную оценку. Полезные утверждения, связанные со сложностью, часто имеют вид: "Доказано, что сложность данного алгоритма есть
и так далее. Это потому, что О-большое задает верхнюю границу, а не представляет точную оценку. Полезные утверждения, связанные со сложностью, часто имеют вид: "Доказано, что сложность данного алгоритма есть 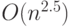 . Можно ли улучшить оценку и доказать, что его сложность есть ?"
. Можно ли улучшить оценку и доказать, что его сложность есть ?"
При анализе сложности алгоритмов часто возникают логарифмы. Например, лучшие алгоритмы сортировки списка из n элементов имеют сложность 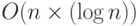 . В этой формуле не указывается основание системы логарифмов (2 или 10), поскольку изменение основания приводит к появлению мультипликативной константы
. В этой формуле не указывается основание системы логарифмов (2 или 10), поскольку изменение основания приводит к появлению мультипликативной константы 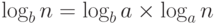 .
.
Лучшее использование выигрыша в лотерею
Соглашение об игнорировании мультипликативной константы на первый взгляд кажется удивительным. Алгоритм, работающий  наносекунд, считается хуже алгоритма, работающего
наносекунд, считается хуже алгоритма, работающего 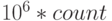 наносекунд, хотя последний работает быстрее при count меньше миллиона.
наносекунд, хотя последний работает быстрее при count меньше миллиона.
Следующее наблюдение позволяет понять преимущества алгоритмов, лучших по сложности. Рассмотрим четыре алгоритма, каждый из которых, непрерывно работая на вашем компьютере, за 24 часа может решить задачу максимальной размерности соответственно 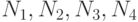 . Предположим теперь, что алгоритмическая сложность наших алгоритмов соответственно составляет
. Предположим теперь, что алгоритмическая сложность наших алгоритмов соответственно составляет 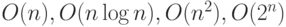 . Предположим еще (что менее вероятно), что вы выиграли в лотерею большую сумму и можете купить новый компьютер, работающий в 1000 раз быстрее старого. Что это может вам дать?
. Предположим еще (что менее вероятно), что вы выиграли в лотерею большую сумму и можете купить новый компьютер, работающий в 1000 раз быстрее старого. Что это может вам дать?
Для первого алгоритма со сложностью O(n) теперь можно будет решить задачу в 1000 раз большего размера – 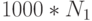 .
.
Для второго алгоритма со сложностью  теперь можно будет решить задачу большего размера с множителем, близким к 1000.
теперь можно будет решить задачу большего размера с множителем, близким к 1000.
Для третьего алгоритма со сложностью 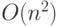 теперь можно будет решить задачу большего размера с существенно меньшим множителем, равным квадратному корню из 1000, примерно равным 32.
теперь можно будет решить задачу большего размера с существенно меньшим множителем, равным квадратному корню из 1000, примерно равным 32.
Для четвертого алгоритма увеличение размера почти неощутимо, размер задачи увеличится на 10 (не в 10 раз, а на 10!).
Правильный вопрос, который нужно задавать при анализе сложности алгоритма, – не "каково время решения задачи", а "насколько большую задачу можно решить данным алгоритмом за фиксированное время при увеличении скорости работы компьютера".
Абстрактная сложность дает нам взгляд на эффективность алгоритма, свободный от технических деталей, и позволяет оценить преимущества его потенциального улучшения.
Абстрактная сложность на практике
Говоря об абстрактной сложности, чаще всего рассматривают три разных варианта, особенности каждого из которых следует четко понимать.
Средняя сложность, ожидаемое среднее время или требуемый в среднем объем памяти алгоритма. Как отмечалось ранее, говорить о среднем можно только в предположении о существовании случайного распределения для входов программы. Обычно среднюю сложность считают в предположении, что все входы равновероятны (например, при сортировке массива из n элементов можно считать, что все n! возможных упорядочений элементов могут появляться с равной вероятностью).
Максимальная сложность, также называемая сложностью в худшем случае, дающая время или память для случая, на котором алгоритм работает дольше всего (требует максимальной памяти).
Минимальная сложность, также называемая сложностью в лучшем случае, дающая время или память для случая, на котором алгоритм работает быстрее всего (требует минимальной памяти). Этот критерий используется редко – его любят те, кто верит в удачу.
Презентация структур данных
В оставшейся части лекции будем рассматривать фундаментальные структуры данных. Их презентация основана на библиотеке EiffelBase, содержащей повторно используемые классы для всех изучаемых понятий: ARRAY, LINKED_LIST, HASH_TABLE, STACK и так далее.
Описание дается в ориентации на клиента-программиста, того, кто будет использовать библиотечные классы в собственном приложении. По этой причине методы будут вводиться в их контрактном облике. Презентация объясняет базисные способы реализации; как правило, сама реализация не дается, но с ней при желании можно познакомиться, поскольку EiffelBase является библиотекой с открытым кодом, одна из целей которой состоит в предоставлении надежных образцов ОО-стиля программирования, проверенных в течение многих лет использования.