|
Прохожу курс "Построение распределенных систем на Java" в третьей лекции где описывается TCPServer вылетает эта ошибка
"Connection cannot be resolved to a type" Java version 1.7.0_05 |
Опубликован: 10.10.2010 | Доступ: свободный | Студентов: 3235 / 318 | Оценка: 4.14 / 3.32 | Длительность: 13:16:00
ISBN: 978-5-9963-0444-8
Специальности: Системный архитектор
Теги:
Дополнительный материал 1:
Параллелизм и репликация данных
Восстановление после сбоев. Откат транзакции
Важнейшая задача транзакционной обработки - атомарность - предполагает возможность отката сделанных изменений в случае если какое то из действий, составляющих транзакцию, закончилось неудачей. Другой важной характеристикой транзакции является долговечность, т.е. сохранение результатов транзакции после ее фиксации. Часто выполнение этих двух (вообще говоря, различных) задач объединяют в одном компоненте, называемом менеджером восстановления. Рассмотрим, однако, сначала первую задачу, а именно откат незавершенной транзакции. Первый из способов реализации этого механизма состоит в том, что изменения, которые делает транзакция в процессе работы, записываются не в долговременную память, а во временную. При этом в случае фиксации транзакции происходит перенос данных из временной памяти в основную, а в случае отката временная память просто очищается.
Одна из проблем здесь состоит в том, что в случае фиксации транзакции требуется немедленно перенести данные в долговременную память (в основном это жесткий диск), что в случае частых коротких транзакций будет плохо отражаться на производительности системы.
Другой проблемой является то, что если произошла необнаруженная (или обнаруженная) ошибка диска, данные завершенной транзакции могут быть потеряны. Поэтому часто применяют другой метод (иногда - совместно с первым), который состоит в журналировании операций, выполняемых транзакцией. При таком подходе все изменения, которые производит транзакция, вместо того чтобы записываться в долговременную память, записываются в журнал операций. В случае отката транзакций часть журнала, относящегося к прерванной транзакции, может быть просто уничтожена (часто в этом случае в журнал операций записывается специальная операция отката транзакции), а в случае фиксации транзакции операции из журнала должны быть "проиграны" на основной долговременной памяти.
Первое преимущество здесь состоит в том, что после фиксации транзакции не нужно сразу же переносить данные в долговременную память - это может делаться для нескольких завершенных транзакций сразу (причем операции в журнале при этом могут быть переупорядочены для увеличения быстродействия). Появляется еще одна полезная возможность - в случае повреждения по той или иной причине части данных в основном долговременном хранилище они могут быть восстановлены по журналу операций, вот почему говорилось о связи восстановления после сбоев и отката транзакции. Существенным минусом такого подхода является то, что появляется время, в течение которого данные, измененные зафиксированными транзакциями в основном долговременном хранилище, оказываются "старыми", неизмененными. Эта проблема может быть решена, например, блокировкой всех измененных, но не сброшенных из журнала операций данных.
Вложенные и распределенные транзакции
До сих пор мы рассматривали транзакции, имеющие простую структуру, а именно состоящие просто из последовательности операций. Можно, однако, поговорить о возможности создания так называемых вложенных транзакций. Т.е. транзакции могут содержать другие транзакции - в таком случае транзакции образуют дерево. Это может быть удобным для решения ряда практических задач. В таком случае операции работы с транзакциями несколько видоизменяются - можно, например, откатить или зафиксировать не всю общую транзакцию, а лишь какую-то часть поддерева. Следует отметить, что, если речь идет о распределенной системе, большая часть проходящей в ней транзакций так или иначе будет содержать вложенные транзакции. Рассмотрим в качестве примера информационную систему, обеспечивающую заказ туристических туров. Последовательность действий при бронировании тура может быть, например, следующей:
- поиск подходящего отеля и бронирование в нем места;
- поиск подходящего авиарейса и бронирования места на нем;
- поиск подходящего обратного авиарейса и бронирование места на нем;
- заказ необходимых дополнительных услуг (экскурсий, и т.д.);
- оплата через банк всего пакета услуг (проживание, перелет, экскурсии).
Все вышеперечисленные действия представляют собой транзакцию с точки зрения нашей информационной системы - в самом деле, невыполнение любого из этих пунктов (кроме, может быть, оплаты) приводит к тому, что клиент от тура просто отказывается и все предварительно выполненные действия по другим пунктам должны быть отменены. С другой стороны, если не прошла оплата услуг, турагентство, опять же, должно отменить все другие действия. Но на самом деле каждое из описанных действий, в свою очередь, имеет сложную структуру. Так, например, если клиент и турагентство используют разные банки, должна пройти межбанковская транзакция по переводу денег. Таким образом, для распределенных систем необходим некий механизм для управления распределенными транзакциями. В качестве такого механизма часто используют так называемый протокол двухфазной фиксации транзакций.
Двухфазный протокол фиксации транзакций (2PC)
Суть его состоит в следующем.
- В системе выделяется менеджер транзакций (управляющий компонент; во многих реализациях он называется координатором транзакций).
- Фиксация изменений транзакции происходит в два этапа. На первом этапе изменения верифицируются. Производятся все необходимые проверки, которые гарантируют, что внесенные изменения полностью готовы к переносу в долговременную память (некоторые реализации уже на этой фазе переносят изменения в долговременную память, помечая их как незафиксированные). Вторая фаза начинается только после того, как все узлы, вовлеченные в транзакцию, отрапортуют координатору об успешном завершении первой фазы (фактически, первая фаза отвечает на вопрос - может ли на этом узле быть выполнена операция commit?). Вторая фаза состоит в простом переносе уже подготовленных изменений в долговременную память. Идея метода состоит в том, что на второй фазе вероятность каких-либо ошибок очень мала, поскольку на первой фазе проведена вся необходимая подготовка и все необходимые проверки.
Ниже приведен пример протокола работы координатора при фиксации транзакции.
-
Фаза 1
- Координатор посылает сообщение CanCommit на все узлы, вовлеченные в транзакцию.
- Когда узел получает сообщение CanCommit, он отвечает координатору Yes или No. Перед тем, как ответить Yes, узел выполняет подготовку к фиксации изменений, записывая объекты в долговременной памяти. В случае ответа No (или в том случае, когда при подготовке ответа Yes произошла ошибка) узел немедленно откатывает свои изменения.
-
Фаза 2
- Координатор собирает ответы от всех узлов.
- Если все узлы ответили Yes, координатор фиксирует транзакцию и рассылает всем узлам сообщения doCommit.
- В противном случае координатор откатывает транзакцию, рассылая всем узлам сообщение doAbort.
- Узлы, которые ответили Yes на запрос CanCommit, ожидают сообщения doCommit или doAbort от координатора. При получении одного из этих сообщений узел выполняет фикса цию или откат своих изменений, после чего пересылает координатору сообщение HaveEnded.
- Координатор собирает ответы от всех узлов.
Репликация данных
Задача репликации данных (под репликацией понимают управление копиями одних и тех же данных на нескольких узлах) при проектировании распределенных систем возникает достаточно часто. Происходи это по двум причинам. Первая причина - требование повышения производительности. Если между узлом, на котором хранятся данные, и узлом, который их обрабатывает, медленный (или ненадежный) канал, это может приводить к чрезмерно длительному времени работы системы. Если потребность в такого рода операциях возникает часто, то нужно задуматься либо о переносе данных "ближе" к узлам, в них нуждающимся, либо о создании локальных копий данных, т.е. их репликации. Другая причина, по которой часто используют репликацию, состоит в требовании повышения надежности системы путем резервного копирования части критичных данных.
Таким образом, репликация данных является задачей, с которой разработчики распределенных систем сталкиваются очень часто.
Основные требования, которые предъявляются к системе репликации, обычно состоят в следующем: репликация должна быть прозрачной (обращение клиента к сервису не должно отличаться в случае использования сервисом данных реплики) и реплицированные данные должны быть целостными (пользуясь тем, что нам знакомо понятие транзакции, можно сказать, что реплицироваться должны только изменения для зафиксированных транзакций, т.е. только финальные, непротиворечивые состояния объектов).
В общем виде задача репликации довольно сложна, поэтому далее будут рассмотрены некоторые частные случаи, наиболее часто встречающиеся в практических приложениях, и предложены некоторые подходы к решению этих задач.
Пассивная (primary-backup) репликация
Это простейший случай (тем не менее, широко распространенный), при котором изменение данных допускается только на одном узле (данные, размещенные на этом узле, называются мастер-копией), а на всех других узлах данные доступны только для чтения. Может использоваться как для резервного копирования данных, так и в большинстве информационных систем, в которых операции изменения данных сравнительно редки по отношению к операциям извлечения данных (при этом извлекаются данные большого объема) и могут быть сведены к операциям над мастер-копией.
Механизмов реализации для такой модели репликации может быть несколько.
Первый подход,и простейший, состоит в том, что (предполагается, что данных немного) весь массив данных по некоторому регламенту копируется на удаленные узлы. При этом подходе предполагается, что данные изменяются нечасто и на удаленных узлах не важна их высокая актуальность.
Второй подход называется репликацией на временных метках ( times-tamp-replication ). Он состоит в том, что любая транзакция, изменяющая данные, изменяет также и временную метку ( timestamp ) этих данных. Таким образом, у данных, которые изменялись позднее, будет большая временная метка, чем у данных, которые изменялись раньше. Зная время последнего удачного обмена данными, менеджер репликаций "снимает" все данные, измененные позднее, и передает на удаленный узел только их. Здесь нужно сделать два замечания.
Замечание первое:поскольку мы "видим" только данные, которые изменены зафиксированными транзакциями, кажется, что не будет нарушено условие консистентности реплики, однако это не так (вспомним пример с подсчетом баланса во время проведения платежа). Поэтому процесс, "снимающий" измененные данные, должен работать на уровне изоляции Serializable.
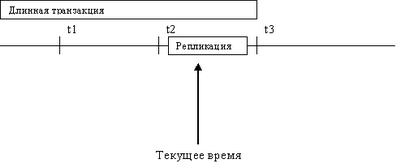
Замечание второе:представьте себе, что передача измененных данных осуществляется каждый час. В системе есть транзакция, работающая три часа (рис. 14.2). Поскольку данные, измененные долгой транзакцией, репликация увидит только в момент t3, а к тому времени передача данных уже закончена (и не раз!), есть шанс, что изменения, сделанные до t2, никогда не будут переданы на другие узлы. Выходов здесь может быть несколько - либо при завершении транзакции изменять все временные метки на время завершения транзакции, либо в момент начала репликации отслеживать все незавершенные транзакции (и время их начала), чтобы затем делать отступ назад по времени.
Третий подход состоит в передаче не данных, а журнала операций над этими данными (про журнал операций говорилось в разделе, посвященном восстановлению после сбоев). При этом подходе, опять же, каждой операции сопоставляется временная метка. Все операции, совершенные позднее последнего сеанса обмена, должны быть переданы и "проиграны" на других узлах. Поскольку операции пишутся в журнал линейно, в том числе и для незавершенных транзакций, подобного эффекта с потерей части изменений не возникает.
Следует отметить, что рассмотренный случай (пассивная репликация) имеет два более сложных варианта. Первый - когда каждый из узлов владеет собственной порцией данных, непересекающихся с другими, для которой узел владеет мастер-копией и реплицирует эту копию всем остальным узлам. В качестве примера можно рассмотреть информационную систему "офис-магазин". В офисе ведутся справочник товаров и прайс-лист, которые реплицируются в магазин в виде доступных только для чтения объектов; в свою очередь, магазин реплицирует в офис чековую ленту, которую офис может только просматривать и не может изменить. Второй вариант еще чуть более сложный. Он снова предполагает явное разделение прав владения между узлами, но уже на уровне одного класса сущностей. В качестве примера можно предложить информационную систему для регистрации на конференцию, причем построенную таким образом, что на каждом из терминалов системы могут зарегистрироваться участники, фамилии которых начинаются на определенную букву, скажем на первом терминале регистрируются участники с фамилиями, начинающимися с букв A, Б, В, на втором - Г, Д, Е и т.д. В любом случае, пассивная репликация предполагает выполнение одного очень важного правила: каждый из узлов может, не взаимодействуя с другими узлами, точно определить, может он редактировать данную сущность или нет. Причем, правами на редактирование каждой сущности может обладать только один из узлов системы. Это распределение прав не изменяется с течением времени. Очевидно, что рассмотренные варианты пассивной репликации годятся и для этих чуть более сложных случаев.
Активная репликация с блокировкой
Главное отличие от пассивной репликации состоит в том, что более чем один узел системы может претендовать на то, чтобы изменить объект. При репликации с блокировкой предполагается, что прежде чем изменять объект, узел запрашивает разрешение на это у центрального координатора (фактически, это является блокировкой объекта, поскольку как только такое разрешение получено, остальные запросы на этот же объект координатором будут отвергаться). После того, как объект изменен, это изменение реплицируется на все узлы, которые потенциально могут изменять этот объект, и только после этого блокировка объекта снимается. Делается это (репликация изменений) для того, чтобы исключить возможность возникновения проблемы "потерянного обновления". Например, узел А, предварительно заблокировав объект, изменил его, затем снял блокировку, не разослав изменений. Затем узел В, ничего не зная об изменениях, сделанных на А, изменил тот же самый объект - таким образом, изменения А оказались потерянными. Для реализации активной репликации с блокировкой необходим механизм блокировки объекта и механизм транзакций - репликация изменений на другие узлы должна объявляться транзакцией, только после ее выполнения блокировка объекта будет сниматься. Реализация репликации может быть такой же, как и в предыдущем случае.
Активная репликация без блокировки
В этом случае рассматривается система, в которой несколько узлов могут одновременно выполнять операции над одним и тем же объектом, не блокируя его и не дожидаясь репликаций о других изменениях. При применении такого метода возможны разнообразные эффекты типа "потерянного обновления" и т.д. Возможен эффект невозможности приема репликаций - например, мы разрешаем ведение справочника покупателей на двух разных узлах, при этом накладываем ограничение, что название покупателя должно быть уникально в пределах справочника. Достаточно независимо занести двух покупателей с одинаковыми именами (но, может быть, с различающимися остальными атрибутами!) на разных узлах, чтобы репликация между этими узлами оказалась невозможной из-за нарушения ограничения уникальности1Такого рода ситуации называются коллизиями. Существуют специальные методы их разрешения, но в общем случае задача, очевидно, неразрешима, потому что мы в любом случае должны оставить какое-то одно из введенных значений, потеряв второе (либо внести в них искусственные изменения) .
Несмотря на такие, казалось бы, фатальные проблемы, эта модель репликации тоже очень часто используется. Тонкость состоит в том, что в ряде случаев совсем не нужно редактировать сущности, достаточно их добавлять. По этой модели, например, устроено множество банковских платежных систем (практически все системы, не требующие online -соединения с процессинговым центром). В этом случае оконечные узлы формируют операции (выдачу и прием сумм), которые затем асинхронно пересылаются и обрабатываются банком или любым другим оператором.
Алмаз Мурзабеков