|
Как узнать оценку за курс?
|
Опубликован: 02.11.2010 | Доступ: свободный | Студентов: 5098 / 1581 | Оценка: 4.32 / 4.07 | Длительность: 17:08:00
ISBN: 978-5-9963-0416-5
Тема: Операционные системы
Специальности: Архитектор программного обеспечения
Лекция 5:
Организация вычислительного процесса
5.8. Семафоры и мониторы
Одним из первых механизмов, предложенных для синхронизации поведения процессов, стали семафоры, концепцию которых описал Дейкстра (Dijkstra) в 1965 году. Семафор представляет собой целую переменную, принимающую неотрицательные значения, доступ любого процесса к которой, за исключением момента ее инициализации, может осуществляться только через две атомарные операции: P (от датского слова proberen – проверять) и V (от verhogen – увеличивать). Классическое определение этих операций выглядит следующим образом:
P(S): пока S == 0 процесс блокируется; S = S - 1; V(S): S = S + 1;
Эта запись означает следующее: при выполнении операции P над семафором S сначала проверяется его значение. Если оно больше 0, то из S вычитается 1. Если оно меньше или равно 0, то процесс блокируется до тех пор, пока S не станет больше 0, после чего из S вычитается 1. При выполнении операции V над семафором S к его значению просто прибавляется 1.
Подобные переменные-семафоры могут с успехом использоваться для решения различных задач организации взаимодействия процессов. В ряде языков программирования они были непосредственно введены в синтаксис языка (например, в ALGOL-68), в других случаях применяются через использование системных вызовов. Соответствующая целая переменная располагается внутри адресного пространства ядра операционной системы. Операционная система обеспечивает атомарность операций P и V, используя, например, метод запрета прерываний на время выполнения соответствующих системных вызовов. Если при выполнении операции P заблокированными оказались несколько процессов, то порядок их разблокирования может быть произвольным, например, FIFO.
Одной из типовых задач, требующих организации взаимодействия процессов, является задача producer-consumer (производитель-потребитель). Пусть два процесса обмениваются информацией через буфер ограниченного размера. Производитель закладывает информацию в буфер, а потребитель извлекает ее оттуда. Грубо говоря, на этом уровне деятельность потребителя и производителя можно описать следующим образом:
Producer: while(1)
{
produce_item;
put_item;
}
Consumer:
while(1)
{
get_item;
consume_item;
}Если буфер забит, то производитель должен ждать, пока в нем появится место, чтобы положить туда новую порцию информации. Если буфер пуст, то потребитель должен дожидаться нового сообщения. Как можно реализовать эти условия с помощью семафоров? Возьмем три семафора empty, full и mutex. Семафор full будем использовать для гарантии того, что потребитель будет ждать, пока в буфере появится информация.
Семафор empty будем использовать для организации ожидания производителя при заполненном буфере, а семафор mutex – для организации взаимоисключения на критических участках, которыми являются действия put_item и get_item (операции "положить информацию" и "взять информацию" не могут пересекаться, поскольку возникнет опасность искажения информации). Тогда решение задачи выглядит так:
Semaphore mutex = 1;
Semaphore empty = N, где N – емкость буфера;
Semaphore full = 0;
Producer: while(1)
{
produce_item;
P(empty);
P(mutex);
put_item;
V(mutex);
V(full);
}
Consumer: while(1)
{
P(full);
P(mutex);
put_item;
V(mutex);
V(empty);
consume_item;
}Легко убедиться, что это действительно корректное решение поставленной задачи. Попутно заметим, что семафоры использовались здесь для достижения двух целей: организации взаимоисключения на критическом участке и синхронизации скорости работы процессов.
Хотя решение задачи producer-consumer с помощью семафоров выглядит достаточно элегантно, программирование с их использованием требует повышенной осторожности и внимания, чем, отчасти, напоминает программирование на языке ассемблера. Допустим, что в рассмотренном примере мы случайно поменяли местами операции P, сначала выполняя ее для семафора mutex, а уже затем для семафоров full и empty. Допустим теперь, что потребитель, войдя в свой критический участок ( mutex сброшен), обнаруживает, что буфер пуст. Он блокируется и начинает ждать появления сообщений. Но производитель не может войти в критический участок для передачи информации, так как тот заблокирован потребителем. Получаем тупиковую ситуацию.
В сложных программах произвести анализ правильности использования семафоров с карандашом в руках становится очень непростым занятием. В то же время обычные способы отладки программ зачастую не дают результата, поскольку возникновение ошибок зависит от interleaving'а атомарных операций, и ошибки могут быть трудно воспроизводимы. Для того чтобы облегчить труд программистов, в 1974 году Хоаром (Hoare) был предложен механизм еще более высокого уровня, чем семафоры, получивший название мониторов. Рассмотрим конструкцию, несколько отличающуюся от оригинальной.
Мониторы представляют собой тип данных, который может быть с успехом внедрен в объектно-ориентированные языки программирования. Монитор обладает своими собственными переменными, определяющими его состояние. Значения этих переменных извне монитора могут быть изменены только с помощью вызова функций-методов, принадлежащих монитору. В свою очередь, эти функции-методы могут использовать в своей работе только данные, находящиеся внутри монитора, и свои параметры. На абстрактном уровне можно описать структуру монитора следующим образом:
monitor monitor_name
{
описание переменных ;
void m1(...){...
}
void m2(...)
{
...
}
...
void mn(...)
{
...
}
{
блок инициализации внутренних переменных ;
}Здесь функции m1,..., mn представляют собой функции-методы монитора, а блок инициализации внутренних переменных содержит операции, которые выполняются только один раз: при создании монитора или при самом первом вызове какой-либо функции-метода до ее исполнения.
Важной особенностью мониторов является то, что в любой момент времени только один процесс может быть активен, т. е. находиться в состоянии "готовность" или "исполнение", внутри данного монитора. Поскольку мониторы представляют собой особые конструкции языка программирования, компилятор может отличить вызов функции, принадлежащей монитору, от вызовов других функций и обработать его специальным образом, добавив к нему пролог и эпилог, реализующий взаимоисключение. Так как обязанность конструирования механизма взаимоисключений возложена на компилятор, а не на программиста, работа программиста при использовании мониторов существенно упрощается, а вероятность появления ошибок становится меньше.
Однако одних только взаимоисключений недостаточно для того, чтобы в полном объеме реализовать решение задач, возникающих при взаимодействии процессов. Нам нужны еще и средства организации очередности процессов, подобно семафорам full и empty в предыдущем примере. Для этого в мониторах было введено понятие условных переменных (condition variables), над которыми можно совершать две операции – wait и signal, до некоторой степени похожие на операции P и V над семафорами.
Если функция монитора не может выполняться дальше, пока не наступит некоторое событие, она выполняет операцию wait над какой-либо условной переменной. При этом процесс, выполнивший операцию wait, блокируется, становится неактивным, и другой процесс получает возможность войти в монитор.
Когда ожидаемое событие происходит, другой процесс внутри функции-метода совершает операцию signal над той же самой условной переменной. Это приводит к пробуждению ранее заблокированного процесса, и он становится активным. Если несколько процессов дожидались операции signal для этой переменной, то активным становится только один из них. Что нужно предпринять для того, чтобы не оказалось двух процессов, разбудившего и пробужденного, одновременно активных внутри монитора? Хор предложил, чтобы пробужденный процесс подавлял исполнение разбудившего процесса, пока он сам не покинет монитор. Несколько позже Хансен (Hansen) предложил другой механизм: разбудивший процесс покидает монитор немедленно после исполнения операции signal. Рассмотрим подход Хансена. Применим концепцию мониторов к решению задачи "производитель-потребитель".
monitor ProducerConsumer
{
condition full, empty;
int count;
void put()
{
if(count == N) full.wait;
put_item;
count += 1;
if(count == 1) empty.signal;
}
void get()
{
if (count == 0) empty.wait;
get_item();
count -= 1;
if(count == N-1) full.signal;
}
{
count = 0;
}
}
Producer:
while(1)
{
produce_item;ProducerConsumer.put();
}
Consumer:
while(1)
{
ProducerConsumer.get();
consume_item;
}Легко убедиться, что приведенный пример действительно решает поставленную задачу.
5.9. Взаимоблокировки (тупики)
Коффман и другие исследователи доказали, что для возникновения тупиковой ситуации должны выполняться четыре условия [37].
- Условие взаимного исключения. Каждый ресурс в данный момент или отдан ровно одному процессу, или доступен.
- Условие удерживания и ожидания. Процессы, в данный момент удерживающие полученные ранее ресурсы, могут запрашивать новые ресурсы.
- Условие отсутствия принудительной выгрузки ресурсов. У процесса нельзя забрать принудительно ранее полученные ресурсы. Процесс, владеющий ими, должен сам освободить ресурсы.
- Условие циклического ожидания. Должна существовать круговая последовательность из двух и более процессов, каждый из которых ждет доступа к ресурсу, удерживаемому следующим членом последовательности.
Для того чтобы произошла взаимоблокировка, должны выполняться все эти четыре условия. Если хотя бы одно отсутствует, тупиковая ситуация невозможна.
При столкновении с взаимоблокировками используются четыре стратегии.
- Пренебрежение проблемой в целом.
- Обнаружение и восстановление. Позволить взаимоблокировке произойти, обнаружить ее и предпринять какие-либо действия.
- Избегать тупиковых ситуаций с помощью аккуратного распределения ресурсов.
- Предотвращать с помощью структурного опровержения одного из четырех условий, необходимых для взаимоблокировки.
Если взаимоблокировки случаются в среднем раз в пять лет, а сбои ОС, компиляторов и неисправности аппаратуры происходят в среднем один раз в неделю, то подходит первая стратегия. К этому надо добавить, что большинство операционных систем потенциально страдают от взаимоблокировок, которые не обнаруживаются, не говоря уже об автоматическом выходе из тупика.
Вторая техника представляет собой обнаружение и восстановление. При использовании этого метода система не пытается предотвратить попадания в тупиковые ситуации. Вместо этого она позволяет произойти взаимоблокировке, старается определить, когда это случилось, и затем совершает некоторые действия по возврату системы к состоянию, имевшему место до того, как система попала в тупик.
Рассмотрим методы обнаружения взаимоблокировок.
Обнаружение взаимоблокировки при наличии одного ресурса каждого типа достаточно просто. Для такой системы можно построить граф ресурсов и процессов, о котором уже говорилось, и если в графе нет циклов, система в тупик не попала.
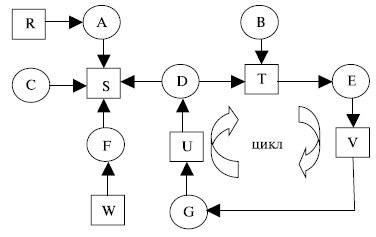
Например, пусть система из семи процессов (A, B, C, D, E, F, G) и шести ресурсов (R, S, T, V,W, U) в некоторый момент соответствует следующему списку [17].
1. Процесс A занимает ресурс R и хочет получить ресурс S.
Вопрос: заблокирована ли эта система, и если да, то какие процессы в этом участвуют?
Чтобы ответить на этот вопрос, нужно составить граф ресурсов и процессов (рис. 5.14).
Этот граф содержит цикл, указывающий, что процессы D, E, G заблокированы (зрительно легко видно). Однако в этом случае в операционной системе необходима реализация формального алгоритма, выявляющего тупики.
Рассмотрим возможность обнаружения взаимоблокировок при наличии нескольких ресурсов каждого типа. Пусть имеется множество процессов P={P1, P2,... Pn}, всего n процессов, и множество ресурсов E={E1, E2,... Em}, где m – число классов ресурсов. В любой момент времени некоторые из ресурсов могут быть заняты и, соответственно, недоступны. Пусть А – вектор доступных ресурсов A={A1, A2,... Am}. Очевидно, что Aj<= Ej, j = 1, 2, …, m.
Введем в рассмотрение две матрицы:
C={ci,j| i = 1, 2,…, n; j = 1, 2, …, m} – матрица текущего распределения ресурсов, где ci,j – количество ресурсов j-ого класса, которые занимает процесс Pi ;
R={ri,j| i = 1, 2,…, n; j = 1,2, …, m} – матрица требуемых (запрашиваемых) ресурсов, ri,j – количество ресурсов j-ого класса, которые хочет получить процесс Pi.
Справедливо m соотношений по ресурсам:
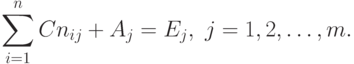
Алгоритм обнаружения взаимоблокировок основан на сравнении векторов доступных и требуемых ресурсов. В исходном состоянии все процессы не маркированы (не отмечены). По мере реализации алгоритма на процессы будет ставиться отметка, служащая признаком того, что они могут закончить свою работу и, следовательно, не находятся в тупике. После завершения алгоритма любой немаркированный процесс находится в тупиковой ситуации.
Алгоритм обнаружения тупиков состоит из следующих шагов.
- Отыскивается процесс Pi, для которого i-я строка матрицы R меньше вектора A, т.е. Ri <= A, или rj,I <Aj, j=1, 2, …, m.
- Если такой процесс найден, это означает, что он может завершиться, а следовательно – освободить занятые ресурсы. Найденный процесс маркируется, и далее прибавляется i-я строка матрицы С к вектору А, т.е. Aj = Aj + ci,j , j=1, 2, …, m. Возвращаемся к шагу 1.
- Если таких процессов не существует, работа алгоритма заканчивается. Немаркированные процессы попадают в тупик.
Когда нужно искать возникновение тупиков? Можно, конечно, проверять систему каждый раз, когда запрашивается очередной ресурс, это позволит обнаружить тупик максимально рано, но приведет к большим издержкам процессорного времени. Поэтому период проверки нужно выбрать: например, каждые К (сколько – нужно определить!) минут или когда процессор слабо загружен.
Предположим, обнаружен тупик. Какие методы можно использовать для его ликвидации? Здесь возможно несколько подходов.
Первый – принудительная выгрузка ресурсов: способность забирать ресурс у процесса, отдавать его другому процессу, а затем возвращать назад так, что исходный процесс не замечает того, в значительной мере зависит от свойств ресурса. Выйти из тупика, таким образом, зачастую трудно или невозможно.
Второй подход – восстановление через откат. В этом способе процессы должны периодически создавать контрольные точки, позволяющие запустить процесс с его предыстории. Когда взаимоблокировка обнаружена, достаточно просто понять, какие ресурсы нужны процессам. Чтобы выйти из тупика, процесс, занимающий необходимый ресурс, откатывается к тому моменту времени, перед которым он получил данный ресурс, для чего запускается одна из его контрольных точек. Вся работа, выполненная после этой контрольной точки, теряется. Если возобновленный процесс вновь пытается получить данный ресурс, ему придется ждать, когда ресурс станет доступным.
Третий подход – восстановление путем уничтожения одного или более процессов. Это грубейший, но простейший выход из тупика. Проблема – решить, какой процесс уничтожать.
Идеальной была бы такая организация вычислительного процесса, при которой не возникали бы тупики за счет безопасного распределения ресурсов. Подобные алгоритмы базируются на концепции безопасных состояний.