|
Подскажите, пожалуйста, планируете ли вы возобновление программ высшего образования? Если да, есть ли какие-то примерные сроки? Спасибо! |
Спонсор: Microsoft
Вы можете этот курс.
Опубликован: 20.12.2010 | Доступ: свободный | Студентов: 2412 / 165 | Оценка: 4.27 / 3.91 | Длительность: 39:39:00
ISBN: 978-5-9963-0353-3
Тема: Базы данных
Специальности: Администратор баз данных
Теги:
Лекция 9:
Создание физической модели хранилища данных
Разработка скрипта для создания объектов физической модели хранилища данных
Команды SQL для создания таблиц базы данных
Для определения и создания таблиц в SQL предусмотрена команда CREATE TABLE, которая определяет имя таблицы, имена и физический порядок колонок для нее, тип каждой колонки, а также некоторые указания для СУБД, такие как определение первичного или внешнего ключа, требования на запрет неопределенных значений в колонке таблицы и т.п.
Команда CREATE TABLE создает новую таблицу в БД. Синтаксис этой команды для диалекта SQL (Transact-SQL) СУБД семейства MS SQL Server приведен ниже.
CREATE TABLE
[ database_name . [ schema_name ] . | schema_name . ] table_name
( { <column_definition> | <computed_column_definition>
| <column_set_definition> }
[ <table_constraint> ] [ ,...n ] )
[ ON { partition_scheme_name ( partition_column_name ) | filegroup
| "default" } ]
[ { TEXTIMAGE_ON { filegroup | "default" } ]
[ FILESTREAM_ON { partition_scheme_name | filegroup
| "default" } ]
[ WITH ( <table_option> [ ,...n ] ) ]
[ ; ]
<column_definition> ::=
column_name <data_type>
[ FILESTREAM ]
[ COLLATE collation_name ]
[ NULL | NOT NULL ]
[
[ CONSTRAINT constraint_name ] DEFAULT constant_expression ]
| [ IDENTITY [ ( seed ,increment ) ] [ NOT FOR REPLICATION ]
]
[ ROWGUIDCOL ] [ <column_constraint> [ ...n ] ]
[ SPARSE ]
<data type> ::=
[ type_schema_name . ] type_name
[ ( precision [ , scale ] | max |
[ { CONTENT | DOCUMENT } ] xml_schema_collection ) ]
<column_constraint> ::=
[ CONSTRAINT constraint_name ]
{ { PRIMARY KEY | UNIQUE }
[ CLUSTERED | NONCLUSTERED ]
[
WITH FILLFACTOR = fillfactor
| WITH ( < index_option > [ , ...n ] )
]
[ ON { partition_scheme_name ( partition_column_name )
| filegroup | "default" } ]
| [ FOREIGN KEY ]
REFERENCES [ schema_name . ] referenced_table_name [ ( ref_column ) ]
[ ON DELETE { NO ACTION | CASCADE | SET NULL | SET DEFAULT } ]
[ ON UPDATE { NO ACTION | CASCADE | SET NULL | SET DEFAULT } ]
[ NOT FOR REPLICATION ]
| CHECK [ NOT FOR REPLICATION ] ( logical_expression )
}
<computed_column_definition> ::=
column_name AS computed_column_expression
[ PERSISTED [ NOT NULL ] ]
[
[ CONSTRAINT constraint_name ]
{ PRIMARY KEY | UNIQUE }
[ CLUSTERED | NONCLUSTERED ]
[
WITH FILLFACTOR = fillfactor
| WITH ( <index_option> [ , ...n ] )
]
| [ FOREIGN KEY ]
REFERENCES referenced_table_name [ ( ref_column ) ]
[ ON DELETE { NO ACTION | CASCADE } ]
[ ON UPDATE { NO ACTION } ]
[ NOT FOR REPLICATION ]
| CHECK [ NOT FOR REPLICATION ] ( logical_expression )
[ ON { partition_scheme_name ( partition_column_name )
| filegroup | "default" } ]
]
<column_set_definition> ::=
column_set_name XML COLUMN_SET FOR ALL_SPARSE_COLUMNS
< table_constraint > ::=
[ CONSTRAINT constraint_name ]
{
{ PRIMARY KEY | UNIQUE }
[ CLUSTERED | NONCLUSTERED ]
(column [ ASC | DESC ] [ ,...n ] )
[
WITH FILLFACTOR = fillfactor
|WITH ( <index_option> [ , ...n ] )
]
[ ON { partition_scheme_name (partition_column_name)
| filegroup | "default" } ]
| FOREIGN KEY
( column [ ,...n ] )
REFERENCES referenced_table_name [ ( ref_column [ ,...n ] ) ]
[ ON DELETE { NO ACTION | CASCADE | SET NULL | SET DEFAULT } ]
[ ON UPDATE { NO ACTION | CASCADE | SET NULL | SET DEFAULT } ]
[ NOT FOR REPLICATION ]
| CHECK [ NOT FOR REPLICATION ] ( logical_expression )
}
<table_option> ::=
{
DATA_COMPRESSION = { NONE | ROW | PAGE }
[ ON PARTITIONS ( { <partition_number_expression> | <range> }
[ , ...n ] ) ]
}
<index_option> ::=
{
PAD_INDEX = { ON | OFF }
| FILLFACTOR = fillfactor
| IGNORE_DUP_KEY = { ON | OFF }
| STATISTICS_NORECOMPUTE = { ON | OFF }
| ALLOW_ROW_LOCKS = { ON | OFF}
| ALLOW_PAGE_LOCKS ={ ON | OFF}
| DATA_COMPRESSION = { NONE | ROW | PAGE }
[ ON PARTITIONS ( { <partition_number_expression> | <range> }
[ , ...n ] ) ]
}
<range> ::=
<partition_number_expression> TO <partition_number_expression>Рассмотрим элементы и аргументы команды CREATE TАBLE.
- database_name. Имя БД, в которой создается таблица. В качестве аргумента database_name должно быть указано имя существующей БД. Если аргумент database_name не указан, по умолчанию таблица создается в текущей БД. Имя входа для текущего соединения должно быть связано с идентификатором пользователя, который существует в БД, указанной аргументом database_name, и этот пользователь должен обладать разрешениями CREATE TABLE.
- schema_name. Имя схемы, которой принадлежит новая таблица.
- table_name. Имя новой таблицы. Имена таблиц должны соответствовать правилам для идентификаторов. Аргумент table_name может состоять не более чем из 128 символов, за исключением имен локальных временных таблиц (имена с префиксом номера #), длина которых не должна превышать 116 символов.
- column_name. Имя столбца в таблице. Имена столбцов должны соответствовать правилам для идентификаторов и быть уникальными в данной таблице. Аргумент column_name может содержать от 1 до 128 символов. При создании столбцов с типом данных timestamp аргумент column_name может быть пропущен. Если аргумент column_name не указан, столбцу типа timestamp по умолчанию присваивается имя timestamp.
- computed_column_expression. Выражение, определяющее значение вычисляемого столбца. Вычисляемый столбец представляет собой виртуальный столбец, физически не хранящийся в таблице, если для него не установлен признак PERSISTED. Значение столбца вычисляется на основе выражения, использующего другие столбцы той же таблицы. Например, определение вычисляемого столбца может быть следующим: cost AS price * qty. Выражение может быть именем невычисляемого столбца, константой, функцией, переменной или любой их комбинацией, соединенной одним или несколькими операторами. Выражение не может быть вложенным запросом или содержать типы данных "псевдонимы".
Вычисляемые столбцы могут использоваться в списках выборки, предложениях WHERE, ORDER BY и в любых других местах, в которых могут применяться обычные выражения, за исключением следующих случаев.
- Вычисляемый столбец нельзя использовать ни в качестве определения ограничения DEFAULT или FOREIGN KEY, ни вместе с определением ограничения NOT NULL. Однако вычисляемый столбец может использоваться в качестве ключевого столбца индекса либо части какого-либо ограничения PRIMARY KEY или UNIQUE, если значение этого вычисляемого столбца определяется детерминистическим выражением и тип данных результата разрешен в столбцах индекса.
- Например, если таблица содержит целочисленные столбцы a и b, вычисляемый столбец a+b может быть включен в индекс, а вычисляемый столбец a+DATEPART(dd, GETDATE()) — не может, так как его значение может изменяться при последующих вызовах.
- Вычисляемый столбец не может быть целевым столбцом инструкций INSERT или UPDATE.
- PERSISTED. Указывает, что SQL Server Database Engine будет физически хранить вычисляемые значения в таблице и обновлять их при изменении любого столбца, от которого зависит вычисляемый столбец. Указание PERSISTED для вычисляемого столбца позволяет создать индекс по вычисляемому столбцу, который будет детерминистическим, но неточным. Любые вычисляемые столбцы, используемые в качестве столбцов секционирования в секционированной таблице, необходимо явно пометить признаком PERSISTED. Если указан признак PERSISTED, аргумент computed_column_expression должно быть детерминистическим.
- ON { <partition_scheme> | filegroup | "default" }. Указывает схему секционирования или файловую группу, в которой хранится таблица. Если аргумент <partition_scheme> указан, таблица будет разбита на секции, сохраняемые в одной или нескольких файловых группах, указанных аргументом <partition_scheme>. Если указан аргумент filegroup, таблица сохраняется в файловой группе с таким именем. Это должна быть существующая файловая группа в базе данных. Если указано значение "default", или параметр ON не определен вообще, таблица сохраняется в установленной по умолчанию файловой группе. Механизм хранения таблицы, указанный в инструкции CREATE TABLE, изменить в дальнейшем невозможно.
Параметр ON {<partition_scheme> | filegroup | "default"} может также указываться в ограничении PRIMARY KEY или UNIQUE. С помощью этих ограничений создаются индексы. Если указан аргумент filegroup, индекс сохраняется в файловой группе с таким именем. Если указано значение "default" или параметр ON не определен вообще, индекс сохраняется в той же файловой группе, что и таблица. Если ограничение PRIMARY KEY или UNIQUE создает кластеризованный индекс, страницы данных таблицы сохраняются в той же файловой группе, что и индекс. Если ограничение создает кластеризованный индекс (с помощью параметра CLUSTERED или другим способом), то указанный аргумент <partition_scheme> отличается от аргументов <partition_scheme> и filegroup из определения таблицы, либо наоборот, принимается во внимание только определение ограничения, а все остальное не учитывается.
- TEXTIMAGE_ON { filegroup | "default" }. Ключевые слова, указывающие, что столбцы типов text, ntext, image, xml, varchar(max), nvarchar(max), varbinary(max), а также пользовательских типов среды CLR хранятся в определенной файловой группе.
Параметр TEXTIMAGE_ON недопустим, если в таблице нет столбцов с большими значениями. Нельзя указывать параметр TEXTIMAGE_ON одновременно с параметром <partition_scheme>. Если указано значение "default" или параметр TEXTIMAGE_ON не определен вообще, столбцы с большими значениями сохраняются в установленной по умолчанию файловой группе. Способ хранения любых данных столбцов с большими значениями, определенный инструкцией CREATE TABLE, изменить в дальнейшем невозможно.
- FILESTREAM_ON { partition_scheme_name | filegroup | "default" }. Задает файловую группу для данных FILESTREAM.
Если таблица содержит данные FILESTREAM и является секционированной, необходимо включить предложение FILESTREAM_ON и указать схему секционирования файловых групп файлового потока. В этой схеме секционирования должны использоваться те же функции и столбцы секционирования, что и в схеме секционирования для таблицы ; в противном случае возникает ошибка.
Если таблица не секционирована, столбец FILESTREAM не может быть секционирован. Данные FILESTREAM для таблицы должны храниться в отдельной файловой группе. Эта файловая группа указывается в предложении FILESTREAM_ON.
Если таблица не является секционированной и предложение FILESTREAM_ON не указано, используется файловая группа FILESTREAM, для которой задано свойство DEFAULT. При отсутствии файловой группы FILESTREAM возникает ошибка.
Как и в случае с предложениями ON и TEXTIMAGE_ON, значение, указанное с помощью инструкции CREATE TABLE для предложения FILESTREAM_ON, не может быть изменено, за исключением следующих ситуаций.
- Инструкция CREATE INDEX преобразует кучу в кластеризованный индекс. В этом случае можно указать другую файловую группу FILESTREAM, схему секционирования или значение NULL.
- Инструкция DROP INDEX преобразует кластеризованный индекс в кучу. В этом случае можно указать другую файловую группу FILESTREAM, схему секционирования или значение "default".
Тип данных может быть одним из следующих.
- Системный тип данных.
- Тип данных — псевдонимы на основе системного типа данных SQL Server. Прежде чем псевдонимы типов данных можно будет использовать в определении таблицы, их нужно создать с помощью инструкции CREATE TYPE. Состояние признака NULL или NOT NULL для типа данных – псевдонима может быть переопределено с помощью инструкции CREATE TABLE. Однако его длину изменить нельзя; длина типа данных – псевдонима не определяется инструкцией CREATE TABLE.
- Пользовательский тип среды CLR. Прежде чем пользовательские типы среды CLR можно будет использовать в определении таблицы, их нужно создать с помощью инструкции CREATE TYPE. Для создания столбца с пользовательским типом среды CLR требуется разрешение REFERENCES на этот тип.
- precision. Точность указанного типа данных.
- Scale. Масштаб указанного типа данных.
-
Max. Применяется только к типам данных varchar, nvarchar и varbinary для хранения
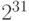 байт символьных и двоичных данных или 2^30 байт данных в Юникоде.
байт символьных и двоичных данных или 2^30 байт данных в Юникоде.
- CONTENT. Указывает, что каждый экземпляр типа данных xml в столбце column_name может содержать несколько элементов верхнего уровня. Аргумент CONTENT применим только к данным типа xml и может быть указан только в том случае, если одновременно указан аргумент xml_schema_collection. Если этот параметр не указан, CONTENT принимается в качестве поведения по умолчанию.
- DOCUMENT. Указывает, что каждый экземпляр типа данных xml в столбце column_name может содержать только один элемент верхнего уровня. Аргумент DOCUMENT применим только к данным типа xml и может быть указан только в том случае, если одновременно указан аргумент xml_schema_collection.
- xml_schema_collection.. Применим только к типу данных xml для коллекции XML- схем, связанной с этим типом. До помещения столбца xml схема должна быть создана в БД при помощи инструкции CREATE XML SCHEMA COLLECTION.
- DEFAULT. Указывает значение, присваиваемое столбцу в случае отсутствия явно заданного значения при вставке. Определения DEFAULT могут применяться к любым столбцам, кроме имеющих тип timestamp или обладающих свойством IDENTITY. Если значение по умолчанию указывается для столбца определяемого пользователем типа, этот тип должен поддерживать неявное преобразование выражения constant_expression в определяемый пользователем тип. Определения DEFAULT удаляются, когда таблица удаляется из памяти. В качестве значения по умолчанию могут использоваться только константы (например, символьные строки), скалярные функции (системные, определяемые пользователем или функции среды CLR) или значение NULL. Для совместимости с более ранними версиями SQL Server параметру DEFAULT может быть присвоено имя ограничения.
- constant_expression. Константа, значение NULL или системная функция, используемая в качестве значения столбца по умолчанию.
- IDENTITY. Указывает, что новый столбец является столбцом идентификаторов. При добавлении в таблицу новой строки компонент Database Engine формирует для этого столбца уникальное последовательное значение. Столбцы идентификаторов обычно используются с ограничением PRIMARY KEY для поддержания уникальности идентификаторов строк в таблице. Свойство IDENTITY может быть назначено столбцам типов tinyint, smallint, int, bigint, decimal(p,0) или numeric(p,0). Для каждой таблицы можно создать только один столбец идентификаторов. Ограниченные значения по умолчанию и ограничения DEFAULT не могут использоваться в столбце идентификаторов. Необходимо указать как начальное значение, так и приращение, или же не указывать ничего. Если ни одно из значений не указано, то действительно значение по умолчанию — (1,1).
- Seed. Значение, используемое для самой первой строки, загружаемой в таблицу.
- Increment. Значение приращения, добавляемое к значению идентификатора предыдущей загруженной строки.
- NOT FOR REPLICATION. В инструкции CREATE TABLE предложение NOT FOR REPLICATION может указываться для свойства IDENTITY, а также ограничений FOREIGN KEY и CHECK. Если это предложение указано для свойства IDENTITY, значения в столбцах идентификаторов не приращиваются, когда вставку выполняют агенты репликации. Если ограничение сопровождается этим предложением, оно не выполняется, когда агенты репликации выполняют операции вставки, обновления или удаления.
- ROWGUIDCOL. Указывает, что новый столбец является столбцом идентификаторов GUID. В качестве столбца ROWGUIDCOL можно назначить только один столбец uniqueidentifier в таблице. Применение свойства ROWGUIDCOL позволяет ссылаться на столбец с помощью ключевого слова $ROWGUID. Свойство ROWGUIDCOL можно присвоить только столбцу, имеющему тип uniqueidentifier. Ключевое слово ROWGUIDCOL недопустимо, если уровень совместимости базы данных равен 65 или ниже. Ключевым словом ROWGUIDCOL нельзя обозначать столбцы пользовательских типов данных.
Свойство ROWGUIDCOL не обеспечивает уникальности значений, хранимых в столбце. Кроме того, при указании данного свойства автоматическое формирование значений для новых строк, вставляемых в таблицу, не выполняется. Для создания уникальных значений в каждом столбце следует применять в инструкциях INSERT функции NEWID или NEWSEQUENTIALID либо использовать эти функции по умолчанию для столбца.
- SPARSE. Указывает, что столбец является разреженным столбцом. Хранилище разреженных столбцов оптимизируется для значений NULL. Для разреженных столбцов нельзя указать параметр NOT NULL.
- FILESTREAM. Допустимо только для столбцов типа varbinary(max). Указывает хранилище FILESTREAM для данных BLOB типа varbinary(max).
Таблица также должна содержать столбец типа uniqueidentifier с атрибутом ROWGUIDCOL. Этот столбец не должен допускать значений NULL и должен иметь ограничение, относящееся к одному столбцу, UNIQUE или PRIMARY KEY. Значение идентификатора GUID для столбца должно быть предоставлено приложением во время вставки данных или ограничением DEFAULT, в котором используется функция NEWID ().
Столбец ROWGUIDCOL нельзя удалить и связанные ограничения не могут быть изменены, если в таблице определен столбец FILESTREAM. Столбец ROWGUIDCOL можно удалить только после удаления последнего столбца FILESTREAM.
Если для столбца указан атрибут хранилища FILESTREAM, то все значения для этого столбца хранятся в контейнере данных FILESTREAM в файловой системе.
- COLLATE collation_name. Задает параметры сортировки для столбца. Имя параметров сортировки может быть либо именем параметров сортировки Windows, либо именем параметров сортировки SQL. Аргумент collation_name применим только к столбцам типов данных char, varchar, text, nchar, nvarchar и ntext. Если этот аргумент не указан, столбцу назначаются либо параметры сортировки пользовательского типа (если столбец принадлежит к пользовательскому типу данных), либо установленные по умолчанию параметры сортировки для базы данных.
- CONSTRAINT. Необязательное ключевое слово, указывающее на начало определения ограничения PRIMARY KEY, NOT NULL, UNIQUE, FOREIGN KEY или CHECK.
- constraint_name. Имя ограничения. Имена ограничений должны быть уникальными в пределах схемы, к которой принадлежит таблица.
- NULL | NOT NULL. Определяет, допустимы ли для столбца значения NULL. Параметр NULL не является ограничением в строгом смысле слова, но может быть указан так же, как и NOT NULL. Ограничение NOT NULL может быть указано для вычисляемых столбцов только в случае если одновременно указан параметр PERSISTED.
- PRIMARY KEY. Ограничение, которое обеспечивает сущностную целостность для указанного столбца или столбцов с помощью уникального индекса. Можно создать только одно ограничение PRIMARY KEY для таблицы.
- UNIQUE. Ограничение, которое обеспечивает сущностную целостность для указанного столбца или столбцов с помощью уникального индекса. Таблица может содержать несколько ограничений UNIQUE.
- CLUSTERED | NONCLUSTERED. Указывает, что для ограничения PRIMARY KEY или UNIQUE создается кластеризованный или некластеризованный индекс. Для ограничений PRIMARY KEY по умолчанию создается кластеризованный индекс ( CLUSTERED ), а для ограничений UNIQUE — некластеризованный ( NONCLUSTERED ).
В инструкции CREATE TABLE параметр CLUSTERED можно задать только для одного ограничения. Если для ограничения UNIQUE указан параметр CLUSTERED и, кроме того, указано ограничение PRIMARY KEY, то для PRIMARY KEY применяется по умолчанию значение NONCLUSTERED.
- FOREIGN KEY REFERENCES. Ограничение, которое обеспечивает ссылочную целостность данных в этом столбце или столбцах. Ограничения FOREIGN KEY требуют, чтобы каждое значение в столбце существовало в соответствующем связанном столбце или столбцах в связанной таблице. Ограничения FOREIGN KEY могут ссылаться только на столбцы, являющиеся ограничениями PRIMARY KEY или UNIQUE в связанной таблице, или на столбцы, на которые имеются ссылки в индексе UNIQUE INDEX связанной таблицы. Внешние ключи в вычисляемых столбцах должны быть также помечены как PERSISTED.
- [ schema_name . ] referenced_table_name ]. Имя таблицы, на которую ссылается ограничение FOREIGN KEY, и схема, к которой она принадлежит.
- ( ref_column [ ,... n ] ). Столбец или список столбцов из таблицы, на которую ссылается ограничение FOREIGN KEY.
-
ON DELETE { NO ACTION | CASCADE | SET NULL | SET DEFAULT }. Определяет операцию, которая производится над строками создаваемой таблицы, если эти строки имеют ссылочное отношение, а строка, на которую имеются ссылки, удаляется из родительской таблицы. Значение по умолчанию — NO ACTION.
- NO ACTION. Компонент Database Engine инициирует ошибку, и производится откат операции удаления строки родительской таблицы.
- CASCADE. Если из родительской таблицы удаляется строка, соответствующие ей строки удаляются из ссылающейся таблицы.
- SET NULL. Все значения, составляющие внешний ключ, при удалении соответствующей строки родительской таблицы устанавливаются в NULL. Для выполнения этого ограничения столбцы внешних ключей должны допускать существование значений NULL.
- SET DEFAULT. Все значения, составляющие внешний ключ, при удалении соответствующей строки родительской таблицы устанавливаются в значение по умолчанию. Для выполнения этого ограничения все столбцы внешних ключей должны иметь определения по умолчанию. Если столбец допускает значение NULL и множество значений по умолчанию не задано явно, NULL становится неявным значением по умолчанию для данного столбца.
-
ON UPDATE { NO ACTION | CASCADE | SET NULL | SET DEFAULT }. Указывает, какое действие совершается над строками в изменяемой таблице, когда эти строки связаны ссылкой и строка родительской таблицы, на которую указывает ссылка, обновляется. Значение по умолчанию — NO ACTION.
- NO ACTION. Компонент Database Engine возвращает ошибку, и обновление строки родительской таблицы откатывается.
- CASCADE. Соответствующие строки обновляются в ссылающейся таблице, если эта строка обновляется в родительской таблице.
- SET NULL. Всем значениям, составляющим внешний ключ, присваивается значение NULL, когда обновляется соответствующая строка в родительской таблице. Для выполнения этого ограничения столбцы внешних ключей должны допускать существование значений NULL.
- SET DEFAULT. Всем значениям, составляющим внешний ключ, присваивается их значение по умолчанию, когда обновляется соответствующая строка в родительской таблице. Для выполнения этого ограничения все столбцы внешних ключей должны иметь определения по умолчанию. Если столбец допускает значение NULL и множество значений по умолчанию не задано явно, NULL становится неявным значением по умолчанию для данного столбца.
- CHECK. Ограничение, обеспечивающее доменную целостность путем ограничения возможных значений, которые могут быть введены в столбец или столбцы. Ограничения CHECK в вычисляемых столбцах должны быть также помечены как PERSISTED.
- logical_expression. Логическое выражение, возвращающее значения TRUE или FALSE. Типы данных "псевдонимы" частью выражения быть не могут.
- Column. Столбец или список столбцов (в скобках), который применяется в ограничениях таблицы для указания столбцов, используемых в определении ограничения.
- [ ASC | DESC ]. Указывает порядок сортировки столбца или столбцов, участвующих в ограничениях таблицы: ASC — по возрастанию, DESC — по убыванию. Значение по умолчанию — ASC.
- partition_scheme_name. Имя схемы секционирования, определяющей файловые группы, которым сопоставляются секции секционированной таблицы. Эта схема секционирования должна существовать в БД.
- [ partition_column_name. ]. Указывает столбец, по которому будет секционирована таблица. Столбец должен соответствовать по типу данных, длине и точности столбцу, который указан в функции секционирования, используемой аргументом partition_scheme_name. Вычисляемый столбец, участвующий в функции секционирования, должен быть явно обозначен ключевым словом PERSISTED.
- WITH FILLFACTOR = fillfactor. Указывает, насколько плотно компонент Database Engine должен заполнять каждую страницу индекса, используемую для хранения данных индекса. Пользовательские значения аргумента fillfactor могут находиться в диапазоне от 1 до 100. Если значение не задано, по умолчанию оно принимается равным 0. Значения фактора заполнения 0 и 100 во всех отношениях считаются равнозначными.
- column_set_name XML COLUMN_SET FOR ALL_SPARSE_COLUMNS. Имя набора столбцов. Набор столбцов представляет собой нетипизированное XML-представление, в котором все разреженные столбцы таблицы объединены в структурированные выходные данные.
- < table_option> ::= Указывает один или более параметров таблицы.
- DATA_COMPRESSION. Задает режим сжатия данных для указанной таблицы, номера секции или диапазона секций. Ниже приведены доступные параметры.
- NONE. Таблица или указанные секции не сжимаются.
- ROW. Таблицы или указанные секции сжимаются, используя сжатие строк.
- PAGE. Таблицы или указанные секции сжимаются, используя сжатие страниц.
- ON PARTITIONS ( { <выражение_номера_секции> | <диапазон> } [ ,...n ] ). Указывает секции, к которым применяется параметр DATA_COMPRESSION. Если таблица не секционирована, аргумент ON PARTITIONS приведет к формированию ошибки. Если не указано предложение ON PARTITIONS, параметр DATA_COMPRESSION применяется ко всем секциям секционированной таблицы.
<Выражение_номера_секции> можно указать одним из следующих способов:
- указав номер секции, например: ON PARTITIONS (2) ;
- указав номера нескольких секций, разделив их запятыми, например: ON PARTITIONS (1, 5) ;
- указав диапазоны секций и отдельные секции, например: ON PARTITIONS (2, 4, 6 TO 8).
<Диапазон> можно указать номерами секций, разделенными ключевым словом TO, например: ON PARTITIONS (6 TO 8).
Чтобы для разных секций задать разные типы сжатия данных, укажите параметр DATA_COMPRESSION несколько раз:
- <index_option> ::= Указывает один или более параметров индекса (см. далее).
- PAD_INDEX = { ON | OFF }. Если указано значение ON, процент свободного места, определяемый параметром FILLFACTOR, применяется к страницам индекса промежуточного уровня. Если указано значение OFF или значение FILLFACTOR не указано, страницы промежуточного уровня заполняются до приблизительного объема, оставляющего достаточно места, как минимум, для одной строки максимального размера, которого может достигать индекс, при этом учитывается набор ключей на промежуточных страницах. Значение по умолчанию — OFF.
- FILLFACTOR = fillfactor. Указывает процентное соотношение, определяющее, насколько заполненным компонент Database Engine должен делать конечный уровень каждой страницы индекса при его создании или изменении. Аргумент fillfactor должен быть целым числом в диапазоне от 1 до 100. Значение по умолчанию равно 0. Значения фактора заполнения 0 и 100 во всех отношениях считаются равнозначными.
-
IGNORE_DUP_KEY = { ON | OFF }. Определяет ответ на ошибку, случающуюся, когда операция вставки пытается вставить в уникальный индекс повторяющиеся значения ключа. Параметр IGNORE_DUP_KEY применяется только к операциям вставки, производимым после создания или перестроения индекса. Параметр не работает во время выполнения инструкции CREATE INDEX, ALTER INDEX или UPDATE. Значение по умолчанию — OFF.
- ON. Если в уникальный индекс вставляются повторяющиеся значения ключа, выводится предупреждающее сообщение. С ошибкой завершаются только строки, нарушающие ограничение уникальности.
- OFF. Если в уникальный индекс вставляются повторяющиеся значения ключа, выводится сообщение об ошибке. Будет выполнен откат всей операции INSERT.
- IGNORE_DUP_KEY. Нельзя установить в значение ON для индексов, создаваемых для представлений, неуникальных индексов, XML-индексов, пространственных индексов и фильтруемых индексов.
- STATISTICS_NORECOMPUTE = { ON | OFF }. Если указано значение ON, автоматический пересчет устаревших статистик индекса не производится. Если указано значение OFF, включается автоматическое обновление статистик. Значение по умолчанию — OFF.
- ALLOW_ROW_LOCKS = { ON | OFF }. Если указано значение ON, при доступе к индексу допустимы блокировки строк. Необходимость в блокировке строк определяет компонент Database Engine. При значении OFF блокировки строк не используются. Значение по умолчанию — ON.
- ALLOW_PAGE_LOCKS = { ON | OFF }. Если указано значение ON, при доступе к индексу допустимы блокировки страниц. Необходимость в блокировке строк определяет компонент Database Engine. При значении OFF блокировки страниц не используются. Значение по умолчанию — ON.
Выше было дано описание аргументов команды CREATE TABLE. В настоящей лекции мы будем обсуждать не все из перечисленных аргументов. Секционирование таблиц будет рассмотрено в "Метаданные в хранилищах данных" . Сейчас мы остановимся на использовании ограничений.
Владислав Нагорный
Лариса Парфенова
|
1) Можно ли экстерном получить второе высшее образование "Программная инженерия" ? 2) Трудоустраиваете ли Вы выпускников? 3) Можно ли с Вашим дипломом поступить в аспирантуру?
|