Введение
2.2 Улучшение времени реакции серверных приложений
Главные характеристики большинства серверов приложений – это среднее время исполнения запроса и количество запросов, обрабатываемых в единицу времени. Это две разные характеристики.
Среднее время исполнения запроса – это основная характеристика производительности сервера с точки зрения отдельного пользователя. Увеличение этого времени ведет к снижению производительности пользователя, ему приходится тратить больше времени на исполнение тех же самых задач. Кроме того, слишком большое время реакции системы попросту раздражает пользователей.
Количество запросов, обрабатываемых в единицу времени – это основная характеристика производительности сервера с точки зрения владельца этого сервера. Если мы найдем способ увеличить это количество, не ухудшив или незначительно ухудшив показатели исполнения отдельных запросов, мы сможем подключить к серверу больше пользователей. Таким образом, владелец сервера может сэкономить на приобретении оборудования.
Рассмотрим процесс исполнения одиночного запроса типичным серверным приложением (см. рис. 1.1). Он состоит из пяти этапов: приема запроса (выполняется сетевым интерфейсом), анализа запроса (выполняется центральным процессором), считывания данных с диска (выполняется дисковым контроллером), создания ответа (выполняется центральным процессором) и передачи ответа. Разумеется, времена исполнения этих этапов могут различаться в зависимости от типа сервиса, предоставляемого сервером, и от самих запросов. Для сервера http, раздающего статические HTML страницы, время анализа запроса и форматирования ответа будет очень малым по сравнению с временами чтения с диска и передачи данных по сети. Напротив, у сервера приложений основная нагрузка ляжет на центральный процессор. Серверу баз данных может потребоваться несколько обращений к диску для того, чтобы найти все относящиеся к запросу данные, и т.д.. Тем не менее, давайте рассмотрим условный сервер, обрабатывающий однотипные запросы, у которых структура обработки запроса именно такова, как на рис. 1.1, а времена исполнения всех этапов одинаковы (последнее требование нужно лишь для того, чтобы мне было проще рисовать картинку).
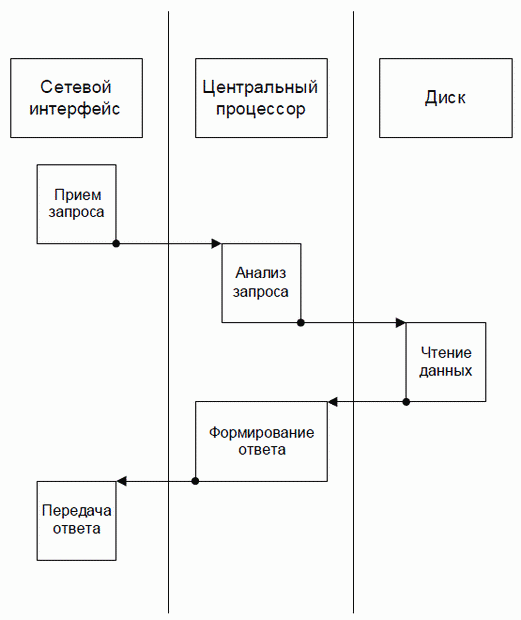
Рассмотрим теперь исполнение потока запросов. Однопоточный сервер должен был бы исполнять запросы строго последовательно, поэтому максимальное количество запросов, исполняемых в секунду, было бы равно 1/t, где t – время исполнения одиночного запроса.
При этом среднее время исполнения запроса не будет равно t, а будет расти в зависимости от вероятности перекрытия запросов во времени. Теоретико-вероятностные расчеты и практика показывают, что когда поток запросов приближается к 1/t в секунду, эта вероятность становится весьма значительной, так что время исполнения одиночного запроса может увеличиться во много раз. Однако к многопоточному серверу эти расчеты неприменимы. Рассмотрим, как многопоточный сервер мог бы обрабатывать поток запросов (см. рис. 1.2).
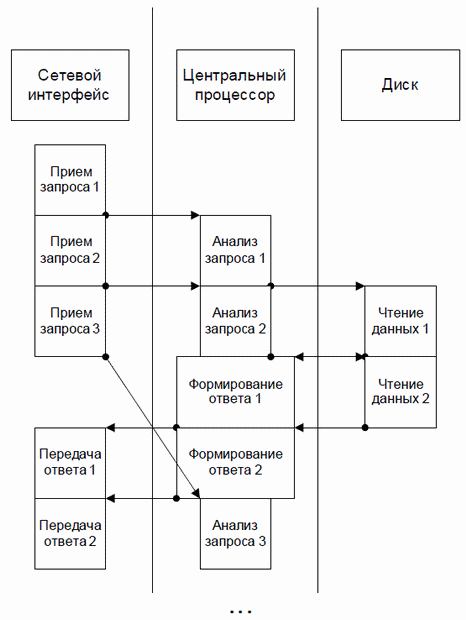
Видно, что сервер совмещает этапы исполнения перекрывающихся во времени запросов. Если относительные времена исполнения этапов запросов таковы, как на рис. 1.1 и рис. 1.2, избежать взаимодействия запросов не удается, так что среднее время исполнения запроса может вырасти по сравнению с t. Но количество запросов, исполняемых в секунду, оказывается значительно больше, чем 1/t.
Более того, видно, что мы могли бы повысить производительность системы, установив второй процессор и второй сетевой интерфейс.
Однако переделка однопоточного серверного приложения в многопоточное требует специальной поддержки со стороны операционной системы и значительной переработки кода приложения. Все современные ОС общего назначения – Sun Solaris, другие системы семейства Unix, IBM zOS, Win 32 и Win 64 – обеспечивают соответствующую поддержку, но далеко не все разработчики приложений умеют этой поддержкой пользоваться.
3. Проблемы многопоточности
Первые попытки организации параллельных вычислений предпринимались еще в 60е годы XX столетия. Теория межпроцессного и многопоточного взаимодействия была в основном разработана еще тогда, однако массовое распространение многопоточное программирование получило лишь в 90е годы. Это было обусловлено рядом причин, основные из которых перечислены ниже:
- Несовместимость со старыми (однопоточными) компиляторами
- Несовместимость со старыми библиотеками
- Несовместимость или ограниченная поддержка многопоточных программ другими инструментальными средствами, в первую очередь отладчиками
- Несовместимость многих принятых практик программирования с многопоточностью.
Первые три из названных причин чисто технические, для их решения требуется переработка инструментальных средств разработки программ. Однако, поскольку такая переработка нарушает совместимость, массовый переход на новый инструментарий занял многие годы. К тому же, поскольку первые версии многопоточных инструментальных средств обладали различными недостатками, это также затрудняло их принятие разработчиками.
Первые среды программирования, реализовавшие многопоточность, такие, как Simula 67, использовали для создания потоков и межпоточного взаимодействия специальные конструкции языка. Эта традиция продолжалась и до 80х годов и воплощена в таких языках, как Ada, Occam, Parallel Fortran. Пожалуй, только последний из этих языков –Parallel Fortran – получил широкое практическое применение.
При программировании на C / C++ с использованием POSIX Thread Library специальные компиляторы не требуются. POSIX Thread Library можно использовать с любыми компиляторами, реализующими соглашения о вызовах, соответствующие ABI вашей аппаратной платформы. Так, в Solaris 10 многопоточные программы можно писать как на GNU C, так и с помощью Sun Studio C compiler. Все, необходимое для поддержки многопоточности, реализовано на уровне библиотек.
Sun Studio 11 C compiler также поддерживает средства для параллельного программирования OpenMP. При компиляции с ключом -xopenmp включается поддержка директив параллелизации OpenMP в исходном коде программы. При компиляции с ключом -xautopar компилятор пытается автоматически найти параллелизуемые участки в программе и реализовать их многопоточное исполнение. OpenMP в Solaris реализован на основе тех же технологий, что и POSIX Threads, поэтому следует проявлять осторожность при совместном использовании OpenMP и POSIX Threads в одной программе. В рамках данного курса OpenMP не рассматривается. Более сложной проблемой на практике оказалась поддержка многопоточности на уровне библиотек. Проблемы, возникающие со старыми библиотеками, в основном описываются на следующей лекции, но полный масштаб этих проблем станет вам понятен лишь после завершения курса в целом. Первые реализации стандартных библиотек C и Fortran для Unix-систем были рассчитаны на однопоточное исполнение, поэтому перенос в многопоточную среду потребовал их переработки. Первые версии C и С++ компиляторов для старых Unix-систем (как и старые реализации C / C++ для OS/2 и Win 32) использовали две разные версии библиотек для однопоточных и многопоточных программ.
В Solaris 10 в основном завершена переработка стандартных библиотек языка C для оптимальной поддержки многопоточности. Стандартная библиотека /usr/lib/libc.so и основная масса других библиотек, входящих в стандартную поставку системы, работают как в однопоточных, так и в многопоточных программах. Тем не менее, эта поддержка до сих пор сопряжена с некоторыми ограничениями. Многие функции, в том числе некоторые функции стандартных библиотек ANSI/ISO C в многопоточных программах следует использовать с осторожностью. Необходимая информация приводится в секции ATTRIBUTES страниц системного руководства (man(1)) по соответствующим функциям. Подробнее этот вопрос обсуждается на следующей лекции.
При использовании библиотек других поставщиков необходимо получить информацию о поддержке многопоточности у поставщика библиотеки. Обычно эта информация должна указываться в документации по библиотеке, но, к сожалению, не все разработчики библиотек это делают. Поддержка многопоточной отладки – также относительно недавнее достижение. В современных версиях популярного отладчика gdb (GNU Debugger) многопоточность поддерживается, но при сборке отладчика ее можно выключить, поэтому до сих пор нередко можно встретить бинарный дистрибутив gdb без поддержки многопоточности. Для проверки, поддерживает ли ваша версия gdb многопоточность, следует исполнить команду info threads. Если поддержка включена, эта команда выводит список нитей отлаживаемой программы, если выключена — команда игнорируется отладчиком.
gdb) info threads
3 process 35 thread 27 0x34e5 in sigpause ()
2 process 35 thread 23 0x34e5 in sigpause ()
* 1 process 35 thread 13 main (argc=1, argv=0x7ffffff8) at threadtest.c:68
1.1.
В поставку Sun Studio 11 входит отладчик dbx, который полностью поддерживает многопоточную отладку как в режиме командной строки, так и в экранном режиме под управлением Sun Studio IDE. Некоторые сведения об этом отладчике сообщаются в нашем курсе.