Опубликован: 23.10.2009 | Доступ: свободный | Студентов: 2830 / 109 | Оценка: 4.28 / 4.22 | Длительность: 17:27:00
Специальности: Программист
Лекция 11:
Регулярные выражения
File Find
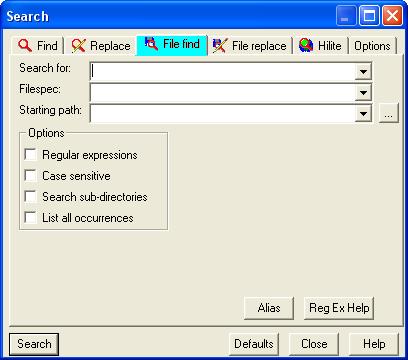
Назначение. Поиск подстроки в группе файлов.
Опции.
- Поиск с использованием Литералов/Регулярных выражений:
- Поиск только всего слова (а не фрагмента);
- При поиске игнорируется регистр букв (флажок " Ignore Case ");
- Выдать запрос на дальнейший поиск (флажок " Prompted to next find ");
- Поиск файлов не только в заданном каталоге, но и во всех его подкаталогах (флажок " Include subtree ");
- и другие, менее важные опции.
Запрос пишется в верхней строке. Ниже задается шаблон файлов для поиска, а еще ниже - начальная директория для поиска. Запускается команда после выбора кнопки " OK " или нажатия клавиши " Enter ".
File Replace
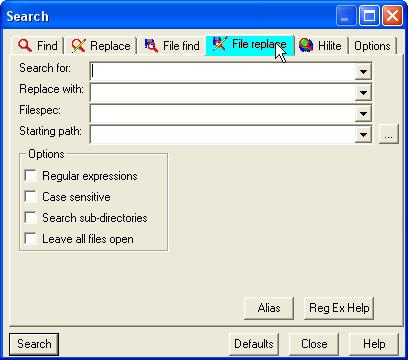
Назначение. Поиск и замена подстроки на заданный фрагмент в группе файлов.
Опции.
- Поиск с использованием Литералов/Регулярных выражений:
- Поиск только всего слова (а не фрагмента);
- При поиске игнорируется регистр букв (флажок " Ignore Case ");
- Выдать запрос на дальнейший поиск/замену (флажок " Prompted to next find ");
- Поиск файлов не только в заданном каталоге, но и во всех его подкаталогах (флажок " Include subtree ");
- и другие, менее важные опции.
Запрос пишется в верхней строке ( Find ), за ней следует строка ( Replace ) для задания фрагмента для замены. Ниже задается шаблон файлов для поиска, а еще ниже - начальная директория для поиска. Запускается команда после выбора кнопки " OK " или нажатием на клавишу " Enter ".
Реализация команд в скрипте.
Команды " File Find… " и " File Replace… " в скриптовом языке не реализованы.
Команда " Find " реализована в скриптовом языке в виде двух функций: SEARCH_FWD для поиска вперед по файлу и SEARCH_BWD для поиска назад по файлу (к его началу). Обе функции имеют одинаковое число и смысл параметров. Их синтаксис:
SEARCH_???(<строка поиска>,<число строк>),Листинг 11.1.
где <строка поиска> - фрагмент для поиска (может содержать шаблоны и регулярные выражения), а <число строк> указывает, сколько строк текста используется для поиска (целое число). Если <число строк> = 0, то поиск будет осуществляться до конца (начала) файла.
Любой найденный фрагмент можно заменить другим фрагментом функцией REPLACE с синтаксисом:
REPLACE(<строка замены>)Листинг 11.2.
<строка замены> имеет те же свойства и требования, что и фрагмент замены в команде " Replace… " редактора.
Кроме того, при поиске и замене используются значения глобальных переменных: " REG_EXP_STAT " (допускающей регулярные выражения при поиске, если она установлена) и " IGNORE_CASE " (игнорирующая при поиске регистр латинских букв, если она установлена). Их необходимо устанавливать или сбрасывать до обращения к функциям SEARCH_FWD и SEARCH_BWD.
11.3. Регулярные выражения в Perl и Linux
Операционная система Linux не ограничивается реализацией регулярных выражений, приведенных в п. 11.2.2. Да, такие регулярные выражения полезны при файловых операциях в командной строке. Но как тогда быть с обработкой файлов конфигураций, так "полюбившимся" Linux? Тут требуются другие средства.
И такие средства были созданы! Это, прежде всего, потоковый фильтр sed и, конечно же, язык программирования Perl. Позже появились и Windows версии этих программ. Поскольку реализация в них операций поиска и замены строк с использованием регулярных выражений очень похожи, мы опишем их в едином блоке.
Поиск подстроки в строке на языке Perl осуществляется следующим образом:
[<исходная строка> =~ ]m/<образец>/<опции>Листинг 11.3.
а замена - следующим образом:
[<исходная строка> =~ ]s/<образец>/[<замена>]/<опции>Листинг 11.4.
где <исходная строка> - строка, в которой осуществляют поиск. Если она не указана, используется переменная $_ в Perl или очередная строка файла в sed. <образец> - подстрока (шаблон), который ищется в исходной строке (о нем пойдет речь ниже). <замена> - подстрока, которой заменяется данный образец. Если этот пункт опущен, то найденный образец удаляется из текущей строки. <опции> - определяют режимы поиска или замены. Наиболее важные из них:
- i - игнорирование регистра латинских символов;
- g - глобальная замена (заменяются все образцы, найденные в строке, а не только первый из них).
Более подробно об опциях команд см. [59] и таблицу 11.2.
В образце можно использовать следующие метасимволы:
- \s - все пробельные символы;
- \d - аналогичен регулярному выражению: [0-9];
- \w - аналогичен регулярному выражению: [0-9A-Za-z];
- \A - начало строки;
- \Z - конец строки;
- \\ - бэкслеш;
- . - обозначает любой одиночный символ, кроме символа новой строки. Так, образцу /.+/ соответствует любая непустая строка.
- […] - пара квадратных скобок используется для представления любого одиночного символа из числа заключенных в скобки;
- ^ - символ внутри квадратных скобок используется для представления любого одиночного символа не из числа заключенных в скобки;
- $ - если этот знак расположен в конце выражения, то он указывает на конец строки;
- ^ - если знак расположен в начале выражения, то он указывает на его начало. Например: /^$/ - пустая строка;
- | - метасимвол-аналог оператора: "ИЛИ" в логическом выражении, означает альтернативу;
- (…) - выражение в скобках, во-первых, задает приоритет операций выбора, а во-вторых, определяет переменные замены: $1, $2, … $nn. Так, переменной $1 присваивается найденное содержимое первой скобки (..), $2 - второй (…) и т.д.;
- * - коэффициент, указывающий, что предыдущий символ повторяется от нуля до бесконечности;
- + - коэффициент, указывающий, что предыдущий символ повторяется один или более число раз;
- ? - коэффициент повторения 0 или 1 раз;
- {n} - коэффициент ровно n повторений;
- {n,m} - коэффициент повторения символа от n до m раз;
- \xnn - символ с шестнадцатеричным значением nn;
- \b - граница слова;
- \G - обозначает точку, в которой закончился предыдущий поиск m//g;
- и др.
В строке <замена> можно использовать все обычные символы, метасимволы \\, \xnn, а также все "маскирующие" знаки и переменные: $1, $2, … $nn. Например: s/^(\w+)\s(\w+)/$2\x20$1/ - меняет местами в начале строки два слова.
Примеры регулярных выражений:
- /.*/ - любая строка;
- /.+/ - любая непустая строка;
- /^$/ - пустая строка;
- /^(\w+)\s(\w+)$/ - строка из двух слов;
- /^Perl./ - строка, начинающаяся с Perl;
- /.Perl$/ - строка, заканчивающаяся Perl;
- /(\w+)\s?=\s?(\w+)\s*$/ - элемент (ключ = значение) файла конфигурации Linux;
- /\[(\w+)\]\s*\$/ - элемент [Раздел] файла конфигурации Linux;
- /\w{1,6}/ - идентификатор максимум из 6 символов.
11.4. Примеры регулярных выражений
В архивах, расположенных на [http://yudenisov.narod.ru/SOURCECODE/] моем сайте, приведены примеры регулярных выражений, превращающих текстовый файл в HTML-документ по определенным шаблонам. Примеры написаны на языках Си, Perl, Multi Edit Script, распространяются по лицензии GNU GPL. Также на них есть документация, распространяемая на условиях Copyleft.
11.5. Резюме
В данной лекции Вы познакомились с основными правилами записи и применения регулярных выражений. Вы узнали, что такое "символ", "модификатор", а также работу с регулярными выражениями в оболочках операционных систем, текстовых редакторах и "скриптовых" языках программирования.
После прочтения этой лекции Вы можете не только читать, но и писать свои собственные программы с использованием регулярных выражений. Изучите эту лекцию и глоссарий к ней, чтобы потом у Вас не было пробелов знаний при использовании регулярных выражений.