Опубликован: 23.10.2009 | Доступ: свободный | Студентов: 2826 / 108 | Оценка: 4.28 / 4.22 | Длительность: 17:27:00
Специальности: Программист
Лекция 9:
Грамматика
Аннотация: Целью данной лекции является ознакомление студентов с современными программами и алгоритмами вывода, применяемых при выводе утверждений и "доказательств целей" в алгоритмах искусственного интеллекта. Также в ней даётся описание некоторых "моделей" искусственного интеллекта применительно к символьным вычислениям, в частности, разбора предложения на английском языке.
Ключевые слова: представление знаний, логический вывод, Формальной грамматикой, 1-грамматика, логическое программирование, дерево вывода, семантическая сеть, высокая технология, транслятор, EAT, ATE, ball, goal, списки значений, система продукций, степень доверия, прогон тестов, средняя сложность, терминальный символ, нетерминальный символ, метод проб и ошибок, леворекурсивная грамматика, входная информация, выходная информация, лексема, pre, GNU, GPL, copyleft, техническое задание, экспертная система, коммутативность, операция конкатенации, метасимволы, понимание текста, член группы, словосочетание, условие ветвления, тестирование программы, реализация языка, logically, процедурный язык
"ИСКУССТВЕННЫЙ ИНТЕЛЛЕКТ, раздел информатики, включающий разработку методов моделирования и воспроизведения с помощью ЭВМ отдельных функций творческой деятельности человека, решение проблемы представления знаний в ЭВМ и построение баз знаний, создание экспертных систем, разработку т. н. интеллектуальных роботов"
Цель лекции:
- Дать читателю представление о дисциплине: "искусственный интеллект";
- Ознакомить его с понятиями: "логический вывод", "продукция", "правила подстановки";
- Ознакомить читателя с основными положениями формальной грамматики, понятиями: "однозначная грамматика" и "синтаксическое дерево";
- Научить его пользоваться регулярными выражениями;
- Дать базовые знания для последующего изучения языков логического программирования.
До сих пор мы занимались простейшими операциями со строками - комбинацией строк и их выводом. Если бы все символьные вычисления ограничивались этим набором операций, то не пришлось бы писать эту книгу. На самом деле, "настоящие" символьные вычисления включают в себя синтаксические деревья, деревья вывода, грамматический разбор, поиск и замену текста, синтез текста и другие задачи "искусственного интеллекта". В этой части автор слегка "коснётся" этой темы в плане теории и простейших реализаций.
9.1. Введение
К символьным операциям относят:
- Операцию ввода-вывода строк;
- Конкатенацию (объединение) строк;
- Поиск по шаблону;
- Замену в тексте строки по заданному образцу;
- Грамматический, синтаксический и др. разбор текста;
- Прямой вывод;
- Обратный вывод;
- Построение "деревьев вывода";
- Семантический анализ текста;
- Построение фреймов и семантических сетей;
- Синтез "связной речи";
- И многое другое.
Эти задачи гораздо сложнее, чем численные расчёты на ЭВМ. К тому же научно они менее разработаны, чем численные методы. Но именно за символьными вычислениями - будущее отрасли высоких технологий.
Символьные операции могут применяться, например:
- При подготовке и рассылке электронной корреспонденции;
- При поиске во всемирной сети;
- При наборе и вёрстке текста;
- При проверке орфографии и стиля документа;
- При переводе текста с языка на язык (имеются в виду как "человеческие", так и "машинные" языки);
- При осуществлении "теста Тьюринга";
- В датамайнинге;
- При автоматической коррекции текста и перевода его из формата в формат;
- При разработке языков программирования и написании их трансляторов и компиляторов для них;
- и т.д.
Это - пример тех немногих областей человеческой деятельности, где применяются символьные вычисления искусственного интеллекта. Основы этих вычислений будут рассмотрены в этом разделе.
9.2. Построение деревьев вывода
Для начала рассмотрим игру "Животные", приведённую в [64]. Вот диалог работы с этой программой:
[Пример 01]
- "Это кот?" - "Нет".
- "Сдаюсь, кто это?" - "кит".
- "Чем отличается кот от кит?" - "плавает в море".
- "Сыграем ещё?" - "Да".
- "Он плавает в море?" - "Нет".
- "Это кот?" - "Нет".
- "Сдаюсь, кто это?" - "студент".
- "Чем отличается кот от студент?" - "ходит на лекцию".
- "Сыграем ещё?" - "Да".
- "Он плавает в море?" - "Нет".
- "Он ходит на лекцию?" - "Да".
- "Это студент?" - "Нет".
- "Сдаюсь, кто это?" - "профессор".
- "Чем отличается студент от профессор?" - "читает лекции".
- …
Этот диалог формирует следующее дерево (см. рисунок 9.1):

В этом дереве имеется "корень" - название игры ("животные"). От него исходят так называемые "бинарные ветви" - ветви, которым соответствуют ответы: "Да" или "Нет". Это дерево является моделью, полностью описывающее состояние игры: "Животные". С помощью этого дерева можно ответить на вопросы:
- Сколько необходимо задать вопросов, чтобы получить ответ: "студент"?
- Кто является "соседней ветвью" ответа: "студент"?
- Присутствует ли ответ: "студент" - в дереве вывода?
- Много ли не заполненных ветвей дерева (обозначенных: "Кто это")?
Для ответа на эти вопросы необходимо обойти дерево вывода в любой последовательности. Порядок (алгоритм обхода) не влияет на результат, но определяет эффективность работы программы.
Вот другой пример дерева вывода, вид которого представлен на рисунке 9.2. Рассмотрим грамматический разбор английского предложения: "The big elephant will eat pineapples tomorrow". ("Большой слон будет есть ананасы завтра").
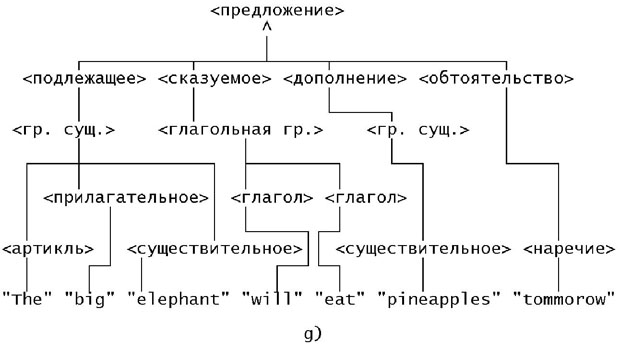
Как известно читателям, изучавшим английский язык, структура английского предложения является жёсткой и имеет следующий вид:
<Подлежащее><Сказуемое>[<Прямое дополнение>][<Обстоятельство>]Листинг 9.1.
Подлежащее может быть только группой существительного, как и прямое дополнение, а сказуемое - основным и дополнительным глаголом. Группа существительных состоит из артикля, необязательного определения (прилагательного) и существительного (или местоимения). Обстоятельства являются группами существительного или наречиями.
В принципе, в этом предложении можно менять существительные и глаголы - это не должно влиять на правильность разбора предложения. Например, правильными также будут следующие предложения:
Однако второе предложение бессмысленно (кому-то оно может показаться даже непристойным). Это объясняется тем, что мы не рассматривали "осмысленность" предложения при выводе. Автор должен отметить, что задачи искусственного интеллекта понимания смысла текста и "осмысленного" генерирования предложений не решены уже более 50 лет (время появления первых ЭВМ с современной архитектурой). В основном из-за того, что до сих пор нет ответа на вопрос: "Что такое смысл"? Но это уже отступление от темы.
Итак, мы рассмотрели два дерева вывода, выяснили, насколько это "дерево" полезно при разборе и построении предложений, открыли новые возможности символьных вычислений. Однако построение всех деревьев вывода и анализ их человеком обычно очень трудная, если не сказать, "неподъёмная" задача. Нельзя ли оптимизировать выполнение этих задач? Можно! Об этом - в следующем подразделе.
9.3. Прямой и обратный вывод
Любой логический вывод основан на фактах, правилах (или продукциях). Факты могут быть представлены следующим образом:
[Пример 02]
/* Массиву строковых переменных names присвоены значения (язык Си плюс-плюс) */
names[0] = "Галя"; names[1] = "Нина"; names[2] = "Петя";
/* То же определение на языке Turbo Prolog */
names("Галя"); names("Нина"); names("Петя");
/* Определение массивов строковых переменных article (все возможные английские артикли) (C++) */
article[0] = ""; article[1] = "the"; article[2] = "a"; article[3] = "an";Правила же определяются следующим образом:
[Пример 03]
/* Пример на C++ */ if( names[i] == "Галя" ) woman.name = names[i]; /* Пример на Turbo Prolog */ woman( N ) if N == "Галя" оr N == "Нина", name(N);
Выводом же будет автоматическое доказательство некоторого предположения, определённого как истинность одного из правил. Это правило называют "целью" вывода (по-английски: "goal"). При выборе цели возможно нахождение одного, нескольких или ни одного решения - списка значений переменных, участвующих в выводе.
Примечание. Множество решений - это, практически, множество предложений заданной грамматики, полученных в результате доказательства цели вывода. Определение грамматики см. раздел 2 лекции 10.
Когда написаны все факты и правила, необходимо написать алгоритм вывода. Он может быть одним из следующих:
- Вывод на основе системы продукций (или "нейронной сети");
- Вывод на основе правил (стандартный алгоритм вывода по прямой цепочке рассуждений);
- Вывод на основе правил (стандартный алгоритм вывода по обратной цепочке рассуждений).
Рассмотрим их поподробнее.
9.3.1. Система продукций (и "нейронные сети")
Вывод на основе системы продукций следующий:
- Определяются и вводятся "факты", на основе которых делается вывод;
- Описываются промежуточные переменные вывода и цель вывода;
- Составляется набор правил (продукций), последовательно задающие значения промежуточным переменным;
Внимание! Порядок записи продукций имеет значение.
- В процессе написания продукций в текст вставляются операторы вывода значений переменных, когда это необходимо;
- В процессе работы системы продукций с реализацией "нечёткой логики" (по-другому: "нейронной сети") каждой продукции соответствует "коэффициент уверенности", который отражает степень доверия к этой продукции. Он вычисляется на основе коэффициентов уверенности доказанных фактов, правил, и коэффициента уверенности самой продукции.
После написания программы начинается этап её тестирования (или "настройки нейронных сетей" для нейронных сетей). На этом этапе можно менять порядок правил (продукций) и коэффициентов уверенности (для нейронных сетей). При этом новые правила не вносятся, а старые правила не удаляются, (это грозит целостности программы). Тестирование заканчивают, когда система продукций или нейронная сеть будет адекватно обрабатывать входные данные и выдавать приемлемые результаты.
Преимущества системы продукций и нейронных сетей:
- Высокая скорость работы, позволяющая обрабатывать данные в "реальном масштабе времени";
- Относительно простая реализация алгоритма в "процедурных" языках;
- Время работы программы пропорционально числу продукций в ней.
Недостатки этих систем:
- Они не подходят для кодирования "стандартным алгоритмом вывода". Программист должен реализовывать "с нуля" алгоритм нейронной сети или системы продукций.
- Невозможность предсказать поведение работающей программы;
- Сложность отладки. Для отладки необходимо при прогоне тестов менять только один параметр. Это делает отладку длительной по времени.
- Система продукций - это "чёрный ящик", не дающий пользователю объяснений о ходе своих рассуждений.
Примечание. Информацию о коэффициентах уверенности, их расчёту и применении смотри, например, в [57].