|
Не могу найти требования по оформлению выпускной контрольной работы по курсу профессиональной переподготовки "Менеджмент предприятия" |
Опубликован: 16.12.2009 | Доступ: свободный | Студентов: 2581 / 435 | Оценка: 4.26 / 4.23 | Длительность: 33:53:00
Темы: Экономика, Менеджмент
Специальности: Руководитель, Экономист
Лекция 5:
Многомерный статистический анализ
Основные понятия теории классификации
При внедрении современных эконометрических и статистических методов в практику технико-экономических исследований, при разработке соответствующих программных продуктов невозможно обойтись без классификации этих методов. Естественно исходить из вида обрабатываемых данных. В соответствии с современными воззрениями делим эконометрику и прикладную статистику на четыре области:
- статистика случайных величин (одномерная статистика);
- многомерный статистический анализ;
- статистика временных рядов и случайных величин;
- статистика объектов нечисловой природы.
В первой области элемент выборки - число, во второй - вектор, в третьей - функция, в четвертой - объект нечисловой природы. Термин "объект нечисловой природы" относится к элементам математического пространства, не являющегося векторным (линейным). Их нельзя складывать, умножать на числа, в отличие от чисел, векторов и функций. Примерами являются бинарные отношения (упорядочения, разбиения на классы, толерантности); множества, нечеткие множества; результаты измерений в номинальной и порядковой шкалах (т.е. по качественным признакам), в частности булевы вектора; вектора разнотипных признаков; тексты и т.д. (подробнее см., например, "Статистика нечисловых данных" ).
Математический аппарат статистики объектов нечисловой природы базируется на использовании расстояний (мер близости, показателей различия) в пространствах таких объектов. Это вызвано отсутствием в таких пространствах операций суммирования, на которых основано большинство методов других областей статистики. Любые методы, использующие только расстояния (меры близости, показатели различия) между объектами, следует относить к статистике объектов нечисловой природы, поскольку такие методы могут работать с объектами произвольного пространства, если в нем задана метрика или ее аналоги.
Таким образом, весьма многие математические методы классификации объектов или признаков следует включать в статистику объектов нечисловой природы. Она является уже весьма развитой области прикладной математики. Ей посвящено несколько тысяч статей и книг.
В настоящем пункте рассматривается важное направление эконометрики и прикладной статистики - математические методы классификации. Основная их часть относится к статистике объектов нечисловой природы, а именно, методы классификации, основанные на расстояниях между объектами.
Основные направления в математической теории классификации. Какие научные исследования относить к этой теории? Исходя из потребностей специалиста, применяющего математические методы классификации, целесообразно принять, что сюда входят исследования, во-первых, отнесенные самими авторами к этой теории; во вторых, связанные с ней общностью тематики, хотя бы их авторы и не упоминали термин "классификация". Это предполагает ее сложную внутреннюю структуру.
В литературных источниках наряду с термином "классификация" в близких смыслах используются термины "группировка", "распознавание образов", "диагностика", "дискриминация", "сортировка" и др. Терминологический разнобой связан прежде всего с традициями научных кланов, к которым относятся авторы публикаций, а также с внутренним делением самой теории классификации.
В научных исследованиях по современной теории классификации можно выделить два относительно самостоятельных направления. Одно из них опирается на опыт таких наук, как биология, география, геология, и таких прикладных областей, как ведение классификаторов продукции и библиотечное дело. Типичные объекты рассмотрения - классификация химических элементов (таблица Д.И. Менделеева), биологическая систематика, универсальная десятичная классификация публикаций (УДК), классификатор товаров на основе штрих-кодов.
Другое направление опирается на опыт технических исследований, экономики, маркетинговых исследований, социологии, медицины. Типичные задачи - техническая и медицинская диагностика, а также, например, разбиение на группы отраслей промышленности, тесно связанных между собой, выделение групп однородной продукции. Обычно используются такие термины, как "распознавание образов" или "дискриминантный анализ". Это направление обычно опирается на математические модели; для проведения расчетов интенсивно используется ЭВМ. Однако относить его к математике столь же нецелесообразно, как астрономию или квантовую механику. Рассматриваемые математические модели можно и нужно изучать на формальном уровне, и такие исследования проводятся. Но направление в целом сконцентрировано на решении конкретных задач прикладных областей и вносит вклад в технические или экономические науки, медицину, социологию, но, как правило, не в математику. Использование математических методов как инструмента исследования нельзя относить к чистой математике.
В 60-х годах XX века внутри прикладной статистики достаточно четко оформилась область, посвященная методам классификации. Несколько модифицируя формулировки М. Дж. Кендалла и А. Стьюарта 1966 г. (см. русский перевод [7, с.437]), в теории классификации выделим три подобласти: дискриминация (дискриминантный анализ), кластеризация (кластер-анализ), группировка. Опишем эти подобласти.
В дискриминантном анализе классы предполагаются заданными - плотностями вероятностей или обучающими выборками. Задача состоит в том, чтобы вновь поступающий объект отнести в один из этих классов. У понятия "дискриминация" имеется много синонимов: диагностика, распознавание образов с учителем, автоматическая классификация с учителем, статистическая классификация и т.д.
При кластеризации и группировке целью является выявление и выделение классов. Синонимы: построение классификации, распознавание образов без учителя, автоматическая классификация без учителя, таксономия и др. Задача кластер-анализа состоит в выяснении по эмпирическим данным, насколько элементы "группируются" или распадаются на изолированные "скопления", "кластеры"(от cluster (англ.) - гроздь, скопление). Иными словами, задача - выявление естественного разбиения на классы, свободного от субъективизма исследователя, а цель - выделение групп однородных объектов, сходных между собой, при резком отличии этих групп друг от друга.
При группировке, наоборот, "мы хотим разбить элементы на группы независимо от того, естественны ли границы разбиения или нет" [7, с.437]. Цель по-прежнему состоит в выявлении групп однородных объектов, сходных между собой (как в кластер-анализе), однако "соседние" группы могут не иметь резких различий (в отличие от кластер-анализа). Границы между группами условны, не являются естественными, зависят от субъективизма исследователя. Аналогично при лесоустройстве проведение просек (границ участков) зависит от специалистов лесного ведомства, а не от свойств леса.
Задачи кластеризации и группировки принципиально различны, хотя для их решения могут применяться одни и те же алгоритмы. Важная для практической деятельности проблема состоит в том, чтобы понять, разрешима ли задача кластер-анализа для конкретных данных или возможна только их группировка, поскольку они достаточно однородны и не разбиваются на резко разделяющиеся между собой кластеры.
Как правило, в математических задачах кластеризации и группировки основное - выбор метрики, расстояния между объектами, меры близости, сходства, различия. Хорошо известно, что для любого заданного разбиения объектов на группы и любого  можно указать метрику такую, что расстояния между объектами из одной группы будут меньше
можно указать метрику такую, что расстояния между объектами из одной группы будут меньше 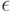 , а между объектами из разных групп - больше
, а между объектами из разных групп - больше  . Тогда любой разумный алгоритм кластеризации даст именно заданное разбиение.
. Тогда любой разумный алгоритм кластеризации даст именно заданное разбиение.
Ситуация осложняется использованием одного и того же термина в разных смыслах. Термином "классификация" (и термином "диагностика") обозначают, по крайней мере, три разные вещи: процедуру построения классификации (и выделение классов, используемых при диагностике), построенную классификацию (систему выделенных классов) и процедуру ее использования (правила отнесения вновь поступающего объекта к одному из ранее выделенных классов). Другими словами, имеем естественную триаду: построение - изучение - использование классификации.
Как уже отмечалось, для построения системы диагностических классов используют разнообразные методы кластерного анализа и группировки объектов. Наименее известен второй член триады - изучение отношений эквивалентности, полученных в результате построения системы диагностических классов. Статистический анализ полученных, в частности экспертами, отношений эквивалентности - часть статистики бинарных отношений и тем самым - статистики объектов нечисловой природы. Помимо общих результатов этой области эконометрики и прикладной статистики, представляют интерес частные результаты, полученные специально для отношений эквивалентности (см. "Статистика нечисловых данных" ).
Диагностика в узком смысле слова (процедура использования классификации, т.е. отнесения вновь поступающего объекта к одному из выделенных ранее классов) - предмет дискриминантного анализа. Отметим, что с точки зрения статистики объектов нечисловой природы дискриминантный анализ является частным случаем общей схемы регрессионного анализа, соответствующим ситуации, когда зависимая переменная принимает конечное число значений, а именно - номера классов, а вместо квадрата разности стоит функция потерь от неправильной классификации. Однако есть ряд специфических постановок, выделяющих задачи диагностики среди всех регрессионных задач.
О построении диагностических правил. Начнем с обсуждения одного распространенного заблуждения. Иногда рекомендуют сначала построить систему диагностических классов, а потом в каждом диагностическом классе отдельно проводить регрессионный анализ (в классическом смысле) или применять иные методы многомерного статистического анализа. Однако обычно забывают, что при этом нельзя опираться на вероятностную модель многомерного нормального распределения, так как распределение результатов наблюдений, попавших в определенный кластер, будет отнюдь не нормальным, а усеченным нормальным (усечение определяется границами кластера).
Процедуры построения диагностических правил делятся на вероятностные и детерминированные. К первым относятся так называемые задачи расщепления смесей. В них предполагается, что распределение вновь поступающего случайного элемента является смесью вероятностных законов, соответствующих диагностическим классам. Как и при выборе степени полинома в регрессии (см. предыдущий пункт настоящей лекции), при анализе реальных социально-экономических данных встает вопрос об оценке числа элементов смеси, т.е. числа диагностических классов. Были изучены результаты применения обычно рекомендуемого критерия Уилкса для оценки числа элементов смеси. Оказалось (см. статью [8]), что оценка с помощью критерия Уилкса не является состоятельной, асимптотическое распределение этой оценки - геометрическое, как и в случае задачи восстановления зависимости в регрессионном анализе (см. выше). Итак, продемонстрирована несостоятельность обычно используемых оценок. Для получения состоятельных оценок достаточно связать уровень значимости в критерии Уилкса с объемом выборки, как это было предложено и для задач регрессии.
Как уже отмечалось, задачи построения системы диагностических классов целесообразно разбить на два типа: с четко разделенными кластерами (задачи кластер-анализа) и с условными границами, непрерывно переходящими друг в друга классами (задачи группировки). Такое деление полезно, хотя в обоих случаях могут применяться одинаковые алгоритмы. Сколько же существует алгоритмов построения системы диагностических правил? Иногда называют то или иное число. На самом же деле их бесконечно много, в чем нетрудно убедиться.
Действительно, рассмотрим один определенный алгоритм - алгоритм средней связи. Он основан на использовании некоторой меры близости 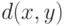 между объектами
между объектами  и
и  . Как он работает? На первом шаге каждый объект рассматривается как отдельный кластер. На каждом следующем шаге объединяются две ближайших кластера. Расстояние между объектами рассчитывается как средняя связь (отсюда и название алгоритма), т.е. как среднее арифметическое расстояний между парами объектов, один из которых входит в первый кластер, а другой - во второй. В конце концов все объекты объединяются вместе, и результат работы алгоритма представляет собой дерево последовательных объединений (в терминах теории графов), или "Дендрограмму". Из нее можно выделить кластеры разными способами. Один подход - исходя из заданного числа кластеров. Другой - из соображений предметной области. Третий - исходя из устойчивости (если разбиение долго не менялось при возрастании порога объединения - значит оно отражает реальность). И т.д.
. Как он работает? На первом шаге каждый объект рассматривается как отдельный кластер. На каждом следующем шаге объединяются две ближайших кластера. Расстояние между объектами рассчитывается как средняя связь (отсюда и название алгоритма), т.е. как среднее арифметическое расстояний между парами объектов, один из которых входит в первый кластер, а другой - во второй. В конце концов все объекты объединяются вместе, и результат работы алгоритма представляет собой дерево последовательных объединений (в терминах теории графов), или "Дендрограмму". Из нее можно выделить кластеры разными способами. Один подход - исходя из заданного числа кластеров. Другой - из соображений предметной области. Третий - исходя из устойчивости (если разбиение долго не менялось при возрастании порога объединения - значит оно отражает реальность). И т.д.
К алгоритму средней связи естественно сразу добавить алгоритм ближайшего соседа (когда расстоянием между кластерами называется минимальное из расстояний между парами объектов, один из которых входит в первый кластер, а другой - во второй) и алгоритм дальнего соседа (когда расстоянием между кластерами называется максимальное из расстояний между парами объектов, один из которых входит в первый кластер, а другой - во второй).
Каждый из трех описанных алгоритмов (средней связи, ближайшего соседа, дальнего соседа), как легко проверить, порождает бесконечное (континуальное) семейство алгоритмов кластер-анализа. Дело в том, что величина 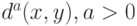 , также является мерой близости между
, также является мерой близости между 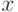 и
и  и порождает новый алгоритм. Если параметр а пробегает отрезок, то получается бесконечно много алгоритмов классификации.
и порождает новый алгоритм. Если параметр а пробегает отрезок, то получается бесконечно много алгоритмов классификации.
Каким из них пользоваться при обработке данных? Дело осложняется тем, что практически в любом пространстве данных мер близости различных видов существует весьма много. Именно в связи с обсуждаемой проблемой следует указать на принципиальное различие между кластер-анализом и задачами группировки.
Если классы реальны, естественны, существуют на самом деле, четко отделены друг от друга, то любой алгоритм кластер-анализа их выделит. Следовательно, в качестве критерия естественности классификации следует рассматривать устойчивость относительно выбора алгоритма кластер-анализа.
Проверить устойчивость можно, применив к данным несколько подходов, например, столь непохожие алгоритмы, как "ближнего соседа" и "дальнего соседа". Если полученные результаты содержательно близки, то они адекватны действительности. В противном случае следует предположить, что естественной классификации не существует, задача кластер-анализа не имеет решения, и можно проводить только группировку.
Как уже отмечалось, часто применяется т.н. агломеративный иерархический алгоритм "Дендрограмма", в котором вначале все элементы рассматриваются как отдельные кластеры, а затем на каждом шагу объединяются два наиболее близких кластера. Для работы "Дендрограммы" необходимо задать правило вычисления расстояния между кластерами. Оно вычисляется через расстояние 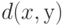 между элементами
между элементами  и . Поскольку
и . Поскольку 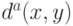 при
при 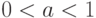 также расстояние, то, как правило, существует бесконечно много различных вариантов этого алгоритма. Представим себе, что они применяются для обработки одних и тех же реальных данных. Если при всех
также расстояние, то, как правило, существует бесконечно много различных вариантов этого алгоритма. Представим себе, что они применяются для обработки одних и тех же реальных данных. Если при всех  получается одинаковое разбиение элементов на кластеры, т.е. результат работы алгоритма устойчив по отношению к изменению (в смысле общей схемы устойчивости, рассмотренной в
"Проблемы устойчивости эконометрических процедур"
ниже), то имеем "естественную" классификацию. В противном случае результат зависит от субъективно выбранного исследователем параметра , т.е. задача кластер-анализа неразрешима (предполагаем, что выбор нельзя специально обосновать). Задача группировки в этой ситуации имеет много решений. Из них можно выбрать одно по дополнительным критериям.
получается одинаковое разбиение элементов на кластеры, т.е. результат работы алгоритма устойчив по отношению к изменению (в смысле общей схемы устойчивости, рассмотренной в
"Проблемы устойчивости эконометрических процедур"
ниже), то имеем "естественную" классификацию. В противном случае результат зависит от субъективно выбранного исследователем параметра , т.е. задача кластер-анализа неразрешима (предполагаем, что выбор нельзя специально обосновать). Задача группировки в этой ситуации имеет много решений. Из них можно выбрать одно по дополнительным критериям.
Следовательно, получаем эвристический критерий: если решение задачи кластер-анализа существует, то оно находится с помощью любого алгоритма. Целесообразно использовать наиболее простой.
Проблема поиска естественной классификации. Существуют различные точки зрения на эту проблему. На Всесоюзной школе-семинаре "Использование математических методов в задачах классификации" (г. Пущино, 1986 г.), в частности, были высказаны мнения, что естественная классификация:
- закон природы;
- основана на глубоких закономерностях, тогда как искусственная классификация - на неглубоких;
- для конкретного индивида та, которая наиболее быстро вытекает из его тезауруса;
- удовлетворяет многим целям; цель искусственной классификации задает человек;
- классификация с точки зрения потребителя продукции;
- классификация, позволяющая делать прогнозы;
- имеет критерием устойчивость.
Михаил Агапитов
Подобед Александр
|
Я нажал кнопку "начать курс" и почти его уже закончил, но для получения диплома на бумаге, нужно его же оплатить? Как оплатить? |