Параллельное программирование с использованием OpenMP
При использовании многопроцессорных вычислительных систем с общей памятью обычно предполагается, что имеющиеся в составе системы процессоры обладают равной производительностью, являются равноправными при доступе к общей памяти, и время доступа к памяти является одинаковым (при одновременном доступе нескольких процессоров к одному и тому же элементу памяти очередность и синхронизация доступа обеспечивается на аппаратном уровне). Многопроцессорные системы подобного типа обычно именуются симметричными мультипроцессорами ( symmetric multiprocessors, SMP ).
Перечисленному выше набору предположений удовлетворяют также активно развиваемые в последнее время многоядерные процессоры, в которых каждое ядро представляет практически независимо функционирующее вычислительное устройство. Для общности излагаемого учебного материала для упоминания одновременно и мультипроцессоров и многоядерных процессоров для обозначения одного вычислительного устройства (одноядерного процессора или одного процессорного ядра) будет использоваться понятие вычислительного элемента ( ВЭ ).
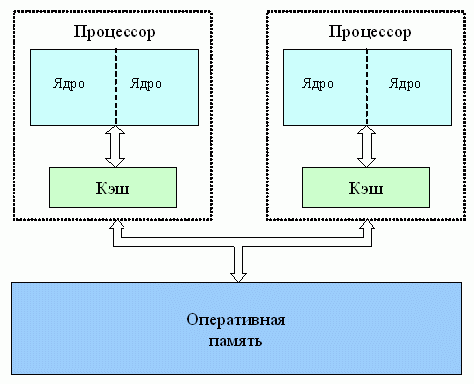
Рис. 7.1. Архитектура многопроцессорных систем с общей (разделяемой) с однородным доступом памятью (для примера каждый процессор имеет два вычислительных ядра)
Следует отметить, что общий доступ к данным может быть обеспечен и при физически распределенной памяти (при этом, естественно, длительность доступа уже не будет одинаковой для всех элементов памяти). Такой подход именуется как неоднородный доступ к памяти ( non-uniform memory access or NUMA ).
В самом общем виде системы с общей памятью могут быть представлены в виде модели параллельного компьютера с произвольным доступом к памяти ( parallel random-access machine - PRAM ) см., например, Andrews (2000).
Обычный подход при организации вычислений для многопроцессорных вычислительных систем с общей памятью - создание новых параллельных методов на основе обычных последовательных программ, в которых или автоматически компилятором, или непосредственно программистом выделяются участки независимых друг от друга вычислений. Возможности автоматического анализа программ для порождения параллельных вычислений достаточно ограничены, и второй подход является преобладающим. При этом для разработки параллельных программ могут применяться как новые алгоритмические языки, ориентированные на параллельное программирование, так и уже имеющиеся языки программирования, расширенные некоторым набором операторов для параллельных вычислений.
Широко используемый подход состоит и в применении тех или иных библиотек, обеспечивающих определенный программный интерфейс ( application programming interface, API ) для разработки параллельных программ. В рамках такого подхода наиболее известны Windows Thread API (см., например, Вильямс (2001)) и PThead API (см., например, Butenhof (1997)). Однако первый способ применим только для ОС семейства Microsoft Windows, а второй вариант API является достаточно трудоемким для использования и имеет низкоуровневый характер.
Все перечисленные выше подходы приводят к необходимости существенной переработки существующего программного обеспечения, и это в значительной степени затрудняет широкое распространение параллельных вычислений. Как результат, в последнее время активно развивается еще один подход к разработке параллельных программ, когда указания программиста по организации параллельных вычислений добавляются в программу при помощи тех или иных внеязыковых средств языка программирования - например, в виде директив или комментариев, которые обрабатываются специальным препроцессором до начала компиляции программы. При этом исходный текст программы остается неизменным, и по нему, в случае отсутствия препроцессора, компилятор построит исходный последовательный программный код. Препроцессор же, будучи примененным, заменяет директивы параллелизма на некоторый дополнительный программный код (как правило, в виде обращений к процедурам какой-либо параллельной библиотеки).
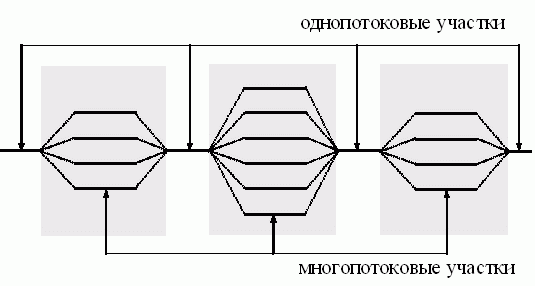
Рассмотренный выше подход является основой технологии OpenMP (см., например, Chandra et al. (2000)), наиболее широко применяемой в настоящее время для организации параллельных вычислений на многопроцессорных системах с общей памятью. В рамках данной технологии директивы параллелизма используются для выделения в программе параллельных фрагментов, в которых последовательный исполняемый код может быть разделен на несколько раздельных командных потоков ( threads ). Далее эти потоки могут исполняться на разных процессорах (процессорных ядрах) вычислительной системы. В результате такого подхода программа представляется в виде набора последовательных ( однопотоковых ) и параллельных ( многопотоковых ) участков программного кода (см. рис. 7.2). Подобный принцип организации параллелизма получил наименование " вилочного " ( fork-join ) или пульсирующего параллелизма. Более полная информация по технологии OpenMP может быть получена в литературе (см., например, Chandra et al. (2000), Roosta (2000)) или в информационных ресурсах сети Интернет.
При разработке технологии OpenMP был учтен накопленный опыт по разработке параллельных программ для систем с общей памятью. Опираясь на стандарт X3Y5 (см. Chandra et al. (2000)) и учитывая возможности PThreads API (см. Butenhof (1997)), в технологии OpenMP в значительной степени упрощена форма записи директив и добавлены новые функциональные возможности. Для привлечения к разработке OpenMP самых опытных специалистов и для стандартизации подхода на самых ранних этапах выполнения работ был сформирован Международный комитет по OpenMP ( the OpenMP Architectural Review Board, ARB ). Первый стандарт, определяющий технологию OpenMP применительно к языку Fortran, был принят в 1997 г., для алгоритмического языка C - в 1998 г. Последняя версия стандарта OpenMP для языков C и Fortran была опубликована в 2005 г. (см. www.openmp.org).
Далее в разделе будет приведено последовательное описание возможностей технологии OpenMP. Здесь же, еще не приступая к изучению, приведем ряд важных положительных моментов этой технологии:
- Технология OpenMP позволяет в максимальной степени эффективно реализовать возможности многопроцессорных вычислительных систем с общей памятью, обеспечивая использование общих данных для параллельно выполняемых потоков без каких-либо трудоемких межпроцессорных передач сообщений.
- Сложность разработки параллельной программы с использованием технологии OpenMP в значительной степени согласуется со сложностью решаемой задачи - распараллеливание сравнительно простых последовательных программ, как правило, не требует больших усилий (порою достаточно включить в последовательную программу всего лишь несколько директив OpenMP )1Сразу хотим предупредить, чтобы простота применения OpenMP для первых простых программ не должна приводить в заблуждение - при разработке сложных алгоритмов и программ требуется соответствующий уровень усилий и для организации параллельности - см. раздел 12 настоящего учебного курса ; это позволяет, в частности, разрабатывать параллельные программы и прикладным разработчикам, не имеющим большого опыта в параллельном программировании.
- Технология OpenMP обеспечивает возможность поэтапной ( инкрементной ) разработки параллельных программы - директивы OpenMP могут добавляться в последовательную программу постепенно (поэтапно), позволяя уже на ранних этапах разработки получать параллельные программы, готовые к применению; при этом важно отметить, что программный код получаемых последовательного и параллельного вариантов программы является единым и это в значительной степени упрощает проблему сопровождения, развития и совершенствования программ.
- OpenMP позволяет в значительной степени снизить остроту проблемы переносимости параллельных программ между разными компьютерными системами - параллельная программа, разработанная на алгоритмическом языке C или Fortran с использованием технологии OpenMP, как правило, будет работать для разных вычислительных систем с общей памятью.
7.1. Основы технологии OpenMP
Перед началом практического изучения технологии OpenMP рассмотрим ряд основных понятий и определений, являющихся основополагающими для данной технологии.
7.1.1. Понятие параллельной программы
Под параллельной программой в рамках OpenMP понимается программа, для которой в специально указываемых при помощи директив местах - параллельных фрагментах - исполняемый программный код может быть разделен на несколько раздельных командных потоков ( threads ). В общем виде программа представляется в виде набора последовательных ( однопотоковых ) и параллельных ( многопотоковых ) участков программного кода (см. рис. 7.2).
Важно отметить, что разделение вычислений между потоками осуществляется под управлением соответствующих директив OpenMP. Равномерное распределение вычислительной нагрузки - балансировка ( load balancing ) - имеет принципиальное значение для получения максимально возможного ускорения выполнения параллельной программы.
Потоки могут выполняться на разных процессорах (процессорных ядрах) либо могут группироваться для исполнения на одном вычислительном элементе (в этом случае их исполнение осуществляется в режиме разделения времени). В предельном случае для выполнения параллельной программы может использоваться один процессор - как правило, такой способ применяется для начальной проверки правильности параллельной программы.
Количество потоков определяется в начале выполнения параллельных фрагментов программы и обычно совпадает с количеством имеющихся вычислительных элементов в системе; изменение количества создаваемых потоков может быть выполнено при помощи целого ряда средств OpenMP. Все потоки в параллельных фрагментах программы последовательно перенумерованы от 0 до np-1, где np есть общее количество потоков. Номер потока также может быть получен при помощи функции OpenMP.
Использование в технологии OpenMP потоков для организации параллелизма позволяет учесть преимущества многопроцессорных вычислительных систем с общей памятью. Прежде всего, потоки одной и той же параллельной программы выполняются в общем адресном пространстве, что обеспечивает возможность использования общих данных для параллельно выполняемых потоков без каких-либо трудоемких межпроцессорных передач сообщений (в отличие от процессов в технологии MPI для систем с распределенной памятью). И, кроме того, управление потоками (создание, приостановка, активизация, завершение) требует меньше накладных расходов для ОС по сравнению с процессами.
7.1.2. Организация взаимодействия параллельных потоков
Как уже отмечалось ранее, потоки исполняются в общем адресном пространстве параллельной программы. Как результат, взаимодействие параллельных потоков можно организовать через использование общих данных, являющихся доступными для всех потоков. Наиболее простая ситуация состоит в использовании общих данных только для чтения. В случае же, когда общие данные могут изменяться несколькими потоками, необходимы специальные усилия для организации правильного взаимодействия. На самом деле, пусть два потока исполняют один и тот же программный код
n=n+1;
для общей переменной n. Тогда в зависимости от условий выполнения данная операция может быть выполнена поочередно (что приведет к получению правильного результата) или же оба потока могут одновременно прочитать значение переменной n, одновременно увеличить и записать в эту переменную новое значение (как результат, будет получено неправильное значение). Подобная ситуация, когда результат вычислений зависит от темпа выполнения потоков, получил наименование гонки потоков ( race conditions ). Для исключения гонки необходимо обеспечить, чтобы изменение значений общих переменных осуществлялось в каждый момент времени только одним единственным потоком - иными словами необходимо обеспечить взаимное исключение ( mutual exclusion ) потоков при работе с общими данными. В OpenMP взаимоисключение может быть организовано при помощи неделимых ( atomic ) операций, механизма кри тических секций ( critical sections ) или специального типа семафоров - замков ( locks ).
Следует отметить, что организация взаимного исключения приводит к уменьшению возможности параллельного выполнения потоков - при одновременном доступе к общим переменным только один из них может продолжить работу, все остальные потоки будут блокированы и будут ожидать освобождения общих данных. Можно сказать, что именно при реализации взаимодействия потоков проявляется искусство параллельного программирования для вычислительных систем с общей памятью - организация взаимного исключения при работе с общими данными является обязательной, но возникающие при этом задержки (блокировки) потоков должны быть минимальными по времени.
Помимо взаимоисключения, при параллельном выполнении программы во многих случаях является необходимым та или иная синхронизация ( synchronization ) вычислений, выполняемых в разных потоках: например, обработка данных, выполняемая в одном потоке, может быть начата только после того, как эти данные будут сформированы в другом потоке (классическая задача параллельного программирования " производитель-потребитель " - "producer-consumer" problem ). В OpenMP синхронизация может быть обеспечена при помощи замков или директивы barrier.
7.1.3. Структура OpenMP
Конструктивно в составе технологии OpenMP можно выделить:
- Директивы,
- Библиотеку функций,
- Набор переменных окружения.
Именно в таком порядке и будут рассмотрены возможности технологии OpenMP.
7.1.4. Формат директив OpenMP
Стандарт предусматривает использование OpenMP для алгоритмических языков C90, C99, C++, Fortran 77, Fortran 90 и Fortran 95. Далее описание формата директив OpenMP и все приводимые примеры программ будут представлены на алгоритмическом языке C; особенности использования технологии OpenMP для алгоритмического языка Fortran будут даны в п. 7.8.1.
В самом общем виде формат директив OpenMP может быть представлен в следующем виде:
#pragma omp <имя_директивы> [<параметр>[[,] <параметр>]…]
Начальная часть директивы (#pragma omp) является фиксированной, вид директивы определяется ее именем (имя_директивы), каждая директива может сопровождаться произвольным количеством параметров (на английском языке для параметров директивы OpenMP используется термин clause ).
Для иллюстрации приведем пример директивы:
#pragma omp parallel default(shared) \
private(beta,pi)Пример показывает также, что для задания директивы может быть использовано несколько строк программы - признаком наличия продолжения является знак обратного слеша "\".
Действие директивы распространяется, как правило, на следующий в программе оператор, который может быть, в том числе, и структурированным блоком.