|
Вопрос по Курсу: "Параллельное программирование с использованием MS VisualStudia 2010". При компиляции Самостоятельного задания (одновременная отрисовка прямоугольников, эллипсов и выдача в текст-бокс случайного числа) среда предупреждает: suspend - устаревшая команда; примените monitor, mutex и т.п. Создаётся впечатление, что Задание создано в более поздней среде, чем VS 2010. |
Томский политехнический университет
Опубликован: 23.01.2013 | Доступ: свободный | Студентов: 1165 / 197 | Длительность: 12:09:00
Тема: Программирование
Специальности: Программист, Архитектор программного обеспечения
Лекция 1:
Введение в параллельное программирование
Лекция 1 || Лекция 2 >
Аннотация: В рамках данной лекции будут рассмотрены следующие вопросы: определение, назначение параллельного программирования; многоядерные вычисления; множественные потоки команд/данных; ускорение; закон Амадал; закон Густафсона-Барсиса.
Ключевые слова: программирование, параллельные вычисления, параллельное программирование, multithreading, ПО, производительность, SISD, MISD, SIMD, MIMD, отношение, время выполнения, расходы, алгоритм, программа, объём, ввод/вывод, менеджмент
Определение, назначение параллельного программирования
Существуют различные способы написания программ, которые условно можно разделить на три группы:
- Последовательное программирование с дальнейшим автоматическим распараллеливанием.
- Непосредственное формирование потоков параллельного управления, с учетом особенностей архитектур параллельных вычислительных систем или операционных систем.
- Описание параллелизма без использования явного управления обеспечивается заданием только информационных связей. Предполагается, что программа будет выполняться на вычислительных системах с бесконечными ресурсами, операторы будут запускаться немедленно по готовности их исходных данных.
Каждый из перечисленных подходов обладает своими достоинствами и недостатками параллельное программирование.
Параллельные вычисления - способ организации компьютерных вычислений, при котором программы разрабатываются, как набор взаимодействующих вычислительных процессов, работающих асинхронно и при этом одновременно.
Параллельное программирование - это техника программирования, которая использует преимущества многоядерных или многопроцессорных компьютеров и является подмножеством более широкого понятия многопоточности (multithreading).
Многоядерные вычисления
Использование параллельного программирования становится наиболее необходимым, поскольку позволяет максимально эффективно использовать возможности многоядерных процессоров и многопроцессорных систем. По ряду причин, включая повышение потребления энергии и ограничения пропускной способности памяти, увеличивать тактовую частоту современных процессоров стало невозможно. Вместо этого производители процессоров стали увеличивать их производительность за счет размещения в одном чипе нескольких вычислительных ядер, не меняя или даже снижая тактовую частоту. Поэтому для увеличения скорости работы приложений теперь следует по-новому подходить к организации кода, а именно - оптимизировать программы под многоядерные системы.
Множественные потоки команд/данных (Классификация М.Флинна)
Самой ранней и наиболее известной является классификация архитектур вычислительных систем, предложенная в 1966 году М.Флинном. Классификация базируется на понятии потока, под которым понимается последовательность элементов, команд или данных, обрабатываемая процессором. На основе числа потоков команд и потоков данных Флинн выделяет четыре класса архитектур: SISD, MISD, SIMD, MIMD. Описание классов приведено в Табл. 1.1.
| Название класса | Описание класса |
|---|---|
| SISD (single instructiоn streаm / single dаtа streаm) или ОКОД (Одиночный поток Команд, Одиночный поток Данных) | Одиночный поток команд и одиночный поток данных (исполнение одним процессором одного потока команд, обрабатывающего данные, хранящиеся в одной памяти). К этому классу относятся, классические последовательные машины, или иначе, машины фон-неймановского типа (PDP-11 или VАX 11/780). |
| SIMD (single instructiоn streаm / multiple dаtа streаm) или ОКМД (одиночный поток команд, множественный поток данных) | Одиночный поток команд и множественный поток данных. В архитектурах подобного рода сохраняется один поток команд, включающий, в отличие от предыдущего класса (SISD), векторные команды, что позволяет выполнять одну арифметическую операцию сразу над многими данными - элементами вектора. |
| MISD (multiple instructiоn streаm / single dаtа streаm) или МКОД (Множественный поток Команд, Одиночный поток Данных) | Множественный поток команд и одиночный поток данных. Определение подразумевает наличие в архитектуре многих процессоров, обрабатывающих один и тот же поток данных. |
| MIMD (multiple instructiоn streаm / multiple dаtа streаm) или МКМД (Множественный поток Команд, Множественный поток Данных) | Множественный поток команд и множественный поток данных. Этот класс предполагает, что в вычислительной системе есть несколько устройств обработки команд, объединенных в единый комплекс и работающих каждое со своим потоком команд и данных. |
На основании Табл. 1.1 можно проранжировать архитектуры на однопоточность/многопоточность (Табл. 1.2).
| Одиночный поток команд (Single Instructiоn) | Множество потоков команд (Multiple Instructiоn) | |
|---|---|---|
| Одиночный поток данных (Single Dаtа) | SISD (ОКОД) | MISD (МКОД) |
| Множество потоков данных (Multiple Dаtа) | SIMD (ОКМД) | MIMD (МКМД) |
Ускорение (Speedup)
Ускорением параллельного алгоритма называется отношение:
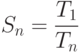
где 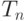 - время вычисления задачи на n процессорах,
- время вычисления задачи на n процессорах, 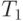 - время выполнения однопоточной программы
- время выполнения однопоточной программы
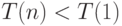 , если параллельная версия алгоритма эффективна.
, если параллельная версия алгоритма эффективна.
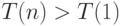 , если накладные расходы (издержки) реализации параллельной версии алгоритма чрезмерно велики.
, если накладные расходы (издержки) реализации параллельной версии алгоритма чрезмерно велики.
С ускорением связана эффективность параллельного алгоритма. Эффективностью параллельного алгоритма называется величина:

По определению, 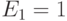 . Теоретически должно быть
. Теоретически должно быть  и
и 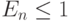 . Если алгоритм достигает максимального ускорения
. Если алгоритм достигает максимального ускорения  , то
, то  . На практике эффективность убывает при увеличении числа процессоров.
. На практике эффективность убывает при увеличении числа процессоров.
Если же результат получается  (суперлинейное ускорение). Эта аномалия вызвана, чаще всего, двумя причинами:
(суперлинейное ускорение). Эта аномалия вызвана, чаще всего, двумя причинами:
- В качестве последовательного алгоритма был применён не самый быстрый алгоритм из существующих.
- С увеличением количества вычислителей растёт суммарный объём их оперативной и кэш памяти. Поэтому всё большая часть данных задачи умещается в оперативной памяти и не требует подкачки с диска, или (чаще всего) умещается в кэше.
Закон Амдала
Закон Амдала (1967 год), описывает максимальный теоретический выигрыш в производительности параллельного решения по отношению к лучшему последовательному решению. Закон Амдала описывается следующей математической формулой:
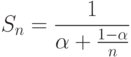
где 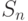 - во сколько раз можно ускорить вычисления (ускорение), n - количество процессоров (ядер),
- во сколько раз можно ускорить вычисления (ускорение), n - количество процессоров (ядер),  - доля последовательно вычисляемого кода (
- доля последовательно вычисляемого кода ( ).
).
Закон Амдаля, несмотря на то, что он не учитывает многих факторов, накладывает ограничения на максимально достижимую эффективность параллельного алгоритма.
Предположим, например, что 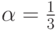 , то есть две трети операций в алгоритме могут выполняться параллельно, а треть - нет. Тогда ускоре-ние
, то есть две трети операций в алгоритме могут выполняться параллельно, а треть - нет. Тогда ускоре-ние 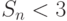 . Таким образом, независимо от количества процессоров (ядер) и даже при игнорировании всех затрат на подготовку данных нельзя ускорить решение задачи более, чем в три раза.
. Таким образом, независимо от количества процессоров (ядер) и даже при игнорировании всех затрат на подготовку данных нельзя ускорить решение задачи более, чем в три раза.
Закон Густафсона-Барсиса
Закон Густафсона - Барсиса (1988г) оценивает максимально допустимое ускорение выполнения параллельной программы, в зависимости от количества одновременно выполняемых потоков вычислений и доли последовательных расчётов. Формула Густафсона - Барсиса выглядит следующим образом:
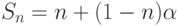
Где - доля последовательных расчётов в программе,  - количество процессоров.
- количество процессоров.
Густафсон заметил, что, работая на многопроцессорных системах, пользователи склонны к изменению тактики решения задачи. Теперь снижение общего времени исполнения программы уступает объёму решаемой задачи. Такое изменение цели обусловливает переход от закона Амдала к закону Густафсона. К примеру, на 100 процессорах программа выполняется 20 минут. При переходе на систему с 1000 процессорами можно достичь времени исполнения порядка двух минут. Однако для получения большей точности решения имеет смысл увеличить объём решаемой задачи, т.е. при сохранении общего времени исполнения пользователи стремятся получить более точный результат. Увеличение объёма решаемой задачи приводит к увеличению доли параллельной части, так как последовательная часть (ввод/вывод, менеджмент потоков, точки синхронизации и т.п.) не изменяется.
Лекция 1 || Лекция 2 >
Владимир Каширин