|
Прошу вас уточнить по курсу ITIL. IT Service Management по стандартам V.3.1 вопрос о количестве версий ITIL. |
Инспектор
Вы можете этот курс.
Опубликован: 17.05.2012 | Доступ: платный | Студентов: 640 / 133 | Оценка: 4.29 / 4.17 | Длительность: 17:00:00
Тема: Менеджмент
Специальности: Администратор информационных систем, Менеджер, Руководитель, Экономист
Лекция 13:
Управление запросами, доступом и проблемами в рамках Эксплуатации услуг
Аннотация: Процессы и деятельности в рамках этапа Эксплуатации услуг: цель, входы и выходы, основные деятельности и ключевые показатели эффективности. В лекции рассматриваются следующие процессы: Управление запросами на обслуживание, Управление проблемами и Управление доступом. В лекции также рассматриваются связи процессов Эксплуатации с другими процессами в рамках жизненного цикла услуг.
Ключевые слова: значение, процесс управления, доступ, исполнение, контроль, процесс исполнения, запрос, ITIL, минимизация, запись, жизненный цикл, категорирование, определение, диагностика, поиск, CMS, диаграмма, поддержание работоспособности, база данных, управление доступом, конфиденциальность, целостность, активы
13.1. Управление запросами на обслуживание
Управление запросами на обслуживание (Request Fulfillment) - процесс, ответственный за управление жизненным циклом всех запросов на обслуживание [1].
Под запросами на обслуживание понимается множество запросов пользователей к IT-департаменту. Большинство из них имеют низкий риск, приоритет, значение для бизнеса и т.п. Именно поэтому их рассмотрение необходимо выделить в отдельный процесс, дабы уменьшить нагрузку на такие процессы как Управление инцидентами и Управление изменениями. К ним относятся, в частности, запросы на смену пароля или запросы на установку программного обеспечения.
Основные цели процесса Управления запросами на обслуживание:
- предоставить канал, по которому пользователи смогут направлять запросы и получать стандартные услуги по обслуживанию;
- предоставить пользователям и заказчикам информацию о доступности услуг и процедуры для получения доступа к ним;
- предоставлять компоненты для стандартных услуг (например, лицензии для программного обеспечения).
Процесс Управления запросами на обслуживание предоставляет ценность для бизнеса тем, что поддерживает быстрый и эффективный доступ к услугам, которые персонал бизнеса может использовать для увеличения продуктивности своей работы или качества услуг и продуктов бизнеса. Централизованное исполнение запросов также позволяет увеличить контроль за услугами и их компонентами.
Процесс исполнения запроса зависит от того, какой именно запрос, но тем не менее, можно выделить ряд стандартных деятельностей, которые должны быть осуществлены. При этом многие запросы периодически повторяются, поэтому можно выделить стандартную модель для их исполнения. Модель исполнения запросов включает в себя шаги по исполнению запроса, группы или отдельные люди, вовлеченные в решение, временные границы и пути эскалации.
Для размещения запросов на обслуживание ITIL рекомендует разработать веб-форму. В ней необходимо предусмотреть возможность для пользователей ввести детальную и структурированную информацию о запросе из заранее определенного перечня значений. Это позволит быстро назначить запрос в команду поддержки, а иногда и автоматизировать его.
Ответственность за формальное закрытие запроса на обслуживание чаще всего лежит на сервис-деске.
Метриками эффективности процесса Управления запросами на обслуживание могут быть:
- общее количество запросов на обслуживание;
- количество запросов, находящихся на разных стадиях жизненного цикла - закрыт, в работе, назначен в команду и т.п.
- количество запросов, ждущих исполнения;
- среднее время исполнения запросов определенных типов;
- количество запросов, исполненных в согласованные время исполнения запросов;
- средние затраты на исполнение запросов определенных типов;
- уровень удовлетворенности пользователей.
13.2. Управление проблемами
Управление проблемами (Problem Management) - процесс, отвечающий за управление жизненным циклом всех проблем. Ключевыми целями Управления проблемами являются предотвращение инцидентов и минимизация влияния тех инцидентов, которые не могут быть предотвращены.
Проблема (Problem) - причина одного или нескольких инцидентов[1].
Процесс Управления проблемами предназначен для диагностирования первопричин возникновения инцидентов и поиска решений по их устранению. Он также контролирует то, что решение проблем будет осуществлено в рамках соответствующих процессов, в частности, Управления изменениями и Управления релизами.
Процесс Управления проблемами тесно связан с процессом Управления инцидентами, так как возникновение инцидентов происходит вследствие наличия проблем. Эти процессы часто используют одни инструменты, системы категорирования и расстановки приоритетов и т.п.
Также как и процессы Управления инцидентами и Управления изменениями, Управление проблемами предоставляет ценность для бизнеса тем, что повышает доступность и качество услуг. Если проблема, порождающая инцидент, решена, бизнес выиграет от уменьшения времени простоя услуг и уменьшения негативного влияния на бизнес-системы. Управление проблемами также уменьшает издержки бизнеса на разрешение инцидентов, так как непосредственно уменьшает их количество.
Управление проблемами состоит из двух подпроцессов:
- реактивное управление проблемами, которое осуществляется в рамках Эксплуатации услуг
- проактивное управление проблемами, которое инициализируется на этапе Эксплуатации услуг, но осуществляется в рамках Непрерывного улучшения услуг, следовательно, не рассматривается в этой лекции.
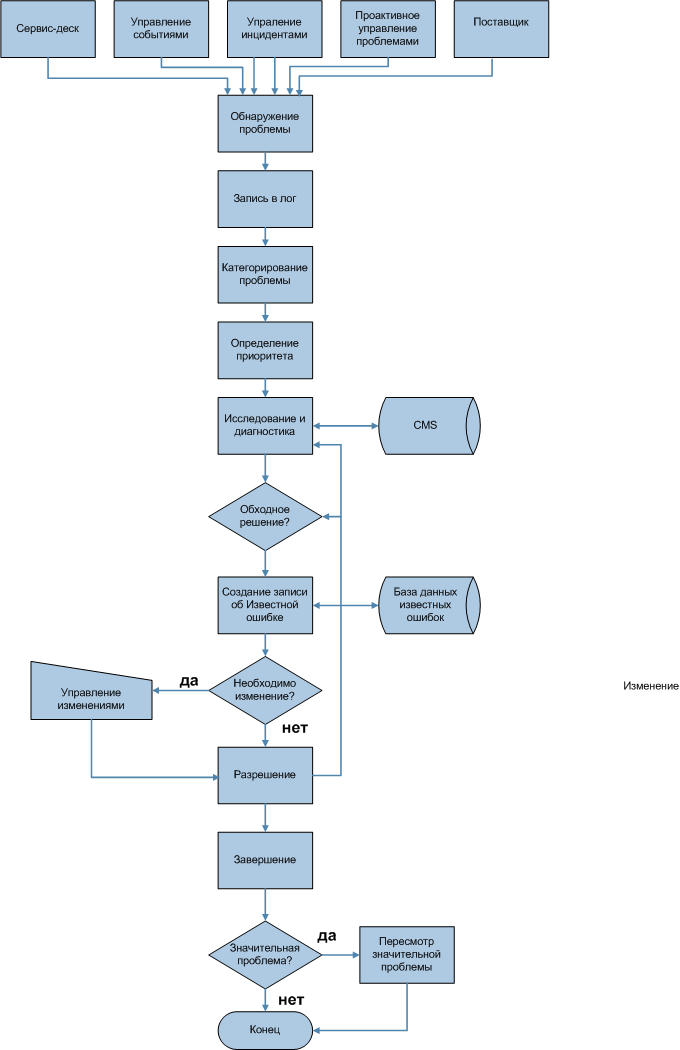
Реактивный процесс управления проблемами изображен на рис. 13.1
Рассмотрим основные этапы Реактивного управления проблемами.
Первый этап - обнаружение проблемы. Существует множество путей обнаружения проблем, в частности:
- обнаружение или "подозрение" причины возникновения одного или более инцидентов от сервис-деска. Сервис-деск может разрешить инцидент, но не выявить его первопричину, что увеличивает вероятность возникновения аналогичных инцидентов в дальнейшем. В этом случае формируется запись о проблеме для поиска основной причины инцидента;
- анализ инцидента технической группой поддержки, в результате которого будет выявлено существование проблемы или вероятность ее существования;
- автоматическое обнаружение сбоев приложений или компонентов инфраструктуры, которое выявит необходимость создания записи о проблеме;
- уведомление о существовании проблемы от поставщика или подрядчика;
- анализ инцидентов как часть проактивного управления инцидентами[17].
После обнаружения проблемы, информацию о ней необходимо занести в лог, то есть сформировать запись о проблеме. Запись о проблеме должна отражать детальное описание проблемы и весь ее жизненный цикл, в частности:
- информация о пользователе;
- информация об услуге;
- информация об оборудовании;
- время и дата начала формирования записи;
- описание инцидента, который стал результатом существования проблемы;
- детальное описание всех деятельностей в рамках решения проблемы.
Категорирование проблем аналогично рассмотренному нами выше категорированию инцидентов. Определение приоритета проблемы также схоже с аналогичным этапом Управления инцидентами за исключением того, что при определении приоритета проблемы необходимо учитывать частоту и влияние инцидентов, которые она порождает.
Для определения приоритета проблемы необходимо также оценить ее "тяжесть" или то, насколько она серьезна для инфраструктуры:
- систему можно восстановить или она должна быть заменена?
- сколько это будет стоить?
- сколько людей и какой квалификации необходимо для решения проблемы?
- сколько времени займет решение проблемы?
- насколько велик охват проблемы? ( например, сколько конфигурационных единиц она затрагивает)
На следующем этапе проводятся исследование и диагностика проблемы. Целью исследования является поиск первопричины проблемы. Для оценки точки сбоя и определения уровня негативного влияния может использоваться CMS. База известных ошибок может быть использована для поиска случаев возникновения проблемы в прошлом, и, возможно, ее решения.
Иногда полезным может быть попытка воссоздания сбоя в тестовой среде для выяснения его причины и поиска наиболее эффективного пути ее устранения. Существует множество стандартных техник для анализа, диагностики и решения проблем. Приведем техники, рассматриваемые в публикации ITIL:
- хронологический анализ. Когда возникает сложная проблема, могут появиться противоречивые отчеты и сообщения относительно того, что действительно случилось. Для восстановления картины документально фиксируют хронологию всех событий, связанных с проблемой. Это помогает также выяснить зависимости и устранить из цепочки события, которые не относятся к рассматриваемой проблеме.
- Анализ потерь (Pain Value Analysis) - методика, используемая для идентификации влияния на бизнес одной или нескольких проблем. Формула расчета потерь основана на количестве затронутых пользователей, продолжительности простоя, влияния на каждого пользователя, и стоимости для бизнеса (если известно).
- Анализ Кепнера и Трего - системный подход к разрешению проблем. Проблема анализируется в терминах Что, Где, Когда и Сколько. Определяются возможные причины. Наиболее вероятная причина подвергается проверке. Таким образом определяется истинная причина.
- "Мозговой штурм" - методика, которая помогает команде генерировать идеи. При этом идеи не должны критиковаться и анализироваться во время проведения самого Мозгового штурма, это происходит после.
- Диаграмма Ишикавы - методика, помогающая команде определить все возможные причины проблемы. Первоначально была разработана Каору Ишикавой (Kaoru Ishikawa), результатом работы этой методики является диаграмма[1]. Основная проблема изображается в виде ствола диаграммы, главные факторы - как ветки, вторичные факторы - как соплодие и т.д. Создание диаграммы стимулирует обсуждение проблемы и более глубокое понимание ее сложности.
-
анализ Парето - методика отделения значимых причин возникновения проблемы от незначимых. Должны быть предприняты следующие действия:
- сформировать таблицу, содержащую причины проблемы и их частоту в процентном соотношении от общего количества случаев возникновения проблемы;
- упорядочить строки таблицы в порядке увеличения важности причин;
- добавить столбец совокупного процента.
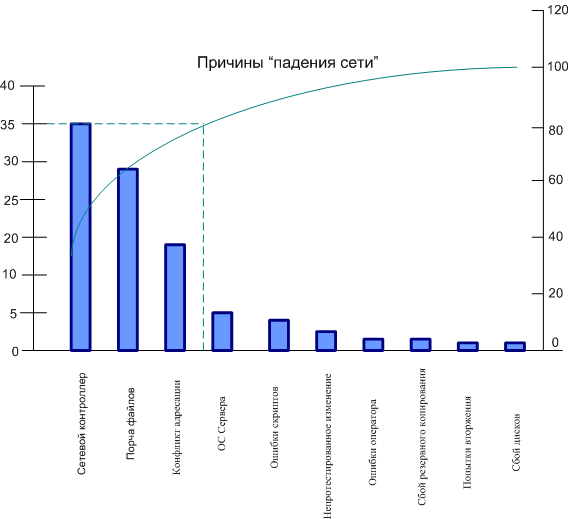
Более понятным анализ Парето будет на примере из публикации ITIL. В табл. 13.1 приведены 10 причин отказа сетевых взаимодействий, то есть "падения сети".
Таблица 13.1. "Падение сети" Причины Процент от общего количества (%) Расчет Совокупный процент (%) Сетевой контроллер 35 0+35 35 Порча файлов 26 35+26 61 Конфликт адресации 19 61+19 80 ОС Сервера 6 80+6 86 Ошибки скриптов 5 86+5 91 Непротестированное изменение 3 91+3 94 Ошибки оператора 2 94+2 96 Сбой резервного копирования 2 96+2 98 Попытки вторжения 1 98+1 99 Сбой дисков 1 99+1 100 Далее необходимо сделать следующие шаги:
- создать столбиковую диаграмму причин, расположенных в соответствии с их Процентом от общего количества ( 2 столбец);
- наложить линию суммарного процента (4 столбец).
- нарисовать линию от 80 % совокупного процента к оси y, параллельно оси x. В точке пересечения с линией суммарного процента "уронить" ее на ось x. Точка оси x, на которую "упадет" линия отделит значимые причины от незначимых.
Диаграмма рассматриваемого примера изображена на рис. 13.2.
Следующий этап - поиск обходного решения. Обходное решение (Workaround) - уменьшение или устранение влияния инцидента или проблемы, для которых в текущий момент недоступно полное разрешение[1]. Например, перезапуск отказавшей конфигурационной единицы или ручное добавление поврежденного файла из резервной копии. Обходные решения являются временными решениями для поддержания работоспособности системы на время поиска решения проблемы. Обходные решения документируются в Базе известных ошибок. База известных ошибок (Known Error Database или KEDB) - база данных, содержащая все записи об известных ошибках. Эта база данных создается в процессе Управления проблемами и используется процессами Управления инцидентами и проблемами. База известных ошибок это часть Системы управления знаний по услугам (SKMS) [1].
Как только найдено решение проблемы, его необходимо как можно быстрее реализовать. Тем не менее, важно помнить, что внесение изменений может затронуть другие услуги или конфигурационные единицы. Если необходимо какое-то функциональное изменение, прежде чем его осуществить, надо сформировать Запрос на изменение, который будет обработан в рамках процесса Управления изменениями. После того, как все необходимые действия предприняты, проблема устранена, происходит закрытие записи о проблеме, а также всех связанных с ней записей об инцидентах. Перед закрытием необходимо провести проверку (пересмотр) полноты записи о проблеме - она должна содержать детальное описание всех осуществленных процедур и действий. Для значительных проблем, которые считаются таковыми в соответствии с системой приоритетов конкретной организации, проверка должна быть более детальной, в частности рассматривать такие вопросы как:
- что сделано правильно в отношении проблемы;
- что сделано неправильно в отношении проблемы;
- что может быть сделано лучше в будущем;
- как предотвратить повторение проблемы;
- были ли задействованы третьи стороны.
На практике редко встречаются приложения, системы и релизы программного обеспечения, не имеющие ошибок. В идеальном случае все они обнаруживаются на этапе тестирования. Тем не менее, ошибки могут не проявится или быть незамеченными и , таким образом, "просочиться" на этап эксплуатации.
Для оценки эффективности процесса Управления проблемами можно использовать следующие метрики:
- общее количество проблем, зафиксированных в определенный период;
- процент проблем, решенных в рамках, установленных SLA;
- количество проблем, решение которых вышло за рамки согласованных целевых показателей времени для решения проблем;
- количество нерешенных проблем;
- среднее время решения проблемы;
- количество значительных проблем;
- количество успешно завершенных пересмотров значительных проблем;
- количество известных ошибок, добавленных в Базу известных ошибок.
Александр Колотов